International Journal of Innovative Research in Science, Engineering and Technology
ISSN ONLINE(2319-8753)PRINT(2347-6710)
ISSN ONLINE(2319-8753)PRINT(2347-6710)
V.Ranjani Gandhi1, N.Priya2
|
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Innovative Research in Science, Engineering and Technology
Recently important drugs for patient are given in online through reviews, blogs, and discussion forums. In this survey paper, compares various research parameters for statistical report in drugs reviews and the techniques used in it. The study papers was effective to understand the techniques and gives idea to propose an efficient EMalgorithm to develop for deriving aspects for various age groups using medicines of chronic diseases. Assessment to be carried out and experimental results on reviews of these different drugs to be compared if PAMM is able to find better aspects than other common approaches, when measured with mean point wise mutual information and classification accuracy.
Keywords |
| Drug review, Opinion Mining, Aspect Mining, Text Mining, Topic Modeling, Probabilistic Aspect Mining Model (PAMM), Joint Sentiment Topic (JST), Latent Dirichlet Allocation (LDA). |
INTRODUCTION |
| Nowadays people all over the world are connected and share their opinion through internet. User – centered domains like Twitter, Facebook, Amazon, and Orkut act as an interface. In recent era people are not only interested to look after official information but also product and service available through online [1]. Hence blogs, reviews and forums are used to analyze different kinds of aspects and domains. Opinion mining or sentiment analysis is deals with efficient and specified information about the extraction of data [4]. As a result of aspect level of opinion mining has been proposed to extract service, product and sentiment ratings. Recently patient are use to generate their blogs and reviews are useful for chronic disease and drugs with affecting side effects so many patients can get more information about drugs they are taking every day [2]. Patients can also able to share their experience, symptoms and side of drugs. A difficulty in dealing with reviews on drugs describes effectiveness of people’s experience and side effect |
| Medicines are very much diverse. Nevertheless, recently research studies focus on the patient’s information and their contents especially reviewing drugs for the chronically diseases so that many other patients can able to get more data base with similar conditions. Hence patient’s can also able to express their opinion in practical ways and side effects. Drugs have very more number of different kinds of aspects like effectiveness, side effects, price, usage of drugs and experience’s of the people drug reviews. The very much difficult in reviews diverse types of effectiveness, in particular side effects for one type of drug cannot be applicable for another products mostly by using mining techniques comments of the patient’s can be extracted. |
| In this paper we address opinion mining problem for drugs and proposed a novel Probabilistic Aspect Mining Model (PAMM) in order mining the drug reviews with structured information [10]. Many of the drug review websites are managed to perform sentiment opinion mining and grading functions but they tend to produce labeled information. The extracted topic is useful for patients because they can study about various aspects of the drugs and its functions. |
| The layout of the paper is as follows. In section II, address the above mentioned techniques and also give a brief on the literature being reviewed for the same. Section III, presents about proposed method and Section IV describes overall architecture explanation and working principles. Section V focuses on the algorithmic expressions. Sections VI explain various screen shots used in the project experimental execution. Section VII & VIII describes about conclusion and reference work. |
II. RELATED WORKS |
| In this paper [1] user generates a data which works on automated sentiment analysis and opinion mining in order to detect hidden information on unstructured text data. Sentiment classifiers are used to identify three kinds of orientation text like positive, negative or neutral. Hence satisfactory result cannot b obtained when sentiment classifiers trained on one domain and transferred to some other domain. On-line reviews which is more efficient and flexible. A common disadvantage is that sentiment classifiers are used to detect overall sentiment of a document without performing in depth analysis. This paper proposes novel based probabilistic modeling frame work called Joint Sentiment Topic (JST) based on Latent Dirichlet Allocation (LDA). In this paper [2] drug reviews from patient are documented on on-line but mining significant topics is very challenging. Interpretation of patient symptoms and drugs usage are used to make clinical report the study of this point is more sensitive to view functional status of patient. Opinion mining focuses on polarity classification another approach of review is based on computation of mutual information. Non negative matrix factorization recent advancement of NMF is similar to that of K-means algorithm. In this paper Regression Probabilistic Principal Component Analysis (RPPCA) was introduced to review sentiment values and also explore how to medical data has been used for document analysis.In this paper [3] probabilistic method as became very important for dimensionality reduction for text or image documents. Dimensionality reduction learning is often necessary because of data analysis. Principal Components Analysis (PCA) and Fisher Discriminate Analysis (FDA) is important learning algorithm for discriminative learning. This paper discusses on alternative method for finding reduced dimensionality representation on a discriminative frame work. DisLDA , a Discriminative Variation on Latent Dirichlet Allocation (LDA) a dependent linear transformation for dimensionality reduction and classification. In this paper [4] merchant selling products on On-line makes customers to share their opinions to make digital or hard copies. Unfortunately reading all customer reviews is difficult for any particular or special items. Hence this makes very difficult for any potential customer to read and understand the particular review. This paper helps to design a system for extracting, learning and classifying, a proposal of new method for learning frame work into web opinion mining and extraction which is built under frame work of lexicalized HMMS.In this paper [5] combination of text data and document metadata are viewed because of Bayesian multinomial mixture models like Latent Dirichlet Allocation (LDA) which makes text analysis simple, use of reduces the dimensionality of data and able to describe interpretable and semantically coherent topics are basically text data was accompanied by metadata such as dates, about authors and publication. Currently for specifying to generative model and implementing model has been developed. This paper helps to understand Dirichlet Multinomial Regression (DMR) model which indicates a long linear document topic distribution that function describes about the document features.In this paper [6] On-line products reviews has been focused because of increasingly available resources across web sites hence it makes consumers to make purchases based on decision of the competing products. A software tools has been introduced to the product reviews in order to make customer prospective. Designers of these tools are needed on content aggregation, content validation and content organization. The problem arises while some online products reviews focus on textual evaluation but some products are based on score ordered scales values. A comparison is done among the product for the quality checking tools. Hence they are capable for interpreting text only product reviews and scoring it. This paper helps to understand about several aspects on Victorial representation of the text by means of POS tagging, sentiment analysis and feature selection for ordinal regression learning. In [7] authors have described about unique sources for information in which user interface tools has been used for the creation of abundance labeled content many of the previous studies have generated user’s content in order predict labels automatically from the text associated. An Aspect Based Summarization gives the input to the user reviews for any particular product. Standard Aspect Based Summarization finds a set of relevant aspect topics for the rated entity in order to extract all textual mentions. Though it gives valuable aspect for each user to provide rating but annotating of every sentence and phrase in the review is being relevant to some of the topics. This paper gives detail description about statistical model which is able to discover corresponding topics in text and extract textual evidence.In [8] authors mentions many and many people use internet to publish online opinions known as weblogs. The large coverage of data, dynamic of effective discussion makes the data blog extremely valuable for mining user opinion on all the topics this approach helps to identify and extract positive and negative opinion from blog articles. Since the blog articles are used to cover mixtures of subtopics it can hold many different kinds of opinions which are more useful to analysis sentiment at the level of topics. This paper studies about modeling subtopics and sentiment by using two methods – Topic Sentiment Analysis (TSA) and Topic Sentiment Mixture (TSM) in order to extract multiple subtopics and sentiments for the collection of blog articles. In this paper [9] rapid growth on text data and text mining has been help full for discovering hidden knowledge from more domains in the business sector customer sentiment and opinion are expressed in a free text for the companies however huge amount of textual data is required to extract applications. In the recent past Natural Language Processing (NPL) has been developed for the novel text mining which used extract large amount of unstructured text data. This paper focus in the document level sentiment classification which is based on the proposed unsupervised Joint Sentiment Topic (JST) method on reporting initial result in the document classification. In [10] authors proposed web has a using over whelming product reviews and many other tangibles and intangibles. Although some websites are particularly designed for the predefined evaluation form, hence most of the users expressed their opinion using plain text in an online community. They incorporated unified model and sentiment so that resulting language represent the probability distribution over various aspects. This paper evaluates over various reviews and sentiments from different aspects automatically by using SLDA (Sentence - LDA) method. |
III. PROBABILISTIC ASPECT MINING MODEL |
| Probabilistic Aspect Mining Model (PAMM) method is used to generate data and class label. Data is represented by X£RM and class label Y£{0,1}, Z = (Z1,………… ZK.)T , Therefore the observed data for the PAMM is denoted by Z£RK. Non –negative matrix Factorization (NMF) deterministic method which is used to describe for Multi – Supervised Non – negative matrix Factorization (SSNMF) technique is the recent most which operates on supervised information. Probabilistic Aspect Mining Mode; focuses on the one class label presentation, different types of nodes represented to the one different type of class labels. PAMM technique classifies all the user reviews and sets out target class for differentiating different classes of reviews. |
 |
| The value is labeled to W ≥ 0 , this EM iteration algorithm continues unless or until there is a change in W between EM iteration below a user specified threshold. The contents posted by the users may not contain comprehensive and systematic reporting guidance because patients are not very much interested in reporting something they are not well concerned with. |
IV. OVERALL ARCHITECTURE |
 |
(a) COLLECTION OF DRUGS |
| The collection of Drugs called as Drug Bank database. Collecting drugs is highly accessible, comprehensive, quality, and contains the information about drugs and drug targets in online community. Bioinformatics and cheminformatics resources are clubbed together for the detailed drug reviews (i.e. Pharmaceutical and chemical, and pharmacological) and information about comprehensive data also been collected (i.e. pathway, sequence, and structure). Hence there is a high scope for comprehensive referencing, and data detailed description it is more akin to the drug database. Drug bank was widely used by the medicinal chemists, physicians, drug industry, student and general public. Collection of drug database used to discover and repurpose drugs which are existed and newly discovered illnesses. The latest drug database contains a version 4.0 entry which is approved by the small molecule drug factors. Additionally, 4270 nonredundant protein (i.e. drug target /transporter/carrier) sequences are linked to these drug entries. |
(b) FEATURES OF DRUGS: |
| Drug features can be classified into two different angles like Physiological Tolerance and Drug Tolerance which is subjected to the reaction when there is a particular drug progressively decreasing day by day then their needs concentration growth for enabling desired effects. The need of drug development mainly depends on the rate on the particular drug, frequency use of drugs, and differential development of the same drugs. For the improvement drugs we have to increase required parameters with the same magnitude of responsibility. Neural change in the frequent drug review leads to the changes in receptor desensitization and depletion in the neural.l transmitters this process helps in neural adaptation development environment. |
(c ) DATABASE |
| Organizing of the collected data is called database. Typical organizational model for the database aspects reality makes a supporting process for requiring information like availability of the required data events. Database management system is the computer software applications which are used to interact with the different type of user, and other application formats for analyzing the data. DBMS were designed in the following format for defining the data, creating new data type, query processing, updating, and administration process. Database management systems access the following languages like PostgreSQL, MySQL, Microsoft SQL server, Oracle, and IBM DB2. |
(d) WORKING PRINCIPLES |
| ïÃÆÃË The Collection of Drugs are extracted from the common database storage types where all the data being stored in the particular data storage server. |
| ïÃÆÃË The feature of the drug in order for the patient benefit is saved in the same storage server. |
| ïÃÆÃË The data extracted from the common database server is collected and stored in another medical database server for the classification. Therefore Doctors, medicinal chemists, drug industrialist, student, general public, and patients can able to view the information about any particular drug for the medicinal clarifications. |
| ïÃÆÃË In Aspect Mining Component we described different age group and attribute components for the experimental work formats for extracting the information from the medical database server. We classified two categories male and female types with three different kinds of attributes like child, adult, and old. |
| ïÃÆÃË User used to summarize keywords (i.e. Medicinal technical terms) and post queries in the created medical database server then the required answer are derived from the server and delivered to the clients. |
| ïÃÆÃË Clients can make suggestions on drawbacks and feed back about drugs for the future use. |
V. ALGORITHM |
 |
 |
VI. HOME PAGE |
 |
| Home page screen shot which describes entry level of project has been experimented. |
 |
REGISTRATION PAGE |
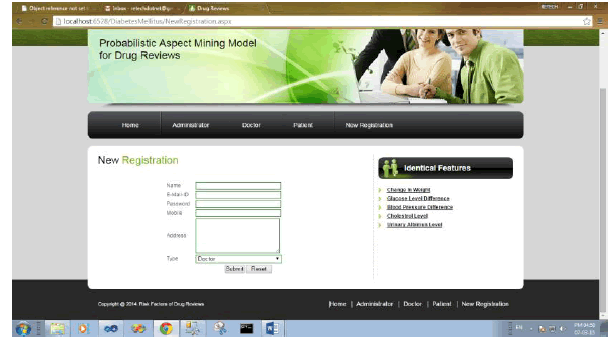
| Registration Page shot explains about new user registration application forms, Where new user can able to give detailed blog about his/her personal life and also for the future transaction of messages between user and client. |
 |
| Admin Page opens up the relationship between the storage manager and client. Once the new user created the account through registration page, user can further post his/her queries or can view the page and gather information by reading the blogs by some other user |
 |
| Review has been posted by the user in the consecutive screen shots therefore the final phase experimental setup has been derived. |
VII. CONCLUSION |
| This feature reduces the opportunities of forming aspects from reviews of different classes and hence the derived aspects are easier for people to interpret. Unlike the intuitive approach in which reviews are first grouped according to their classes and followed by inferring aspects for individual groups, PAMM uses all the reviews and finds the aspects that are helpful in identifying the target class. The experimental results in that the aspects obtained with PAMM give higher classification accuracy |
References |
|