International Journal of Innovative Research in Science, Engineering and Technology
ISSN ONLINE(2319-8753)PRINT(2347-6710)
ISSN ONLINE(2319-8753)PRINT(2347-6710)
P.Thangalakshmi, S. Kamalesh
|
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Innovative Research in Science, Engineering and Technology
This project is Service-Oriented Computing (SOC) is rising as a paradigm for developing distributed applications. An essential issue of utilizing SOC is to own an ascendible, reliable, and strong service discovery mechanism. However, ancient service discovery strategies mistreatment centralized registries will simply suffer from issues like performance bottleneck and vulnerability to failures in massive ascendible service networks, therefore functioning abnormally. During this paper we have a tendency to propose a P2P call tree induction algorithmic program during which each tree peer learns and maintains the proper call compared to a centralized state of affairs. Our algorithmic program is totally decentralized, asynchronous, and adapts swimmingly to changes within the information and also the network. In meta-algorithm that uses completely different classification models in line with a learning technique known as boosting. The algorithmic program could be a learning methodology which will handle weighted instances. Finally, we propose a rule induction algorithm to produces better accuracy than the original decision tree classifier.
Keywords |
| J48, Peer- to- Peer (P2P), WEKA |
INTRODUCTION |
| Decentralized P2P networks have many benefits over traditional client-server networks. These networks scale indefinitely while not increasing search time or the requirement for costly centralized resources. They utilize the process and networking power of the end-users’ machines since these resources forever grow in direct proportion to the network itself. As computing and communication over wired and wireless networks advanced, several pervasive distributed computing environments like net internet, intranets, LANs, adhoc wireless networks, and P2P networks have emerged call tree may be powerful applied math and Machine learning technique is wide used for information classification, Prognostic modelling and additional. Given a collection of learning example (attribute values and corresponding category labels) at a one location, there exist many wellknown methods to build a call tree like ID3 and C4.5. However, there can be several situations in which the data is distributed over a large, dynamic network containing no special server or client nodes. A typical example is a Peer-to-Peer (P2P) network. Performing data mining tasks such as building decision trees is very challenging in a P2P network because of the large number of data sources, the asynchronous nature of the P2P networks, and dynamic nature of the data. A scheme which centralizes the network data is not scalable because any change must be reported to the central peer, since it might very well alter the result. In this paper we propose a P2P decision tree induction algorithm in which every peer learns and maintains the correct decision tree compared to a centralized scenario. Our algorithm is completely decentralized, asynchronous, and adapts smoothly to changes in the data and the network. The algorithm is efficient in the sense that as long as the decision tree represents the data, the communication overhead is low compared to a broadcast-based algorithm. As a result, the algorithm is highly scalable. When the data distribution changes the decision tree is updated automatically. Our work is the first of its kind in the sense that it induces decision trees in large P2P systems in a communication-efficient manner without the need for global synchronization and the tree is the same that would have been induced given all the data to all the peers. |
II. MOTIVATION |
| P2P networks are quickly emerging as large-scale systems for information sharing. Through networks such as Kazaa, e-Mule, Bit Torrents, consumers can readily share vast of amounts of information. While initial consumer interest in P2P networks was focused on the value of the data, more recent research such as P2P web community formation argues that the consumers will greatly benefit from the knowledge locked in the data. For instance, music recommendations and sharing systems are a thriving industry today a sure sign of the value consumers have put on this application. However, all existing systems require that users submit their listening habits, either explicitly or implicitly, to centralized processing. Such centralized processing can be problematic because it can result in severe performance bottleneck. Wolff et al. have shown that centralized processing may not be a necessity by describing distributed algorithms which compute association rules (and hence, recommendations) innetwork in a robust and scalable manner. Later, Gilbert et al Showed that it is relatively easy, given an in-network knowledge discovery algorithm, to produce a similar algorithm which preserves the privacy of users in a well defined sense.[10] Have demonstrated the collaborative use of features for organizing music collections in a P2P setting. Users would prefer not to have the organization of their data change with every slight change in the data of the rest of the users. At the same time, users would also not like the quality of that organization to degrade a lot. As suggested in this paper, monitoring the change and updating the model seems to hit a good balance between being up-to-date and robust. Another application which offers high value to the consumers is failure determination. In failure determination, computer-log data which may have relation to the failure of software and this data are later analyzed in an effort to determine the reason for the failure. Data collection systems are today integral to both the Windows and Linux operating systems. Analysis is performed off-line on a central site and often uses knowledge discovery methods. Still, home users often choose not to cooperate with current data collection systems because they fear for privacy and currently there is no immediate benefit to the user for participating in the system. Collaborative data mining for failure determination can be very useful in such scenarios, and resolve concerns of both privacy and efficiency.1 However, failure determination models can be quite complex and developing such models require a lot of expert knowledge. The method we describe allows computing a model centrally, by whatever means deemed suitable, and then testing it against user’s data without overloading the users or requiring them to submit their data to an untrusted party. |
III. LITERATURE SURVEY |
| Chord to distribute and discover services are a decentralized manner. Based on the service publication approach, Chord4S supports QoS-aware service discovery. [1] AdaBoost has been used for distribute analysis and in parallel processing so far. The learning algorithm is able to handle instances weighted instances change the way it calculates the classifier error. [2] This paper was developed algorithm by Ross Quinlan. The decision tree techniques (J48 (C4.5), NBTree and in data mining were evaluated and compared on basis of accuracy and Error Rate. [5]. this paper also analyzes data set properties to find relations between them and the classification algorithms and pruning methods. [9] It is utilize message-based connectivity structure can considerably reduce the messaging cost, and provide better utilization of resources, which in turn improves the quality of service of the applications executing over decentralized peer-to-peer networks[16] |
IV. PROBLEM SCOPE OF THE PROJECT |
| Traditional service discovery approaches of the web services technology are based on Universal Description, Discovery, and Integration (UDDI). However, centralized service registries used by UDDI may easily suffer from problems in an open SOC environment. To overcome the problems The Peer-to-Peer (P2P) technology provides a universal approach to improving reliability, scalability, and robustness of distributed systems by removing centralized infrastructures. Based on Distributed Hashing Table (DHT), structured P2P systems can achieve even data distribution and efficient query routing by controlling the topology and imposing constraints on the data distribution. In this technology also problems occur. It is suffered from such as Problems; they are Bottleneck, Vulnerability to failure in large scale network. Large scale service network, largely distributed, unexpected failure of nodes cannot be avoided high cost and loss of control. |
V. ARCHITECTURE |
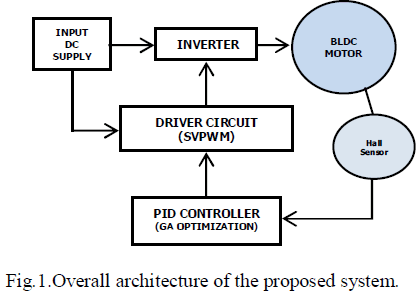
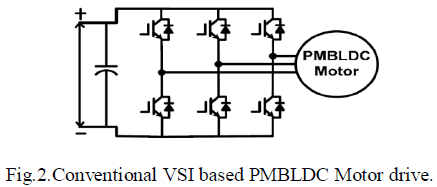
| P2P decision tree induction algorithm in which every peer learns and maintains the correct decision tree compared to a centralized scenario. Our algorithm is completely decentralized, asynchronous, and adapts smoothly to changes in the data and the network, shown in Fig.1The client request the service to P2P then collect the dataset and using the ID3 algorithm is efficient in the sense that as long as the decision tree represents the data, the communication overhead is low compared to a broadcast-based algorithm. As a result, the algorithm is highly scalable. When the data distribution changes, the decision tree is updated automatically Our work is the first of its kind in the sense that it induces decision trees in large P2P systems in a communication-efficient manner without the need for global synchronization and the tree is the same that would have been induced given all the data to all the peers. |
 |
VI.METHODOLOGIES |
A. Data set Creation |
| A collection of related sets of information that is composed a separate elements but can be manipulated as a unit by a computer. Datasets consist of all of the information gathered during a survey which needs to be analyzed. Learning how to interpret the results is a key component to the survey process. |
 |
B. Upload Data set |
 |
C. J48 Implementation |
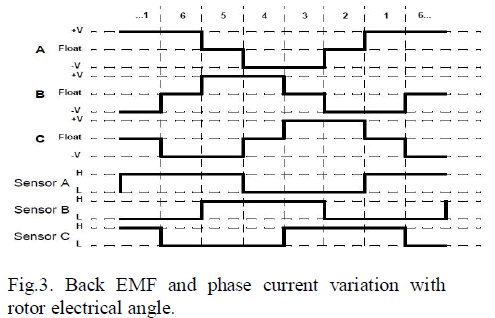
| J48 [QUI93] implements QuinlanâÃâ¬ÃŸs C4.5 algorithm [QUI92] for generating a pruned or un pruned C4.5 decision tree. C4.5 is an extension of Quinlan's earlier ID3 algorithm. The decision trees generated by J48 can be used for classification. J48 builds decision trees from a set of labeled training data using the concept of information entropy. It uses the fact that each attribute of the data can be used to make a decision by splitting the data into smaller subsets. J48 examines the normalized information gain (difference in entropy) that results from choosing an attribute for splitting the data. To make the decision, the attribute with the highest normalized information gain is used. Then the algorithm recurs on the smaller subsets. The splitting procedure stops if all instances in a subset belong to the same class. Then a leaf node is created in the decision tree telling to choose that class. But it can also happen that none of the features give any information gain. In this case J48 creates a decision node higher up in the tree using the expected value of the class. J48 can handle both continuous and discrete attributes, training data with missing attribute values and attributes with differing costs. Further it provides an option for pruning trees after creation. |
Program: |
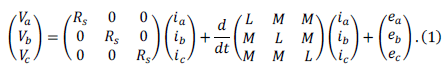 |
D. Resource Allocation |
| Resource allocation is the scheduling of activities and the resources required by those activities while taking into consideration both the resource availability and the project time. Cost of resources varies significantly depending on configuration for using them. The classifier is evaluated by cross-validation, using the number of folds that are entered in the Folds text field. |
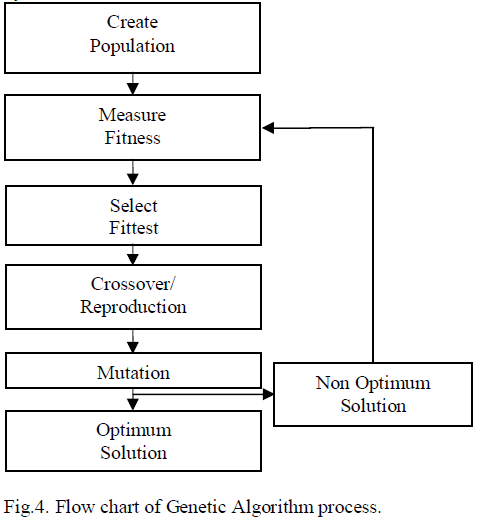 |
 |
 |
VII. CONCLUSIONS |
| P2P data processing is recently emerged from distributed data Pre-processing that deals with knowledge analysis in environments with distributed knowledge, computing nodes, and users This survey reveals that albeit P2P data processing algorithms addresses a number of the higher than mentioned options one or different, none of them cowl all the desired options. Analysis towards developing such algorithms has to be compelled to be thought-about. Our algorithmic rule is totally localized, asynchronous, and adapts swimmingly to changes within the knowledge and also the network. The algorithmic rule is economical within the sense that as long because the call tree represents the information, the communication overhead is low compared to a broadcastbased algorithmic rule. As a result, the algorithmic rule is very ascendable. once the information distribution changes, the choice tree is updated mechanically. |
VIII. Future Work |
| For the future work, scenario reduction techniques will be applied to reduce the number of scenarios. In addition, the optimal pricing scheme for cloud providers with the consideration of competition in the market will be investigated. Scenario reduction techniques will be applied to reduce the number of scenarios. In addition, the optimal pricing scheme for cloud providers with the consideration of competition in the market will be investigated. We need to predict the future resource needs of VMs. As said earlier, our focus is on Internet applications. One solution is to look inside a VM for application level statistics, e.g., by parsing logs of pending requests. Doing so requires modification of the VM which may not always be possible. Instead, we make our prediction based on the past external behaviors of VMs. |
ACKNO WLEDGMENT |
| We would like to thank our Assistant Professor S.Kamalesh for motivating us in doing such kind of my projects. And thanks to all the web sources. |