International Journal of Innovative Research in Science, Engineering and Technology
ISSN ONLINE(2319-8753)PRINT(2347-6710)
ISSN ONLINE(2319-8753)PRINT(2347-6710)
| B.Venkatalakshmi, M.V Shivsankar TIFAC-CORE, Pervasive Computing Technologies, Velammal Engineering College, Chennai, India |
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Innovative Research in Science, Engineering and Technology
Heart disease is a major health problem and it affects a large number of people. Cardiovascular Disease (CVD) is one such threat. Unless detected and treated at an early stage it will lead to illness and causes death. There is no adequate research focus on effective analysis tools to discover relationships and trends in data especially in the medical sector. Health care industry today generates large amounts of complex clinical data about patients and other hospital resources. Data mining techniques are used to analyze this rich collection of data from different perspectives and deriving useful information. This project intends to design and develop diagnosis and prediction system for heart diseases based on predictive mining. Number of experiments has been conducted to compare the performance of various predictive data mining techniques including Decision tree and Naïve Bayes algorithms. In this proposed work, a 13 attribute structured clinical database from UCI Machine Learning Repository has been used as a source data. Decision tree and Naive Bayes have been applied and their performance on diagnosis has been compared. Naive Bayes outperforms when compared to Decision tree.
Keywords |
| Predictive data mining,Naïve Bayes,Decision Tree. |
INTRODUCTION |
| Medical Informatics is the applied science at the junction of the disciplines of medicine and information technology, which provides measurable improvements in both quality of care and effectiveness. Information technologies are playing a crucial role in advancing the science of quality measurement but more can be done to apply it to quality improvement. The Health care provides various services which are used to: (1) improve quality and efficiency; (2) engage patients and families; improve care coordination, and population and public health; and (3) Maintain privacy and security of patient health information. The most predominant health issue is heart failure which occurs especially in old patients because of diet, non-steroidal anti-inflammatory drugs and will leads even towards death. One of the commonly occurred heart diseases is Cardio vascular disease. Thus it is highly essential to predict such diseases through suitable symptoms.There are various types of algorithms which are present for the prediction of heart diseases which are Decision Trees, Naïve Bayes etc. |
| Regrettably all doctors do not possess expertise in every sub specialty and moreover there is a shortage of resource persons at certain places. Therefore, an automatic medical diagnosis system would probably be exceedingly beneficial for bringing the efficient and accurate result. Appropriate computer-based information and decision support systems can aid in achieving clinical tests at a reduced cost. |
| In this work a performance comparison of heart disease diagnosis is executed with the help of Decision tree and Naïve Bayes. The rest of the paper has been organized as follows. Section 2 reviews some of the related works of the proposed solution. Section 3 elaborates various algorithms which are used for diagnosing the heart disease. Section 4 defines the simulation technique called Weka 3.7.9. |
RELATED WORKS |
| Many experiments are being carried out for evaluating the performance of Naïve Bayes and Decision Tree algorithm. The results observed so far indicate that Naïve Bayes outperforms and sometimes Decision Tree. In addition to that an optimization process using genetic algorithm is also being planned in order to reduce the number of attributes without sacrificing accuracy and efficiency for diagnosing the heart disease. |
| There are many possible algorithms for the diagnosis of heart disease which are: |
| A. Naïve Bayes |
| A Naive Bayes classifier predicts that the presence (or absence) of a particular feature of a class is unrelated to the presence (or absence) of any other feature [8]. |
| This classifier is very simple, efficient and is having a good performance. Sometimes it often outperforms more sophisticated classifiers even when the assumption of independent predictors is far. This advantage is especially pronounced when the number of predictors is very large. One of the most important disadvantages of Naive Bayes is that it has strong feature independence assumptions. |
| B. Decision Trees |
| Decision Trees (DTs) are a non-parametric supervised learning method used for classification. The main aim is to create a model that predicts the value of a target variable by learning simple decision rules inferred from the data features. The structure of decision tree is in the form of a tree. Decision trees classify instances by starting at the root of the tree and moving through it until a leaf node. Decision trees are commonly used in operations research, mainly in decision analysis. Some of the advantages are they can be easily understand and interpret, robust, perform well with large datasets, able to handle both numerical and categorical data. Decision-tree learners can create over-complex trees that do not generalise well from the training data is one the limitation. |
| C. Clustering |
| Clustering is a process of partitioning a set of data (or objects) into a set of meaningful sub-classes, called clusters. It helps users to understand the natural grouping or structure in a data set. Clustering is an unsupervised classification and has no predefined classes. |
| They are used either as a stand-alone tool to get insight into data distribution or as a pre-processing step for other algorithms. Moreover, they are used for data compression, outlier detection, understand human concept formation. Some of the applications are Image processing, spatial data analysis and pattern recognition. Classification via Clustering is not performing well when compared to other two algorithms. |
| All these algorithms are implemented with the help of WEKA tool for the diagnosis of heart diseases. Data set of 294 records with 13 attributes. These algorithms have been used for analyzing the heart disease dataset. The Classification Accuracy should be compared for this algorithm. After the comparison attributes are to be reduced for further purpose. |
PRINCIPLES OF PREDICTIVE DATA MINING |
| There are many principles which are used for predicting the heart disease. |
| A. Bayes theorem |
| Bayes rule is used in naive bayes algorithm for the manipulation of conditional probabilities. Bayes' theorem gives the relationship between the probabilities of A and B, P(A) and P(B), and the conditional probabilities of A given B and B given A, P(A|B) and P(B|A). |
| P(A|B)= P(A B)/P(B) (1) |
| B. Entropy |
| Entropy is one of the principles which is used in decision tree and is to measure the amount of information in an attribute and also the impurity. |
| The general formula is: |
| Entropy(S) = Entropy(S)= (-p(I)log2p(I)) (2) |
PARAMETERS OF PDM |
| Some of the parameters [4] which are used for Predictive data mining are |
| A. Sensitivity |
| It is also known as True Positive Rate. It is used for measuring the percentage of sick people from the dataset. |
| Sensitivity = Number of true positives/Number of true positives + Number of false negatives (3) |
| B. Specificity |
| It is also known as True Negative Rate. It is used for measuring the percentage of healthy people who are correctly identified from the dataset. |
| Specificity = Number of true negatives/Number of true negatives + Number of false positives (4) |
| C. Precision and recall |
| It is also known as positive predictive value. It is defined as the average probability of relevant retrieval. |
| Precision = Number of true positives/Number of true positives + False positives (5) |
| Recall |
| It is defined as the average probability of complete retrieval. |
| Recall= True positives/True positives + False negative (6) |
| D. Accuracy |
| A measure of a predictive model that reflects the proportionate number of times that the model is correct when applied to data [11]. |
| The formula for calculating the Accuracy, |
| Accuracy=Number of correctly classified samples/Total number of samples (7) |
| E. Confusion Matrix |
| It is used for displaying the number of correct and incorrect predictions made by the model compared with the actual classifications in the test data. The matrix is represented in the form of n-by-n, where n is the number of classes. The accuracy of each classification algorithms can be calculated from that. |
IMPLEMENTATION |
| The implementation method of the predictive data mining has been described in this paper. |
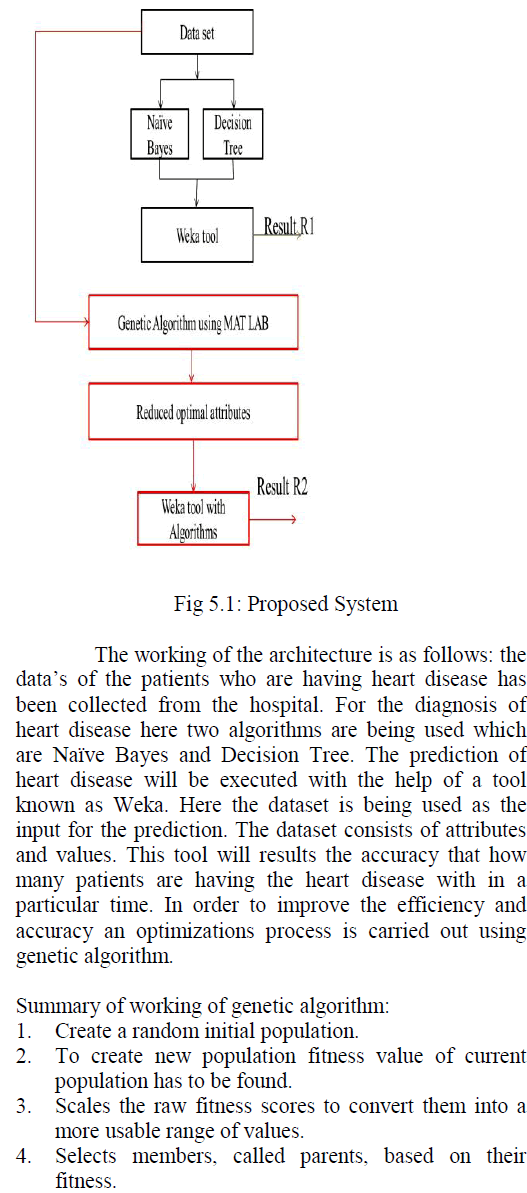
| A. Architecture of PDM: Proposed Approach |
 |
| 5. Some of the individuals in the current population that have lower fitness are chosen as elite. These elite individuals are passed to the next population. |
| 6. Produces children from the parents and the operation is known as crossover. Children are produced either by making random changes to a single parent called mutation |
| The genetic algorithm is being implemented with the help of Matlab. The optimized attributes are fed into Weka tool for the prediction purpose. Hence we will get a conclusion that optimization technique is the best method for improving the prediction of heart disease. |
| The Implementation has been done for finding the accuracy of decision tree and naïve bayes. The optimization part is the future work which is colored in red box. |
| B. DATA SET |
| The data set used in this work is collected from UCI machine learning repository which is a repository of databases, domain theories and data generators. |
| These are the attribute names which is the input given for patients record. |
| The data set attributes which are used in the paper and description as shown in Table 1 |
 |
 |
 |
CONCLUSIONS |
| Many sessions of experiments were conducted with the same datasets in Weka 3.6.0 tool. Data set of 294 records with 13 attributes is used and the outcome reveals that the Naïve Bayes outperforms and sometime Decision Tree. In Future Genetic algorithm will be used in order to reduce the actual data size to get the optimal subset of attribute sufficient for heart disease prediction. Prediction of the heart disease will be evaluated according to the result produced from it. Improvement is done to increase its consistency and efficiency. Benefit of using genetic algorithm is the prediction of heart disease can be done in a short time with the help of reduced dataset. Genetic algorithm will be implemented with the MATLAB. |
References |
|