International Journal of Innovative Research in Science, Engineering and Technology
ISSN ONLINE(2319-8753)PRINT(2347-6710)
ISSN ONLINE(2319-8753)PRINT(2347-6710)
M.Balaganesh1 and N.Arthi2
|
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Innovative Research in Science, Engineering and Technology
Now a days the popularity of social networks like face book, twitter are mostly used by the people. Many of them use human face images to their profile. And also we can maintain large scale database for the image storage. To avoid the large database use two algorithms like attribute enhanced sparse codewords and attribute embedded inverted indexing and used in offline and online storage respectively. In large image database have problem regarding the image retrieval .By using this algorithm we can efficiently retrieve the images from the large image database. It will give the 80% perfect matched images.
Index terms |
| Attribute enhanced sparse codewords, attribute embedded inverted indexing, ranking, attributes, annotation. |
INTRODUCTION |
| To analyze the effectiveness of different human attributes across datasets and find informative human attributes. To sum up, the contributions of attribute enhanced sparse codewords include: In the combine automatically detected high-level human attributes and low-level features to construct semantic codewords. To the best of developer knowledge, this is the first proposal of such combination for content-based face image retrieval. To balance global representations in image collections and locally embedded facial characteristics, in the scalable face image retrieval using attribute enhanced sparse codewords system two orthogonal methods to utilize automatically detected human attributes to improve content-based face image retrieval under a scalable framework. It conducts extensive experiments and demonstrates the performances of the proposed methods on two separate public datasets and still ensures real time response. In the further identify informative and generic human attributes for face image retrieval across different datasets. The selected descriptors are promising for other applications. |
| Automatically detected human attributes have been shown promising in different applications recently. Kumar et al. propose a learning framework to automatically find describable visual attributes. Using automatically detected human attributes, they achieve excellent performance on keyword based face image retrieval and face verification. Siddiquie et al. Further extend the framework to deal with multi-attribute queries for keyword-based face image retrieval. Scheirer et al. propose a Bayesian network approach to utilize the human attributes for face identification. |
LITERATURE SURVEY |
| B.C.Chen et.al [2] developed a scalable face image retrieval system which can integrate with partial identity information to improve the retrieval result. To achieve this goal, B.C.Chen et.al first apply sparse coding on local features extracted from face images combining with inverted indexing to construct an efficient and scalable face retrieval system. Then propose a novel coding scheme that refines the representation of the original sparse coding by using identity information. Using the proposed coding scheme, face images with large intra-class variances will still be quantized into similar visual words if they share the same identity. Experimental results show that the system can achieve salient retrieval results on LFW dataset (13K faces) and outperform linear search methods using well known face recognition feature descriptors. |
| Attributes were recently shown to give excellent results for category recognition. A. Ramisa et al. [3] discuss their performance in the context of image retrieval; show that retrieving images of particular objects based on attribute vectors gives results comparable to the state of the art. A. Ramisa et al. demonstrate that combining attribute and Fisher vectors improves performance for retrieval of particular objects as well as categories. Implement an efficient coding technique for compressing the combined descriptor to very small codes. Experimental results on the Holidays dataset show that our approach significantly outperforms the state of the art, even for a very compact representation of 16 bytes per image. Retrieving category images is evaluated on the “web-queries” dataset. A. Ramisa et al. show that attribute features combined with Fisher vectors improve the performance and that combined image features can supplement text features. |
| Huang, G. [5] discussed about the labeled faces in the wild. Face recognition has benefitted greatly from the many databases that have been produced to study it. Most of these databases have been created under controlled conditions to facilitate the study of specific parameters on the face recognition problem. These parameters include such variables as position, pose, lighting, expression, background, camera quality, occlusion, age, and gender. While there are many applications for face recognition technology in which one can control the parameters of image acquisition, there are also many applications in which the practitioner has little or no control over such parameters. |
| This database is provided as an aid in studying the latter, unconstrained, face recognition problem. The database represents an initial attempt to provide a set of labeled face photographs spanning the range of conditions typically encountered by people in their everyday lives. The database exhibits “natural” variability in pose, lighting, focus, resolution, facial expression, age, gender, race, accessories, make-up, occlusions, background, and photographic quality. Despite this variability, the images in the database are presented in a simple and consistent format for maximum ease of use. In addition to describing the details of the database and its acquisition, we provide specific experimental paradigms for which the database is suitable. This is done in an effort to make research performed with the database as consistent and comparable as possible. |
| For identity related problems, descriptive attributes can take the form of any information that helps represent an individual, including age data, describable visual attributes, and contextual data. With a rich set of descriptive attributes, it is possible to enhance the base matching accuracy of a traditional face identification system through intelligent score weighting. Factor any attribute differences between people into our match score calculation, it can deemphasize incorrect results, and ideally lift the correct matching record to a higher rank position. Naturally, the presence of all descriptive attributes during a match instance cannot be expected, especially when considering nonbiometric context. |
| Retrieval-based face annotation is a promising paradigm in mining massive web facial images for automated face annotation. Such an annotation paradigm usually encounters two key challenges. The first challenge is how to efficiently retrieve a short list of most similar facial images from facial image databases, and the second challenge is how to effectively perform annotation by exploiting these similar facial images and their weak labels which are often noisy and incomplete. Wang, D. et, al. [14] mainly focus on tackling the second challenge of the retrieval-based face annotation paradigm. The propose of an effective Weak Label Regularized Local Coordinate Coding (WLRLCC) technique, which exploits the local coordinate coding principle in learning sparse features, and meanwhile employs the graph-based weak label regularization principle to enhance the weak labels of the short list of similar facial images. |
| Recent work has shown that visual attributes are a powerful approach for applications such as recognition, image description and retrieval. However, fusing multiple attribute scores – as required during multi-attribute queries or similarity searches – presents a significant challenge. Scores from different attribute classifiers cannot be combined in a simple way; the same score for different attributes can mean different things. Scheirer, W et al, [10] show how to construct normalized “multi-attribute spaces” from raw classifier outputs, using techniques based on the statistical Extreme Value Theory. Multi attribute space method calibrates each raw score to a probability that the given attribute is present in the image. It describe how these probabilities can be fused in a simple way to perform more accurate multi attribute searches, as well as enable attribute-based similarity searches. A significant advantage of our approach is that the normalization is done after-the-fact, requiring neither modification to the attribute classification system nor ground truth attribute annotations. It demonstrate results on a large data set of nearly 2 million face images and show significant improvements over prior work. |
| Kumar, N. et al, [6] present two novel methods for face verification. The first method is “attribute” classifiers; it uses binary classifiers trained to recognize the presence or absence of describable aspects of visual appearance (e.g., gender, race, and age). The second method is “simile” classifier; it removes the manual labeling required for attribute classification and instead learns the similarity of faces, or regions of faces, to specific reference people. Neither method requires costly, often brittle, alignment between image pairs; yet, both methods produce compact visual descriptions, and work on real-world images. Furthermore, both the attribute and simile classifiers improve on the current state-ofthe- art for the LFW data set, reducing the error rates compared to the current best by 23:92% and 26:34%, respectively, and 31:68% when combined. For further testing across pose, illumination, and expression, we introduce a new data set – termed PubFig – of real-world images of public figures (celebrities and politicians) acquired from the internet. This data set is both larger (60,000 images) and deeper (300 images per individual) than existing data sets of its kind. Finally, we present an evaluation of human performance. |
| Victor P. et al [13] reviewed a machine learning approach for visual object detection which is capable of processing images extremely rapidly and achieving high detection rates. This work is distinguished by three key contributions. The first is the introduction of a new image representation called the “Integral Image” which allows the features used by our detector to be computed very quickly. The second is a learning algorithm, based on AdaBoost, which selects a small number of critical visual features from a larger set and yields extremely efficient classifiers. The third contribution is a method for combining increasingly more complex classifiers in a “cascade” which allows background regions of the image to be quickly discarded while spending more computation on promising object-like regions. The cascade can be viewed as an object specific focus-of-attention mechanism which unlike previous approaches provides statistical guarantees that discarded regions are unlikely to contain the object of interest. In the domain of face detection the system yields detection rates comparable to the best previous systems. |
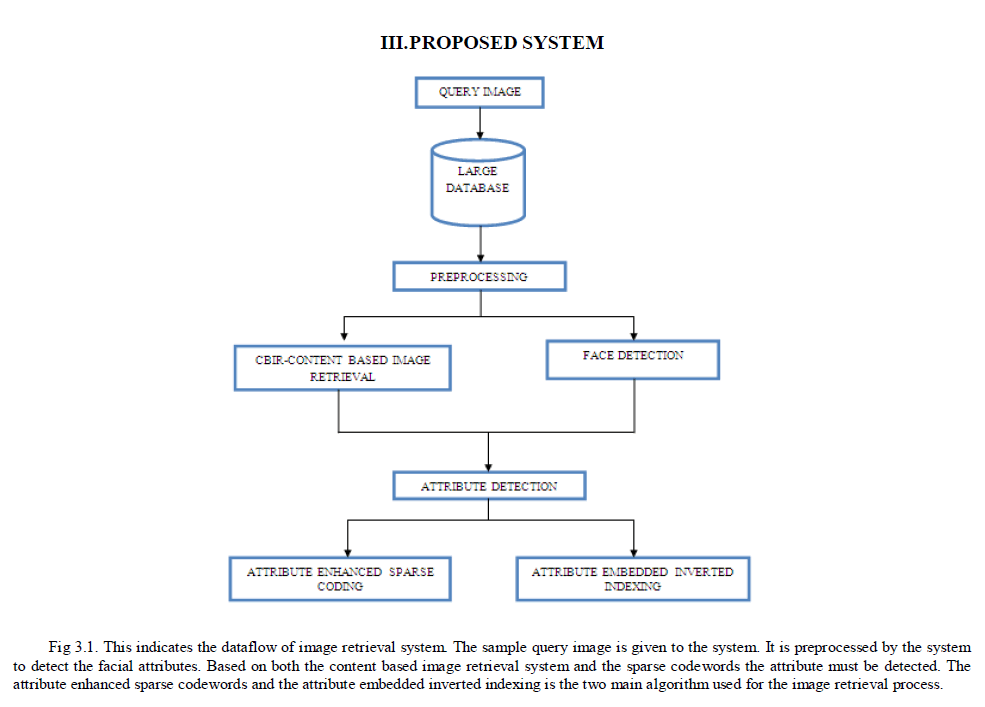 |
| In this proposed system image retrieval process include two more algorithms to efficiently retrieve the image from large image database. The attribute enhanced sparse codewords used in the offline storage. It can generate the codewords to the image in the database. It split the single image into grides and generates the codewords depending upon the attributes. |
MODULES |
| In our system we can maintain 5 modules for image retrieving. First we can get any video from the old or new database. We can mainly consider the video formatted data for frame conversion. Newly recorded video is given into the frame conversion module. The videos are converted into frames depending upon the time. |
Frame Recording |
| A digital video recorder (DVR), sometimes referred to by the merchandising term personal video recorder (PVR), is a consumer electronics device or application software that records video in a digital format to a disk drive, USB flash drive, SD memory card or other local or networked mass storage device. The term includes set-top boxes (STB) with direct to disk recording facility, portable media players (PMP) with recording, recorders (PMR) as camcorders that record onto Secure Digital memory cards and software for personal computers which enables video capture and playback to and from a hard disk. |
| Video encoders, also called video servers, are used to convert signals from analogue cameras and transmit them in IP flow to a network through a switch. While retaining the analogue cameras, they enable a practically complete shift to the network infrastructure for video surveillance since the video is constantly transmitted by IP protocol through the network. |
| Video encoders may be used with network video recorders (NVR). These can only process and record IP video flow. They are offered on an open platform (a computer with video management software) or in dedicated proprietary equipment. In this latter form, the network video recorder is compared to a hybrid digital recorder that requires encoders to operate with analogue cameras. This module mainly deals with recording the videos. Using these videos the unauthorized person is tracked. |
Frames Conversion |
| There are times in a production when the footage only exists in one format and the user needs to use it in another. A common example of that is a 24p project being handed an establishing shot that was shot on dig beta. In this case, the footage is interlace, 60 fields at 30 frames per second while the project type is progressive and 24 frames per second. |
| There are a number of approximations and simplifications that have been made to increase speed. Most importantly, the timing of the algorithm has been changed so that a new background model is only generated once every 40 frames, or 8 seconds, rather than re computing the model for each frame. |
| During the time between model generations, statistics for the background are collected from each frame and processed incrementally. Once 240 frames have been reached, a new background model is computed for use on the next 240 frames. Furthermore, since successive frames tend to be very similar, only every fourth frame is used for statistics collection. Another simplification which increases speed is to only perform background subtraction on a subsampled version of each image. This module deals with converting the video to frames. The video is converted to frames based on time seconds. |
Content-Based Image Search |
| Content-based image retrieval (CBIR), also known as query by image content (QBIC) and content-based visual information retrieval (CBVIR) is the application of computer vision techniques to the image retrieval problem, that is, the problem of searching for digital images in large databases. |
Attribute Based Search |
| Attribute detection has adequate quality on many different human attributes. Using these human attributes, many researchers have achieved promising results in different applications such as face verification, face identification, keyword-based face image retrieval, and similar attribute search. |
Face Image Retrieval |
| In the proposed work is a facial image retrieval model for problem of similar facial images searching and retrieval in the search space of the facial images by integrating content-based image retrieval (CBIR) techniques and face recognition techniques, with the semantic description of the facial image. The aim is to reduce the semantic gap between high level query requirement and low level facial features of the human face image such that the system can be ready to meet human nature way and needs in description and retrieval of facial image.It many consider the attribute within the particular grid. Based on the codewords the images retrieved from the database. Another one. |
| algorithm used for the image retrieval is attribute embedded inverted indexing. It is used set the indexing number to the images. |
RESULTS AND DISCUSSION |
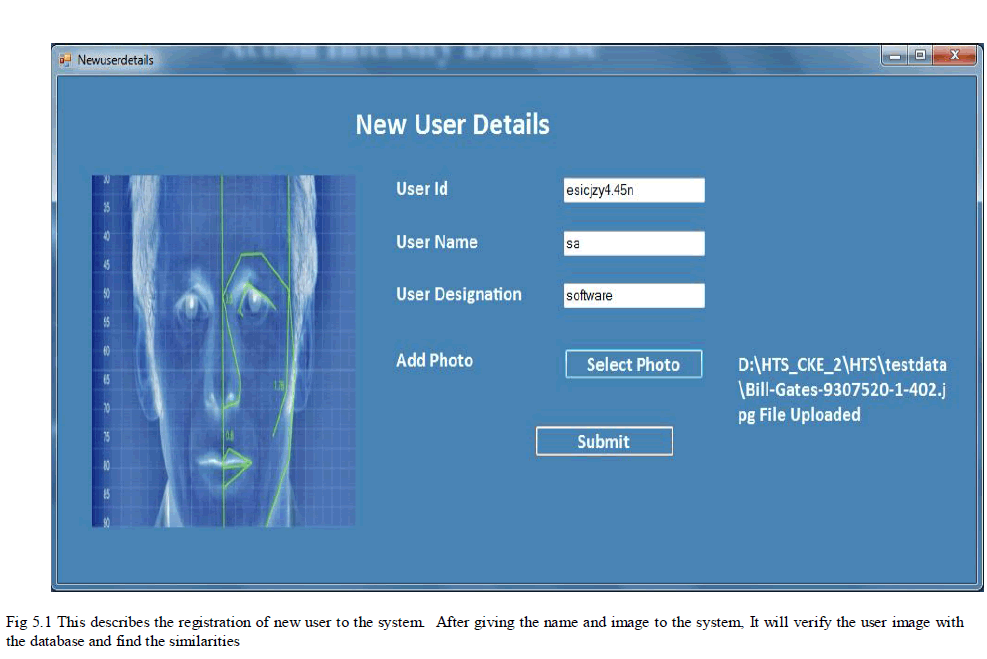
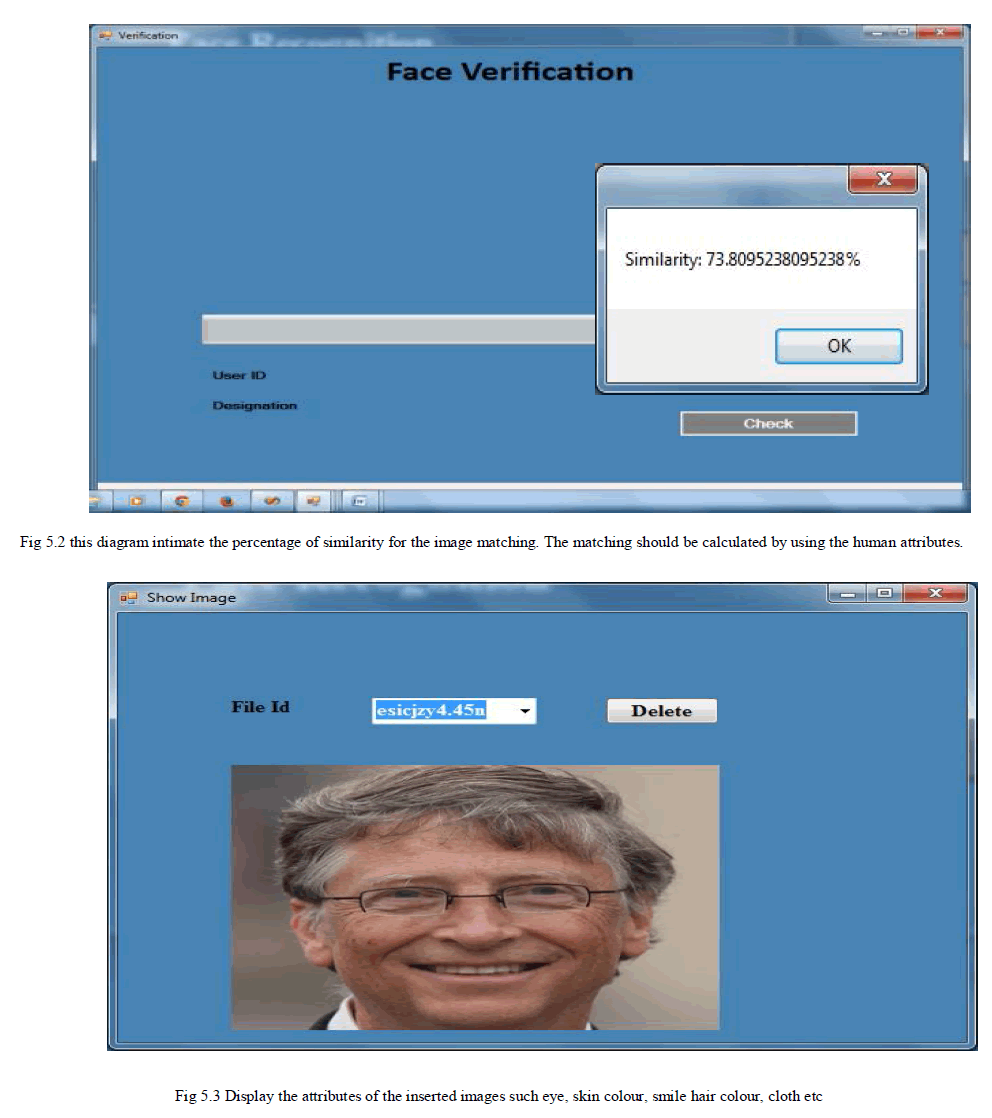
| In this system the videos are converted into many frames. Each and every second of the video will be converted into images. The images are then categorized by the attributes in the face recognition section. The attribute are stored along with the corresponding images to the database. If any new user enters into the system means they should login with new id and also give the profile picture. During the registration the retrieval system verify the new user picture with the existing image database. After that it displays the images which are similar to the picture. If the new image not match with the system means login process will be completed. Otherwise the user cannot enter into the system. Matching process also displays the attributes of the new and old image. And also the percentage of matching process. |
 |
 |
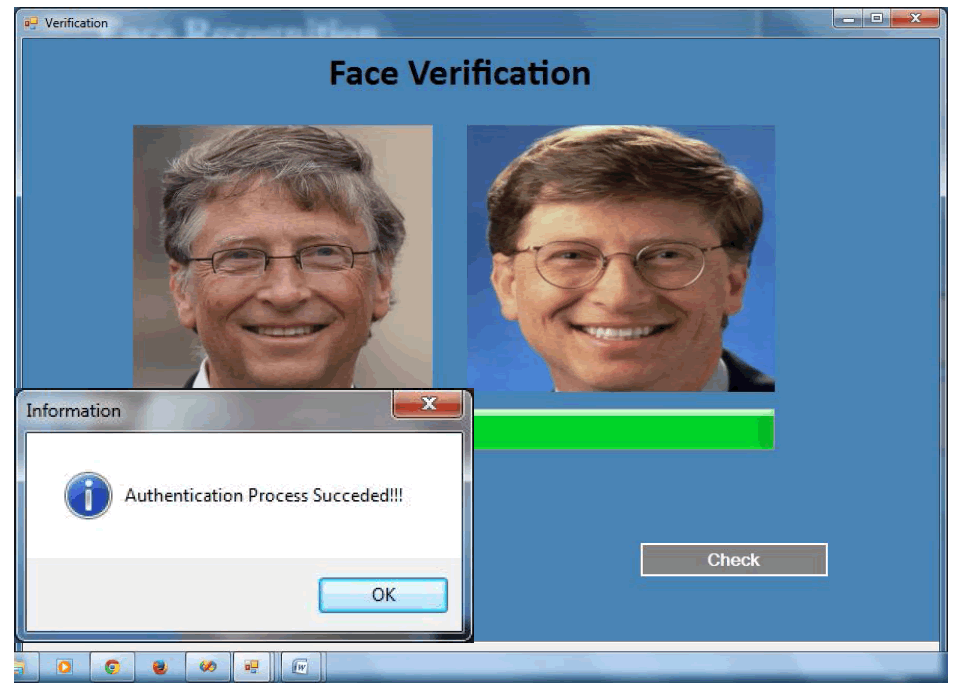 |
| Fig 5.4 after checking the similarity user can enter into the system. If there any image similar to the new image means the user cannot enter into the system |
CONCLUSION |
| The two orthogonal methods used to utilize automatically detected human attributes to significantly improve content-based face image retrieval. This is the first proposal of combining low-level features and automatically detected human attributes for content-based face image retrieval. Attribute-enhanced sparse coding exploits the global structure and uses several human attributes to construct semantic-aware code words in the offline stage. Attribute-embedded inverted indexing further considers the local attribute signature of the query image and still ensures efficient retrieval in the online stage. |