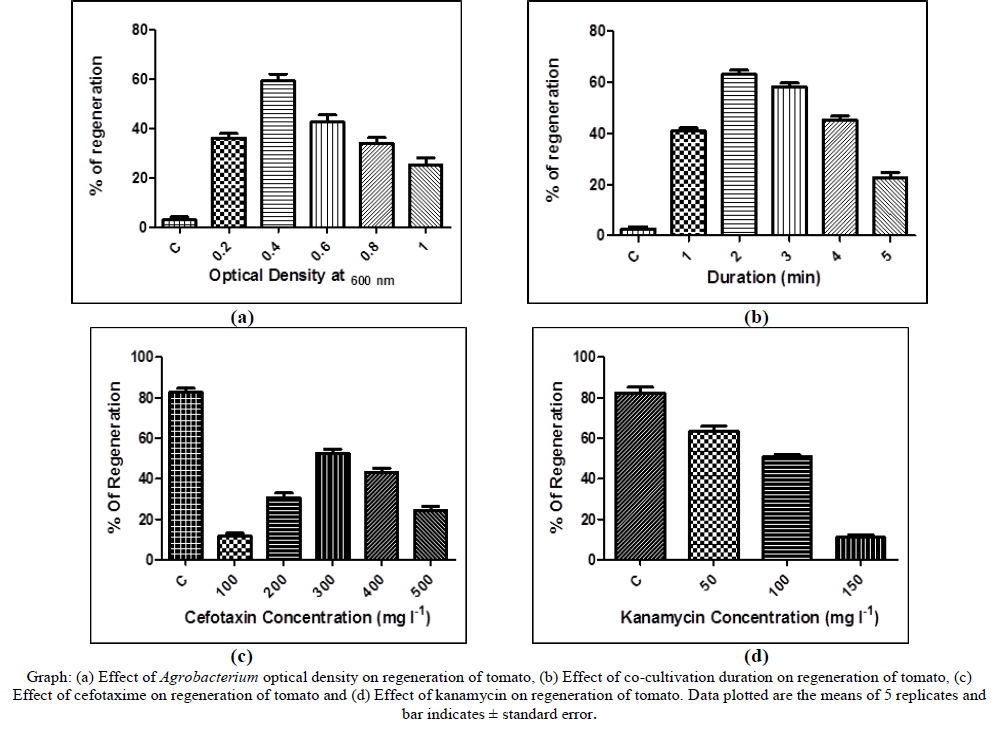
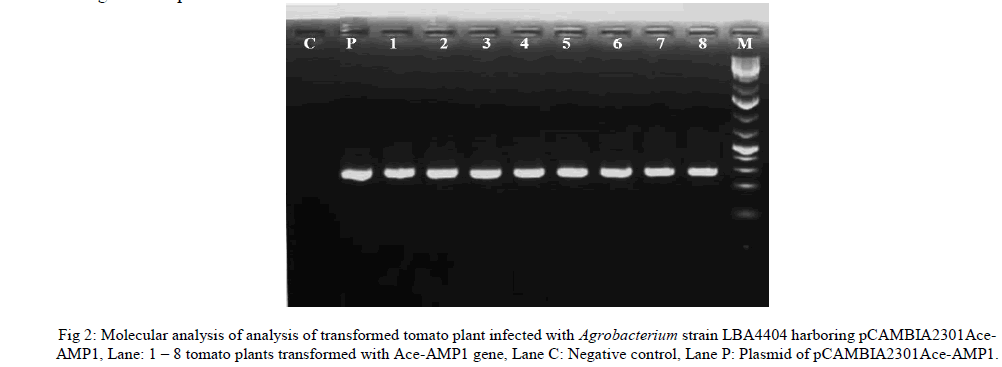
International Journal of Innovative Research in Science, Engineering and Technology
ISSN ONLINE(2319-8753)PRINT(2347-6710)
ISSN ONLINE(2319-8753)PRINT(2347-6710)
M. Ambika, Dr. K. Latha
|
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Innovative Research in Science, Engineering and Technology
Web Intelligence is a fast-growing area of research that combines multiple disciplines including artificial intelligence, machine learning, data mining, natural language processing. Making the web intelligent is the art of customizing items in response to the needs of the users. Predicting users‘ behaviors will expedite and enhance browsing experience, which could be achieved through personalization. Web Intelligence provides a platform which empowers internet users to find the most appropriate and best information for their interest. This paper proposes a novel approach for making the web adroit.
Keywords |
| web mining, web usage mining, web personalization. |
INTRODUCTION |
| In the today’s era of information technology, the Web provides every Internet citizen with access to the abundance of information. We can say that “We are drowning in data, but starving for knowledge.” Thus considering the impressive variety of the web, retrieving interesting, relevant and required information has become a very difficult task. A popular and successful technique which has shown many promises is web mining. |
| Web mining has become a hot research topic, which combines two of the prominent research areas comprising the data mining and the World Wide Web. “Web mining is a technique to explore, collate and extract patterns in the data content of web sites by using traditional data mining techniques”. More over web mining research is a multidisciplinary field from several research communities, such as database, information retrieval, and artificial intelligence research communities, especially from machine learning and natural language processing.One main issue to be considered in web mining is “Reach the Right Person with the Right Message at the Right Time”. The Web should have the ability to sense and adapt to the needs and preference of the user. One effective approach to this is to make the web intelligent. Here each and every individual visitor will be treated as individuals with their own goal and target when searching for information on the web. In the paper we proposed a novel approach to perform web personalization with intelligence.This paper is structured as follows: Section II, give an overview about web mining, Section III, shows deep and intense study of web intelligence. Section IV and V elaborates the proposed methodology and evaluation techniques. Finally, we concluded the paper in section VI and outlined some promising area of future research. |
II. WEB MINING |
| According to Oren Etzioni (1996), web mining is the application of data mining techniques to automatically discover and extract information from World Wide Web documents. The information gathered through web mining is evaluated by using traditional data mining parameters such as clustering and classification, association, and examination of sequential patterns. Web mining can also be used to understand customer behaviour, evaluate the effectiveness of a particular web site. Some of the issues related to the web [1] are information retrieval, information extraction, personalization of the web information, learning the consumers and individual user’s behaviour which can be used for user modelling and profiling. |
| Web mining deals with the discovery and analysis of useful information from the www. As suggested by Kosala and Blockeel (2000) and Qingyu Zhang et al. (2008), Fig. 1 depicts the Web mining sub tasks. The relevant data are retrieved from the web and then selection and pre-processing are done. Machine language or data mining techniques can be used for discovering the patterns, and finally, it is validated and visualization [1] [13]. |
 |
| Web mining process is of three different types based on the nature of the data such as [1][3][5], |
| Web Content mining: extract useful information or knowledge from the web page. It deals with text, image, records, etc. |
| Web Structure Mining: is the specialization of web content mining except it is tag content, mainly deals with the hyperlink structure of the web sites. |
| Web Usage mining: deals with the data mining techniques applied to web usage information such as web server logs, proxy logs, http logs, etc. It can be used to predict user behavior while the user interacts with the web. |
III. WEB INTELLIGENCE |
| The Web has been considered as the largest repository of information. In web based learning gathering accurate, effective and useful information or knowledge has become a challenging issue. Each and every user has their goal when searching for information on the Web [19] [20]. Some of the issues in the current web search engines are, |
| ïÃâ÷ Lack of user adaption |
| ïÃâ÷ Retrieve results based on web popularity rather than user's interests |
| ïÃâ÷ Relevant results beyond first few pages have a much lower chance of being visited by user |
| ïÃâ÷ Provides the same result for the same query. |
| ïÃâ÷ Relevance estimate is system centered approach. |
| One solution to above issues is to make the web, intelligent with the ability to sense and adapt to the users need. Every individual visitor is treated as individuals, with targeted content and offers that appeal to their implicit or explicit needs [9]. As a result it can achieve |
| ïÃÆü tailoring search results to individuals based on knowledge of their interests |
| ïÃÆü identify relevant documents and put them on top of the result list |
| ïÃÆü identify relevant documents and put them on top of the result list |
| ïÃÆü relevance is crucial |
| ïÃÆü making visitor’s time more productive and engaging. |
| Thus Web intelligence is an art, which can make the web as Wisdom web. Ning Zhong et.al (2000) coined the term Web Intelligence. It is the area of study and research of the application of artificial intelligence and information technology on the web in order to create the next generation of web empowered system [22]. It can be defined as a process of helping users by providing customized or relevant information on the basis of web experience to a particular user or set of users. It can also be defined as a recommendation system that performs information filtering with intelligence. The general phases of web intelligence process are (Fig. 2), |
| ïÃâ÷ Learning phase, |
| ïÃâ÷ Pattern extraction phase |
| ïÃâ÷ Information retrieval or Recommendation. |
 |
A. Learning Phase |
| Data collection phase is also known as learning phase. This phase is used to develop a user profile definition and user segments. A user profile is a collection of attributes that user will need to either maintain or derive in order to support personalization [17]. It is very important phase. Other phase depend on this phase. The user profile can be collected by two ways. |
| ïÃâ÷ implicit profile |
| ïÃâ÷ explicit profile |
| Implicit profile: The attributes can be derived from browsing patterns, cookies, and other sources. No feedback from the user is collected. It can also be derived from Geo Locations, Behavioural Learning, Contextual Learning, Social Collaborative Learning, and Simulated Feedback Learning. It is based on the characteristic of an individual’s such as Interest, Social Category, Context, role, functional area. It can also make use of current session activities, past session activities. |
| Explicit profile: The attributes come from online questionnaires, registration forms, integrated CRM or sales force automation tools, and legacy or existing databases. External feedback is collected from the user which provides rating or preferences. User personal information like age, occupation, religion, economic, environment etc can be used to generate user profile. |
| Pre-processing consists of elaborating the raw web access logs to produce data in a format usable by the Pattern Discovery phase. |
B. Pattern Discovery |
| Pattern discovery aims to detect interesting patterns in the pre-processed Web usage data by deploying various data mining techniques. These methods usually consist of (Eirinaki & Vazirgiannis, 2003): |
| ïÃâ÷ Association rule mining: A technique used for finding frequent patterns, associations and correlations between sets of items. In the Web personalization domain, this method may indicate correlations between pages not directly connected and reveal previously unknown associations between groups of users with same interests. |
| ïÃâ÷ Clustering: a method used for grouping together items that have similar characteristics. In our case items may either be users (that demonstrate similar online behavior) or pages (that are similarity utilized by users). |
| ïÃâ÷ Classification: A process that assigns data items to one of several predefined classes. Classes usually represent different user profiles. |
| ïÃâ÷ Sequential pattern discovery: An extension to the association rule mining technique, used for revealing patterns of co-occurrence, thus incorporating the notion of time sequence. A pattern in this case may be a Web page or a set of pages accessed immediately after another set of pages. |
C. Recommendation Phase |
| The aim of a recommender system is to determine which Web pages are more likely to be accessed by the user in the future [12]. In this phase active user’s navigation history is compared with the discovered Navigation patterns in order to recommend a new page or pages to the user in real time. Generally not all the items in the active session path are taken into account while making a recommendation. A very earlier page that the user visited is less likely to affect the next page since users generally make the decision about what to click by the most recent pages. Therefore the concept of window count is introduced. Window count parameter ‘n’ defines the maximum number of previous page visits to be used while recommending a new page. |
IV. PROPOSED METHODOLOGY |
| This paper proposes a new novel approach to perform web intelligence. The entire process is parted into two phase such as online phase and offline phase. The subsequent fig. 3 gives the general framework of the proposed method. |
 |
| The user profile is generated by collecting data from various sources and by performing necessary transformation and pre-processing. Personalized and useful patterns are extracted in the off line process. During online phase, the current active session of the user are taken into account, and based on the patterns generated from the uses previous experience, the personalized information will be provided to the user. |
A. Learning Phase or profile generation |
| In our investigation the effectiveness of personalized search is based upon the generation of user profile. The user profile has information that can distinguish one user from a multitude of other users. Profiles normally include topics of interests but may also include topics of disinterest by taking into account relevant and non-relevant documents [26]. |
| 1) Creation of user profile: There are two different ways to collect users’ interest. |
| ïÃâ÷ Implicit feedback |
| ïÃâ÷ Explicit feedback |
| Our system uses the implicit feedback approach to decipher the interests of a user. The information sources currently used are: |
| 1. The documents on the user's machine are taken as being of interest to him/her. The assumption is that if a user keeps a document on his/her machine there is a strong possibility that the user is interested in those documents. |
| 2. The browsing history is another source of information. Although not all web pages browsed are of interest to the user but pages that are frequently visited and those on which more time is spent can be taken as useful documents for the user's interest. |
| 3. The bookmarked pages are definitely interesting for a user. |
| 4. The download history can be used as a starting point for deciding favorite directories for download. This would be more useful in case of those users who organize files on their machines properly. |
| We believe that this approach has several advantages over previous work in which user profiles were built from user browsing hierarchies [18]. |
| 2) User profile representation: A profile constitutes the user's long-term information desires. There are two main distinct types of user profiles [27]: |
| a) Content-based profile: the user profile is depicted similar to a query, as a vector of terms. |
| b) Collaborative profile: this approach is based on the rating patterns of similar users. It is assumed that individuals with similar rating patterns seem to like the same kind of information - “like minded people”. Hence, a collaborative profile may be expressed as a list of similar users. |
3) Vector Space Model: |
| In our approach content based profile generation is used. In this model the documents are represented as feature vectors where features are the keywords extracted from a given set of the documents. If a term is more frequent in a document it is expected to be given more weight than a less frequent word as it represents the document better. In the term frequency model the value of a feature is term frequency divided by the total number of words in the document [29]. The term frequency tfij of a term ti in a document dj is defined as: |
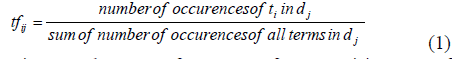 |
| The inverse document frequency of a term ti in a set of documents D is defined as: |
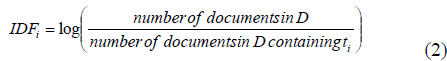 |
| A TF-IDF score wij is the product of tfij and idfi. The weight is calculated using the equation (3): |
B. Pre - Processing |
| Pre-processing involves interpreting raw user data and selecting which data to use so that is makes better sense for the rest of the system. The input data can be of different types (pdf, doc, ppt, html etc). They are first converted to text and then preprocessed. The preprocessing step involves stop-word removal and stemming. These are then converted to feature vectors where the features are the terms in the documents after the preprocessing step. |
| Filtered user data from this process is then the input for initial pattern extraction for new users. If the user is not new this filtered data can be combined with existing user data for discovery of new user patterns. |
C. Pattern Extraction |
| The unique behavior of web user has to be analyzed. Clustering technique is used to find common patterns, group similar objects, or to organize them in hierarchies. The grouping of similar objects should be such that members within a group are closer to each other than to members of a different group. |
| Evolutionary particle swarm optimization based clustering EPSO-Clustering [28] is based on the idea of the generation based evolution of the swarm. The swarm evolves through different intermediate generations to reach a final generation. Particles are initialized in the first generation and after each generation the swarm evolves to a stronger swarm by consuming the weaker particles of that generation by the stronger ones. The stronger the particle is, the greater its chance of survival to the next generation. Stronger particles make mature and stable generations. The strongest generation reached with an optimal number of clusters and lowest intra-cluster distance represent an optimal solution of the problem. The pseudo code of the process is given in Algorithm 1. |
 |
 |
D. Recommendation Phase |
| The user query has been processes based on the user profile and the personalized results have been suggested to the use. It is also known as retrieval process. During web search the results by the search engine are converted to feature vectors using the same pre-processing techniques that were used for the user profile. Thus each search result is represented by a feature vector. These feature vectors are then passed to Similarity Scorer which assigns them scores based on their similarity to interest vectors. Each result is assigned a score equal to the maximum of the similarity scores with each interest vector. The results along with their scores are passed to Re-Ranker which sorts the results based on the scores assigned and the modifies the ordering that is ultimately presented to the user. |
V. RESULTS AND EVALUATION |
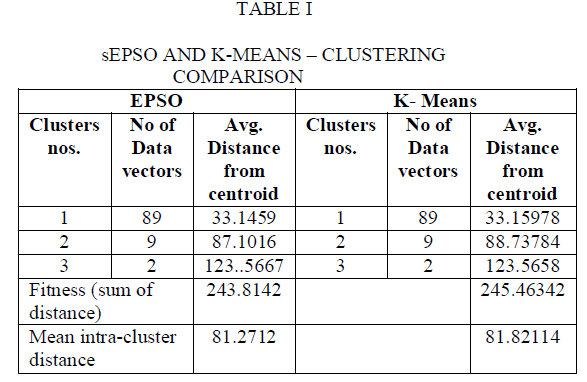
| To assess the performance of the approach we tested the algorithm on the NASA web log file and analyzed the logs containing one day of HTTP requests after passing the log through all the preprocessing steps. For our experiment we have considered 100 data vectors, which have to be categories under 3 clusters. The results are depicted in the following table1. |
 |
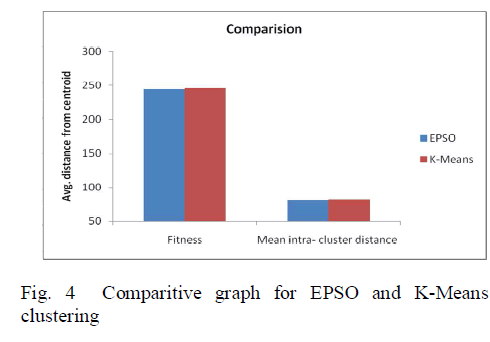 |
| For comparison purpose the intra distance within the cluster was taken. EPSO algorithm has been compared with the K-Mean cluster algorithm. Compared to the Kmeans the average distance has been reduced such that members within a group are closer to each other than to members of a different group. Thus the swarm was uniformly distributed along the input data space. Our proposed method can also be evaluated based on the following factors. |
| Precision: It is the ratio of the number of recommended pages actually viewed by the user to the total number of recommended pages. |
 |
VI. CONCLUSION |
| Web is growing rapidly, but on the other hand the user’s capability to access web content remains constant. Currently, Web personalization is the most promising approach to alleviate this problem and to provide users with tailored experiences. We built a system that creates user profiles based on implicitly collected information: User browsing histories and download histories thereby improving their performance by addressing the individual needs and preferences of each user, increasing satisfaction of user. Thus achieving 100% personalization is not possible. But we can reduce the searching time to mine massive amount of data by shifting internet from search based to find based. |
References |
|