International Journal of Innovative Research in Science, Engineering and Technology
ISSN ONLINE(2319-8753)PRINT(2347-6710)
ISSN ONLINE(2319-8753)PRINT(2347-6710)
|
Lakshmi Priya.K P.G. Student, Department of Electronics and Communication Engineering, PSNA College of Engineering and Technology, Dindigul, Tamilnadu, India. |
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Innovative Research in Science, Engineering and Technology
In this paper I present an energy efficient reconfigurable MIMO (Multiple input Multiple output)decoder accelerator hardware architecture. It delivers full programmability across different wireless standards (i.e., WiFi, 3G-long term evolution, and WiMax) as well as different MIMO decoding algorithms (i.e., minimum mean square error, singular value decomposition, and maximum likelihood) with extreme energy efficiency. We propose an Hough transform architecture instead of CORDIC for the Rotation unit in the processing core . The energy efficiency of our MIMO accelerator chip was compared against existing programmable MIMO accelerator, it delivered energy efficiencies that were 5% less than the existing system.
Keywords |
| CORDIC, Hough Architecture, Reconfigurable MIMO (Multiple input Multiple output) decoder, Rotation Unit. |
INTRODUCTION |
| Multiple-input–multiple-output (MIMO) processing and orthogonal frequency division multiplexing (OFDM) are two dominant technologies in emerging wireless communications systems .MIMO is an antenna technology for wireless communications in which multiple antennas are used at both the source and destination to minimize errors and optimize data speed[1-5].In OFDM a wideband frequency selective fading channel is divided into several independent narrowband flat-fading sub channels. A MIMO decoder is the receiver component that separates the Nss transmitted data streams from the signals received on the Nrx receives antennas. The MIMO decoding operation is matrix and vector intensive. For an OFDM system, this processing is repeated for every sub channel. MIMO-OFDM techniques improve data rate and reliability. Several publications [6-13] report on various hardware designs and implementations for MIMO decoders. but these decoder designs use a single MIMO decoding algorithm such as zero forcing (ZF), minimum mean square error (MMSE)[6],[7]. maximum likelihood (ML) [8] or one of the many sphere decoding (SD) variants[9-11], Several reconfigurable MIMO decoders have been reported in the literature[10-12] .These designs are neither flexible enough to be tailored to a new standard. |
| New wireless communication standards and new MIMO decoding algorithms emerging every few years, existing systems need to be redesigned and upgraded not only to meet the newly defined standards, but also to allow integration of multiple standards onto the same platform and improve performance via more advanced decoding algorithms. A programmable MIMO decoder design is reported in [13-17] but it consumes more power because of its complex and iterative nature and it is not reliable because of the possibility of error. There is need for a more flexible, yet efficient MIMO decoder implementation. Such a decoder should ideally be able to serve multiple standards simultaneously without compromising any of the throughput, area, and power requirements. Paper is organized as follows. Section II describes MIMO Hardware architecture and related work of the MIMO accelerator, Section III describes Rotation unit and Section IV presents experimental results showing simulation results of proposed Rotation unit MIMO accelerator. Finally, Section V presents conclusion. |
MIMO ACCELERATOR HARDWARE ARCHITECTURE |
| The MIMO accelerator architecture is shown in Fig 1. The main challenge in designing the memory map was providing a centralized data memory that allows general modes of access to data, independent of the algorithm,while maintaining the ability to provide the data vectors arranged in the correct order to and from the processing cores in a single cycle[16].The processing core is optimized for programmable processing of matrix operations necessary for linear MIMO decoders. |
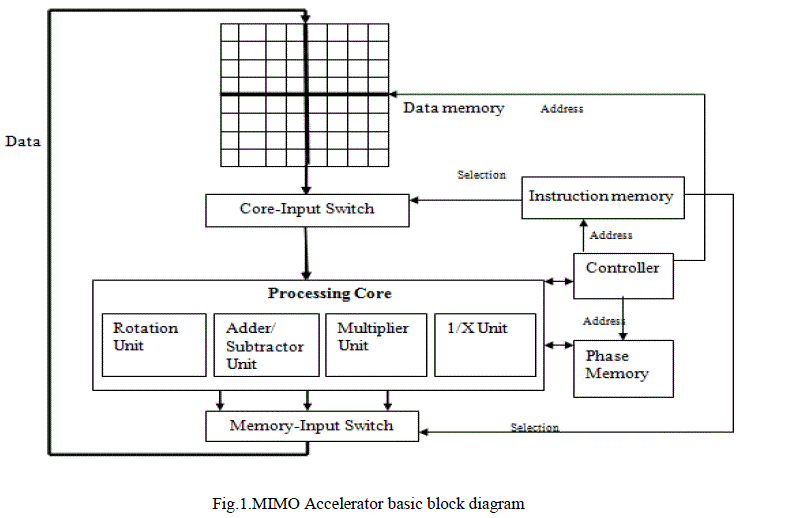 |
| The MIMO accelerator is a complex number vector-based processor that works on complex vector operands of length Nrx —where Nrx is the number of receive antennas used in the MIMO system. Since most MIMO decoding algorithms can be broken down into a series of vector operations, the processor uses a vector as its smallest operand. |
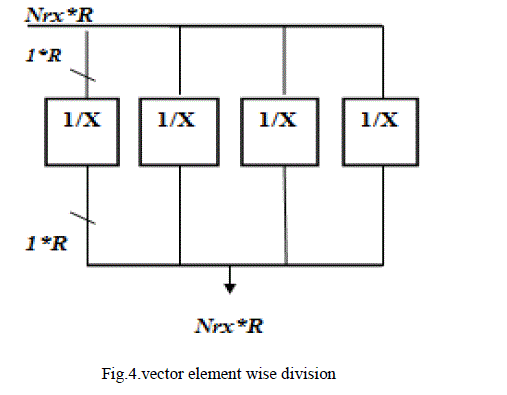
| The processing core consists of four Processing units: 1. Matrix addition/Subtraction unit ,2.Inner product unit 3.Vector element- wise division unit and 4.Rotation unit. These operations are necessary and sufficient for coverage of major linear MIMO decoding algorithms [14].The number of units in each core is chosen to equalize the number of outputs and force them to be a multiple of the vector size. |
| The four processing units are shown. Where Fig 2. shows the addition unit, which is an adder/subtractor that can process two pairs of Nrx complex vectors simultaneously. Examples of its uses are the formulation of the MMSE matrix and the calculation of the SD metrics. |
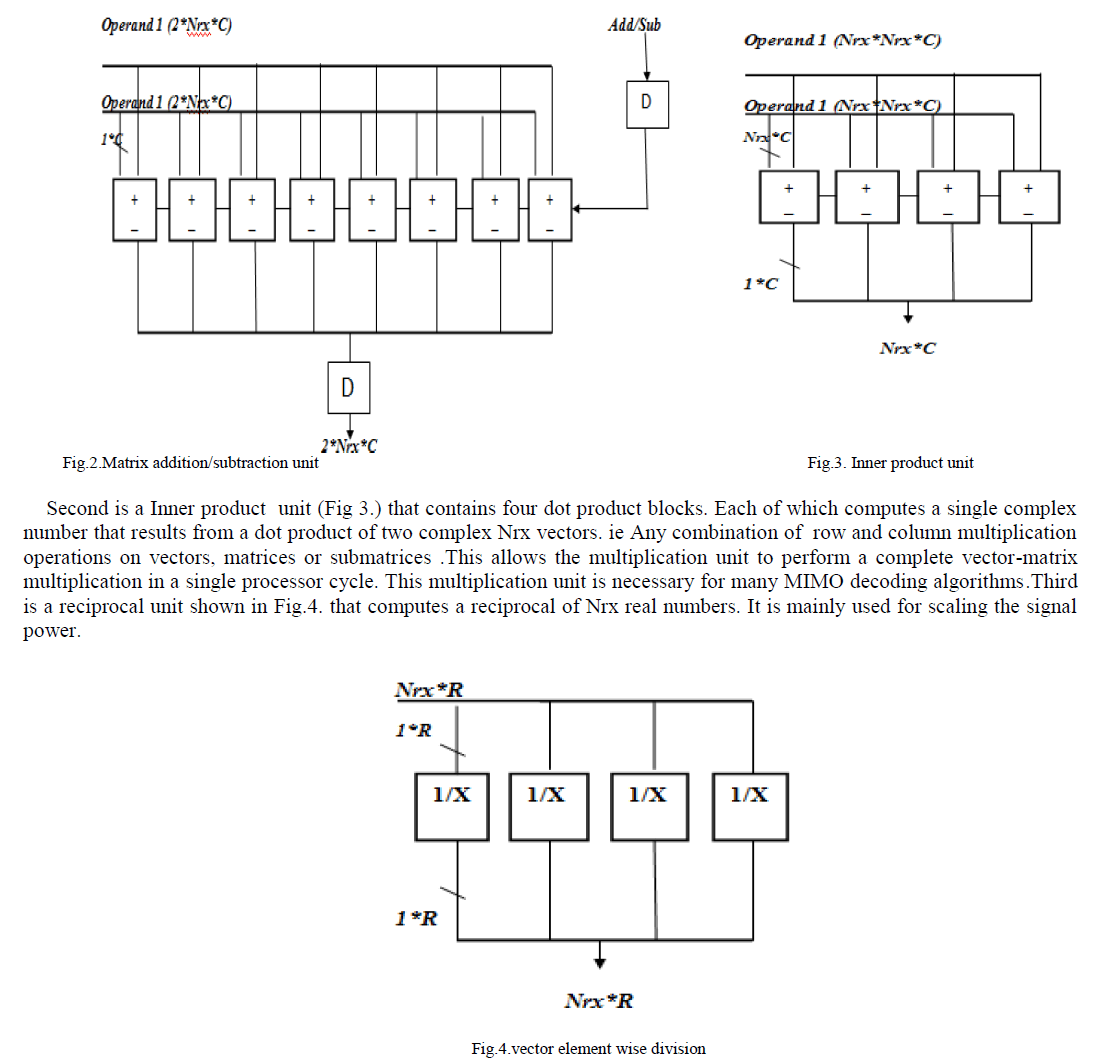 |
ROTATION UNIT |
| The fourth processing unit is the rotation unit. It is the most power hungry unit in the processing core. Generally it consists of a group of coordinate rotation (CORDIC) blocks[18]. Here CORDIC is COordinate Rotation DIgital Computer, also known as the digit-by-digit method. It takes so many iterations to complete a single rotation so it consumes more power. This can be modified by using Hough architecture. It works based on line segment and produces a rotated sequence with reduced number of iteration [19]so the power consumption can be minimized . |
ROTATION UNIT USING HOUGH TRANSFORM |
| A block diagram of the proposed architecture is shown in Fig. 5. Run-length encoding is a simple process which reads the binary values from the input and output the{rb,code,zl}triplet. The PE is run-time configurable for computing Hough transform of any angles. Each PE calculates the consolidated ρθ values for all the input data where ρθ represents ρ value for a line with angle θ. The Vote Memory stores all the votes. Here we use both inter-block and intra-block incrementing in their PE. The inter-block incrementing shown in Fig.6. that calculates the ρθ(po) of first input where ρθ represents ρ value for a line with angle θ which passes through the point p. The intra-block incrementing calculates ρθ(x,y) values of other data s after the inter-block incrementing. Two accumulators can be used to implement the inter-block incrementing as shown in Fig. 6, where Nsinθ can be precomputed. In order to skip zero-blocks, a step-table is introduced in the proposed architecture. Col-reg calculates theρθ(po) values for the nonzero blocks in a block-row in the -direction every clock cycle, and row-reg calculates ρθ(po) values for the first blocks of block-rows in the -direction every time after a block-row processing is completed. |
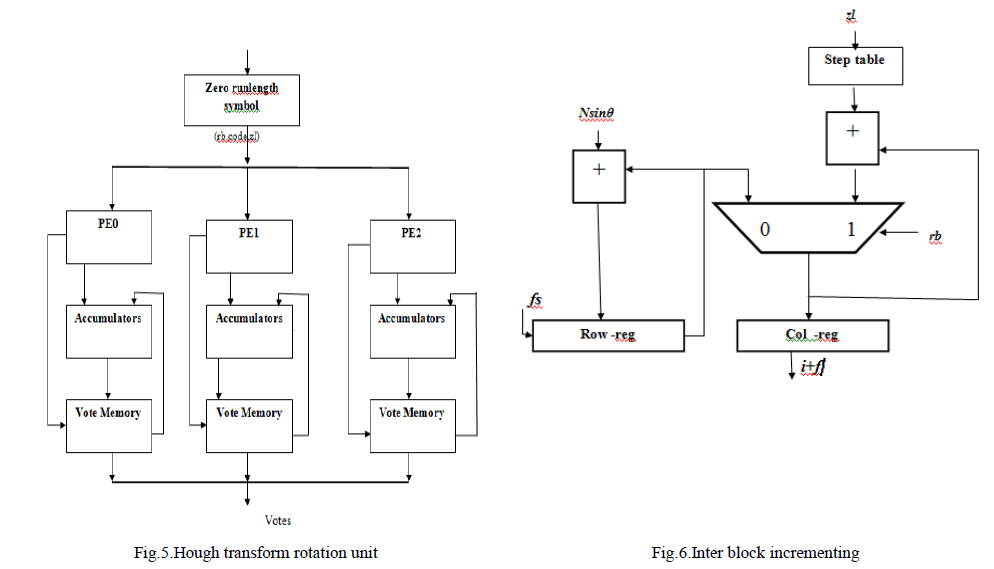 |
| In Intra-block incrementing and the computed ρθ(po) can be used to calculate all the other ρθ values in the block simultaneously by using the corresponding dx,dy,cosθ and sinθ values This will result in seven more ρθ values. For the whole data, the eight votes in the memory addressed by the eight ρθ values will need to be accumulate . The computed ρθ(po) is divided into the integer part i0 and the fractional part f0 only the fractional part is used for calculating the voteoffsets as shown in Fig. 7. The first stage of Fig. 7 calculates the vote-offsets V0i for the ith input The vote-offsets range from 0 to 4, and are represented by 3-b numbers. These numbers are decoded by 3:8 decoders as shown in the second stage of Fig. 7. In Fig. 8, the outputs of the decoders are combined with the values of the corresponding input using a combination logic circuit to determine Vi, which represents the consolidated number of votes for each different vote-offset. |
| Core and memory input switch shown in Fig.9 have the ability to to provide the data vectors arranged in the correct order to and from the processing cores in a single cycle. This data is logically divided into a number of complex―matrix variables‖ of size Nrx by Nrx. When an instruction is executed for a subchannel, the chunk of data associated with the subchannel is retrieved and then delivered to the core-input switch. As shown in Fig.7. The core-input switch is a two level multiplexing circuit that selects and properly arranges the complex vectors needed by the processing core—whether they are row vectors, column vectors, matrix diagonals, or a combination thereof. |
 |
| The memory-input switch performs the same task, but in the reverse direction. It takes the outputs of the processing units and properly packages them so as to write all data associated with the given OFDM subcarrier into the appropriate memory location. |
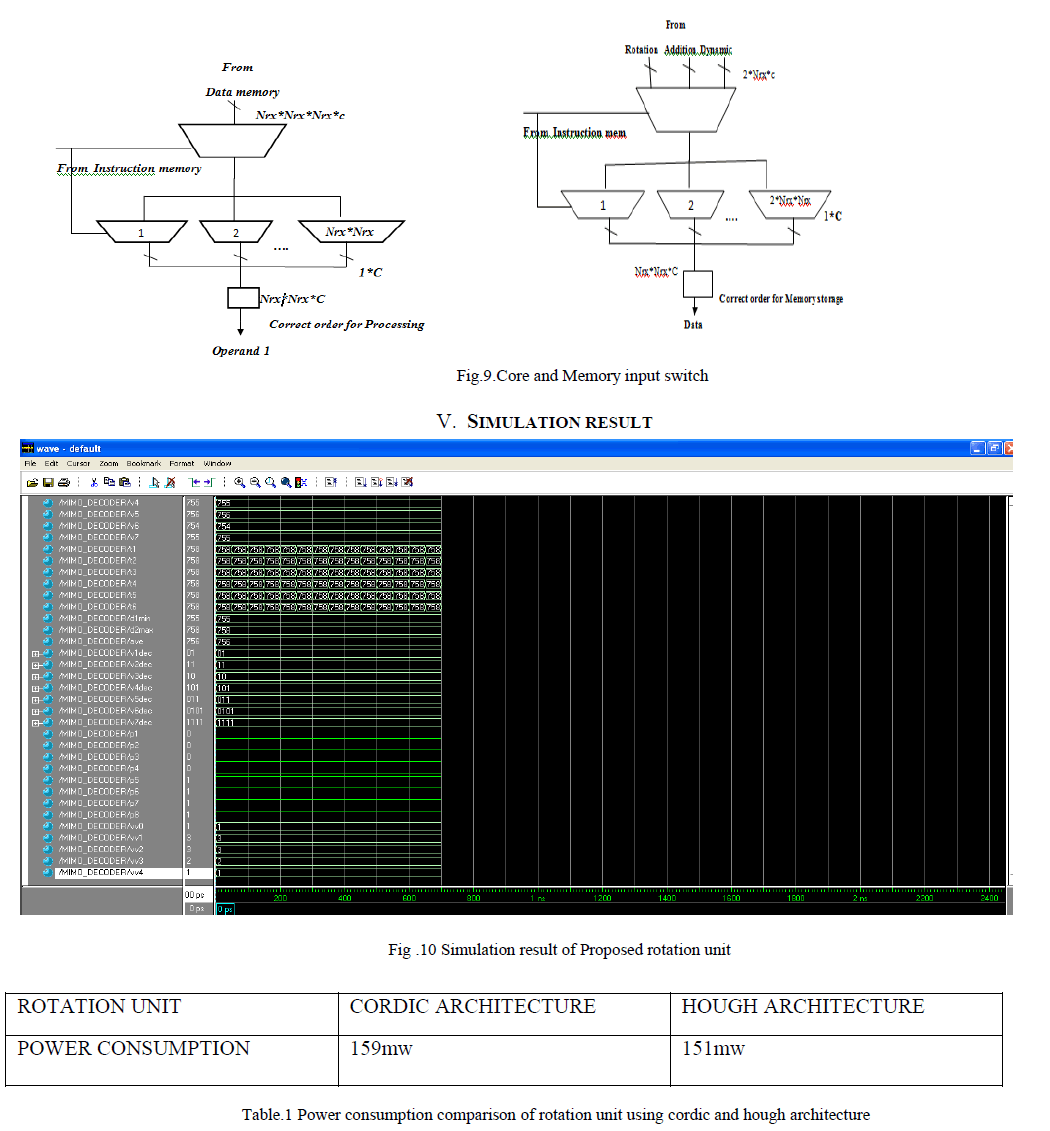 |
| Above Fig.10 shows the simulation result of rotation unit using hough architecture , the results vv1,vv2,vv3&vv4 shows the rotated value and the Table.10 shows the power consumption comparison of CORDIC and HOUGH architecture. |
CONCLUSION |
| This paper presented the ASIC implementation of the reconfigurable MIMO accelerator . The accelerator is fully programmable within the domain of algorithms and functions needed to implement MIMO decoding (MMSE, SVD, QR, etc.) for any arbitrary system or standards (i.e., WiFi, LTE, etc.). The paper presented the hough architecture for the Rotation unit. The power consumption of this architecture was measured to be 151mw.. When compared this with the existing CORDIC architecture, the accelerator energy consumption was 5% less than the existing design. |
References |
|