International Journal of Innovative Research in Science, Engineering and Technology
ISSN ONLINE(2319-8753)PRINT(2347-6710)
ISSN ONLINE(2319-8753)PRINT(2347-6710)
Vaibhav P. Vasani1, Rajendra D. Gawali 2
|
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Innovative Research in Science, Engineering and Technology
In this paper, classification of the data collected from students of polytechnic institute has been discussed. This data is pre-processed to remove unwanted and less meaningful attributes. These students are then classified into different categories like brilliant, average, weak using decision tree and naïve Bayesian algorithms. The processing is done using WEKA data mining tool. This paper also compares results of classification with respect to different performance parameters.
Keywords |
| Classification; data mining; decision tree algorithm; educational data mining; Naïve Bayesian algorithm; WEKA; education; confusion matrix; margin curves; accuracy; true positive rate; false positive rate; precision; threshold curves. |
INTRODUCTION |
| Different areas of research in educational data mining are analysis and visualization of data, recommendations for students, student modeling, detecting undesirable student behaviour, grouping of students, social network analysis, developing concept maps, constructing courseware, planning and scheduling and predicting student’s performance. |
| Educational data mining (EDM) is a field that exploits machine-learning, statistical and data-mining algorithms over the different types of educational data. Its main objective is to analyse data in order to resolve educational research issues. EDM is concerned with developing methods to explore the unique types of data in educational settings and, using these methods, to better understand students and the settings in which they learn. This data helps to understand learners and learning and to develop computational approaches that combine data and knowledge to transform practice to benefit learners [1] [4] [5]. |
| The objective of prediction is to estimate the unknown value of a variable that describes the student. Prediction of performance, knowledge, score, or mark is done. This value can be numerical/continuous value (regression task) or categorical/discrete value (classification task). Regression analysis finds the relationship between a dependent variable and one or more independent variables. In classification individual items are placed into groups based on quantitative information regarding one or more characteristics inherent in the items and based on a training set of previously labeled items. For Prediction techniques used like neural networks, Bayesian networks, rule-based systems, regression, and correlation analysis is also. Different types of neural-network models have been used to predict final student grades (using back-propagation and feed-forward neural networks). A candidate being considered for admission into the university (using multilayer perceptron topology), Bayesian networks have been used to predict student applicant performance [1] [2] [3]. |
III. IMPLEMENTATION |
| Data mining tools for educational research issues are prominently developed and used in many countries. In country like India, demand for educational data mining has been increased from last few years, because of increase in educational database and need of discovery of knowledge from that database to take important decisions and remedial solutions. |
| Many commercial data mining software packages are available with various levels of sophistication and cost. |
| One of the popular data mining tools is WEKA (Waikato Environment for Knowledge Analysis). Since this is open source tool and supports many data mining algorithms, this has been used for pre-processing and classification of student data. |
| WEKA 3.6.6 has been used to classify the students using decision tree and Naïve Bayesian algorithms. |
| Sample dataset: Here data for classification has been collected from 220 students of private polytechnic institute. To analyse dataset, attributes considered are SSC marks (percentages), maths (marks in mathematics), medium (language of instruction), and area (place of residence). Roll numbers were considered initially for row identification. But they were removed during pre-processing of data, as they were generating errors in calculation. The sample dataset is shown in table 1. |
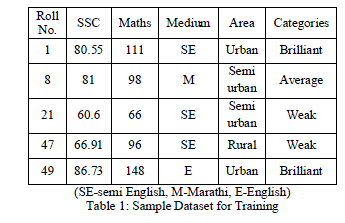 |
| Accuracy/error rate estimation: Errors in the classification techniques can be considered as incorrect classification of instances. These errors refer to overall performance of the model or the algorithm. |
| Following table 2 shows the confusion matrix where rows representing the actual classes and the columns the predicted classes such as brilliant, average and weak. |
| Student in the dataset may belong to any one of the category such as A (correct prediction, true positive), B (incorrect prediction, false negative), C (incorrect prediction, false negative), D (incorrect prediction, false positive), E (correct prediction, true positive), F (incorrect prediction, false negative), G (incorrect prediction, false positive), H (incorrect prediction, false positive) and I (correct prediction, true negative). |
| Accuracy which is the ratio of the number of incorrectly classified instances to the total number of examined instances can be calculated as |
 |
IV. RESULTS AND DISCUSSION |
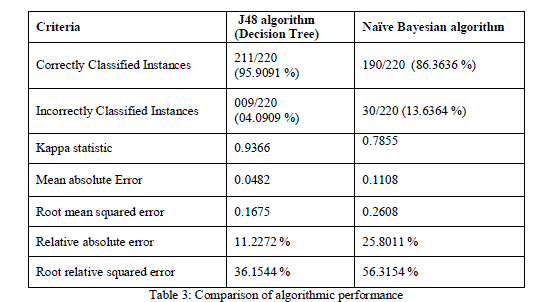
| Table 3 compares results of Decision tree (J48) and Naïve Bayesian Algorithms with respect to different performance criteria. |
 |
 |
 |
| Results of Naïve Bayesian Algorithm: The probabilities of classes found using naïve Bayesian algorithm are brilliant (0.42), average (0.36) and weak (0.22). |
| Accuracy measures and confusion matrix for each class using naïve Bayesian algorithm are as shown in table 6 and 7, Confusion Matrix for J48 Algorithm in table 7 shows the classification of 220 students in dataset into different classes. |
 |
 |
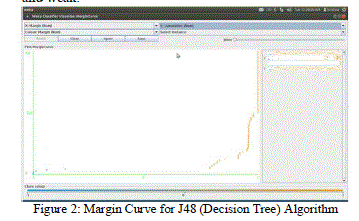
| The margin curves of J48-Decision tree and Bayesian classification algorithms are shown in figure 2 and 6 respectively. The margin curve prints the cumulative frequency of the difference of actual class probability and the highest probability predicted for other classes (so, for a single class, if it is predicted to be positive with probability p, the margin is p-(1-p) =2p-1). The negative values denote classification errors, meaning that the dominant class is not the correct one. |
| The figure 2 depicts, the majority of instances are correctly classified by J48 decision tree model, since they are centralized in the area of probability one (the right part of the graph). On the other hand, the classified instances of Naïve Bayesian algorithm (figure 6) are not concentrated in that area, revealing a significant deviation. |
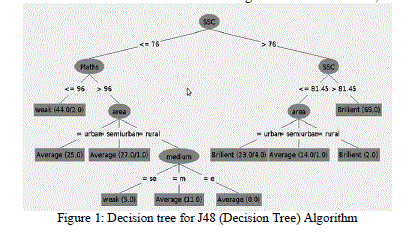
| The visualized threshold curves show (figures 3, 4 & 5 for J48-decision tree algorithm and figure 7, 8 & 9 for Naïve Bayesian algorithm) the effect of varying the probability threshold above which an instance is assigned to that class. It represents that how data is perfectly classified as if curve is more towards the left corner of graph. It proves that all data is perfectly classified in all three categories viz. Brilliant, average and weak. |
| Making predictions has become an essential part of every business enterprise and scientific field of inquiry. Receiver operating characteristic (ROC) curves are useful for assessing the accuracy of predictions. |
V. CONCLUSION |
| Students in dataset are classifieds into brilliant, average and weak classes on the basis of their SSC marks, marks of mathematics, area of residence, medium of instruction. |
| The result of classification can be used to take remedial actions on students learning process. This study shows more attention should be given to improve basic fundamentals in mathematics and language. This can be improved with help of tutorials, training and seminars for weaker sections of the students. Also it is observed that students from remote or rural lack in confidence which results in lower grades in examination. Their confidence level may be raised by mentoring them by faculties as well as through the motivational lectures. |
| The overall improvement in student performance may help them to succeed in academics as well as industrial/professional skills. |
| After comparing results of both algorithms, it is also observed that Decision tree (J48) gives better result than Naive Bayesian algorithm in terms of accuracy in classifying the data. |
References |
|