International Journal of Innovative Research in Science, Engineering and Technology
ISSN ONLINE(2319-8753)PRINT(2347-6710)
ISSN ONLINE(2319-8753)PRINT(2347-6710)
R.Saranya1, Vincila.A2, Anila Glory.H3
|
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Innovative Research in Science, Engineering and Technology
Data Mining is the process of extracting knowledge hidden from huge volumes of raw data. The overall goal of the data mining process is to extract information from a data set and transform it into an understandable structure for further use. In the context of extracting the large data set, most widely used partitioning methods are singleview partitioning and multiview partitioning. Multiview partitioning has become a major problem for knowledge discovery in heterogeneous environments. This framework consists of two algorithms: multiview clustering is purely based on optimization integration of the Hilbert Schmidt - norm objective function and that based on matrix integration in the Hilbert Schmidt - norm objective function . The final partition obtained by each clustering algorithm is unique. With our tensor formulation, both heterogeneous and homogeneous information can be integrated to facilitate the clustering task. Spectral clustering analysis is expected to yield robust and novel partition results by exploiting the complementary information in different views. It is easy to see to generalize the Frobenius norm on matrices. Instead of using only one kind of information which might contain the incomplete information, it extends to carry out outliers detection with multi-view data. Experimental results show that the proposed approach is very effective in integrating higher order of data in different settings
Keywords |
| Multiview partitioning, tensor formulation, Spectral clustering, Hilbert Schmidt – norm, Frobenius norm. |
INTRODUCTION |
| data mining in which it is defined as a collection of data objects that are similar to one another. The principle of Clustering is to group fundamental structures in data and classify them into meaningful subgroup for additional analysis. Many of the clustering algorithms have been published yearly and can be proposed for developing various techniques and approaches. Similarity between a pair of objects can be defined either explicitly or implicitly. For a group of people, their age, education, geographic location, and social and family connections can be obtained. For a set of published papers, the authors, citations, and terms in the abstract, title and keywords are well known. Even for a computer hard drive, the names of the files, their saved location, their time stamp, and their contents can be obtained easily. For each of these examples, to find a way to cluster the people, documents, or computer files, this approach is to treat all the similarities concurrently. The methods may also be used to minimize the effects of human factors in the process. There are several categories of clustering algorithms. In this paper we will be focusing on algorithms that are exclusive in that the clusters may not overlap. Some of the algorithms are hierarchical and probabilistic. A hierarchical algorithm clustering algorithm is based on the union between the two nearest clusters. After a few iterations, it reaches the final clusters. The final group of probabilistic algorithms is focused around model matching using probabilities as opposed to distances to decide clusters. EM or Expectation Maximization is an example of this type of clustering algorithm. Pen et al. [7] used cluster analysis which consist of 2 methods. Method I, a majority voting committee with 3 results generates the final analysis result. The performance measure of the classification is decided by majority vote of the committee. If more than 2 of the committee members give the same classification result, then the clustering analysis for that observation is successful; otherwise, the analysis fails. Kalton et al. [8], proposed an algorithm to create its own clusters. After the clustering was completed each member of a class was assigned the value of the cluster’s majority population. The authors noted that the approach loses detail, but allowed them to evaluate each clustering algorithm against the “correct” clusters. In a set of multiple networks, they share same set of nodes but possess different types of connection between nodes. Number of relationship can be formed through specific activity is called multiview learning [2]. The recent development in clustering is the spectral clustering. Spectral clustering is purely based on the Ncut algorithm [1]. This can work well in the single view data as it is based on matrix decompositions. Many clustering algorithms have been proposed in comparison with the single view data. Therefore, these algorithms have some limitation. Tensors are the higher order generalization of matrices .They can be applied to several domains such as web mining, image processing, data mining, and image recognition. Tensor based methods are used to model multiview data. This is used to detect the hidden pattern in multiview data subspace by tensor analysis. It works based on the tensor decomposition [1] which captures the multilinear structures in higher order data, where data has more than two modes. In tensor, similarity of researchers is one slice, and then similarity citations are one slice. Finally, all slices will be combined to form tensor. Tensor decomposition is used to cluster all the similarity matrices into set of compilation feature vector. Many clustering algorithms like k Means, SVD, HOSVD are used for many tensor methods. Spectral clustering [1] is used for clustering the similarity matrices based on tensor methods. |
RELATED WORK |
| Xinhai Liu et al. [1], has proposed a multiview clustering framework based on tensor methods. Their formulations model the multiview data as a tensor and seek a joint latent optimal subspace by tensor analysis. The framework can leverage the inherent consistency among multiview data and integrate their information seamlessly. Apart from other multiview clustering strategies, which are usually devised for ad hoc application, tensor method provides a general framework in which some limitations of prior methods are overcome systematically. In particular, the framework can be extended to various types of multiview data. Almost any multiple similarity matrices of the same entities are allowed to be embedded into their framework. H. Huang et al. [2], has achieved that the tensor based dimension reduction has recently been extensively studied for data mining, machine learning, and pattern recognition applications. At the beginning, standard Principal Component Analysis (PCA) and Singular Value Decomposition (SVD) were popular as a tool for the analysis of two-dimensional arrays of data in a wide variety arrays, but it is not natural to apply them into higher dimensional data, known as high order tensors. Powerful tools have been proposed by Tucker decomposition. HOSVD does simultaneous subspace selection (data compression) and K-means clustering widely used for unsupervised learning tasks. In this paper, new results are demonstrated using three real and large datasets, two on face images datasets and one on hand-written digits dataset. K. Chaudhuri et al. [4], has developed a clustering data in high dimensions. A number of efficient clustering algorithms developed in recent years address this problem by projecting the data into a lower-dimensional subspace, e.g. via Principal Components Analysis (PCA) or random projections, before clustering. Projections can be made using multiple views of the data, via Canonical Correlation Analysis (CCA). This algorithm is affine invariant and is able to learn with some of the weakest separation conditions to date. The intuitive reason for this is that under multi-view assumption, there is a way to (approximately) find the low-dimensional subspace spanned by the means of the component distributions. This subspace is important, because, when projected onto this subspace, the means of the distributions are well-separated, yet the typical distance between points from the same distribution is smaller than in the original space. The number of samples required to cluster correctly scales as O(d), where d is the ambient dimension. Finally, the experiments shows that CCA-based algorithms consistently provide better performance than standard PCA-based clustering methods when applied to datasets in the two quite different domains of audio-visual speaker clustering and hierarchical Wikipedia document clustering by category. Most provably efficient clustering algorithms first project the data down to some low-dimensional space and then cluster the data in this lower dimensional space (an algorithm such as single linkage usually suffices here). Typically, these algorithms also work under a separation requirement, which is measured by the minimum distance between the means of any two mixture components. |
MATERIALS AND METHODS |
| A. Multiview Clustering |
| A multiview clustering method that extends k-means and hierarchical clustering to deal with data as two conditionally independent views . Canonical correlation analysis in multiview clustering assumes that the views are uncorrelated in the given cluster label. These methods can concentrate only on two view data. Long et al [6], formulated a multiview spectral clustering method while investigating multiple spectral dimension reduction. Zhou and Burges developed a multiview clustering strategy through generalizing the Ncut from a single view to multiple views and subsequently they build a multiview transductive inference. In tensor-based strategy, the multilinear relationship among multiview data is taken into account. The strategy focuses on the clustering of multitype interrelated data objects, rather than clustering of the similar objects using multiple representations as in our research. |
| B. Spectral Clustering |
| Spectral clustering was derived based on relaxation of the Ncut formulation for clustering. Spectral clustering involves a matrix trace optimization problem. In this paper, we proposed that the spectral clustering formalism can be extended to deal with multiview problems based on tensor computations. Given a set of N data points {��i} where ��i���d is the i th data point, a similarity ��ij can be defined for each pair of data points and based on some similarity measure. A perceptive way for representing the data set by using a graph G= (V,E) in which the vertices V represents the data points and the edges characterize the similarity between data points which are quantified by the similarity measure of the graph is symmetric and undirected. The matrix of the graph G is the matrix S with entry in row i and column j equal to Sij .The degree of the vertex can be written as |
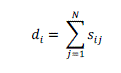 |
PROPOSED SYSTEM |
| Spectral clustering is used for integrating cluster in heterogeneous environment. In the proposed system, one of the tensor method known as Hilbert Schmidt norm (HS-Norm) is used. The advantage of HS norm: it is mainly used for identifying hidden pattern in the context of spectral clustering. This provides the good result when compared to other tensor methods. Here synthetic datasets are used for evaluating the results by comparing with Frobenius Norm. Tensorbased methods have been used to model multi-view data. This framework is used to implement both single view and multi view spectral clustering. Furthermore, The Hilbert Schmidt norm, sometimes also called the Matrix norm, which extends their capability with infinite dimensional space. Not limited to the clustering analysis, since its core is to get a combined optimal Hilbert subspace. It is easy to see to generalize the Frobenius norm on matrices. Moreover, its iterative level is minimal. Instead of using only one kind of information which might contain the incomplete information, it extends to carry out outliers detection with multi-view data. |
| A. SIMILARITY MATRIX |
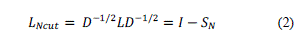 |
| The resulting similarity ranges from -1 meaning exactly the same, with 0 usually indicating independence and inbetween values indicating intermediate similarity of dissimilarity. |
| C. TENSOR BASED ANALYSIS |
| Multiview Spectral Clustering |
| In integration of multiview data in spectral clustering, there are different strategies |
| 1) MULTIVIEW CLUSTERING BY TRACE MAXIMIZATION(MC-TR-I) |
| The first strategy is to add objective functions of the type, associated with the different views. Consider, |
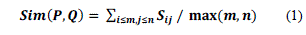 |
| D. CLUSTER LABEL |
| Cluster Label is likely related to the concept of text clustering. This specific process tries to select descriptive labels for the clusters obtained through a clustering algorithm such as Spectral Clustering and Hierarchical Clustering. The interaction probability is calculated for each group member. Based on the dimensions, interaction probability differs. |
| Typically, the labels are obtained by examining the contents of the documents in a cluster. A good label not only summarizes the central concept of a cluster but also uniquely differentiates it from other clusters in the collection. Regarding clustering evaluation, the data sets used in our experiments are provided with labels. Therefore, the clustering performance is evaluated comparing the automatic partitions with the labels using Adjusted Rand Index. Adjusted Rand Index(ARI) has a lower fixed bound of 0 and upper bound of 1. It takes the value of 1 when the two clustering are identical and 0 when the two clustering are independent, i.e. share no information about each other. |
CONCLUSION |
| Clustering in data mining has become a crucial issue in recent years. However, most prior approaches assume that the multiple representations share the same dimension, limiting their applicability to homogeneous environments. In this paper, one of the tensor based framework namely, Hilbert Schmidt norm is used for integrating heterogeneous environments. The future work will focus on performance measures when it is compared with the existing approach with respect to their cluster label. Experimental results demonstrate that the proposed formulations are effective in integrating multiview data in heterogeneous environments. |
References |
|