International Journal of Innovative Research in Science, Engineering and Technology
ISSN ONLINE(2319-8753)PRINT(2347-6710)
ISSN ONLINE(2319-8753)PRINT(2347-6710)
Anand M1 and KannigaDevi R2
|
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Innovative Research in Science, Engineering and Technology
Cloud computing is a general term for anything that involves delivering hosted services over the Internet. A Fault tolerance is a setup or configuration that prevents a computer or network device from failing in the event of an unexpected problem or error. In this project work, we propose a model to analyze an optimal fault tolerant strategy to improve the resilience of cloud applications. The cloud applications are usually large scale and include a lot of distributed cloud components. Building highly efficient cloud applications is a challenging and critical research problem. To attack this challenge a component ranking frame work, named FTCloud is used for building fault tolerant cloud applications. First extract the components from the cloud application. Then, rank the critical components using the significance value. After the component ranking phase, an algorithm is projected to automatically conclude an optimal fault-tolerance strategy for the significant cloud components. Thereby, resilience of cloud application can be improved.
Keywords |
| Cloud application, component ranking technique, fault tolerance |
INTRODUCTION |
| Cloud is a general term for anything that involves delivering hosted services over the Internet. It is getting popular in recent years. The software systems in the cloud (named as cloud applications) typically involve multiple cloud components communicating with each of them [1]. Basically cloud applications are usually huge and very complex. Regrettably, the reliability of the cloud applications is still far from perfect in real life. The requirement for highly reliable cloud applications is becoming unprecedented strong. Building highly efficient clouds becomes a critical, challenging, and urgently required research problem. The trend toward large-scale complex cloud applications makes developing fault-free systems by only employing fau lt-prevention techniques and fault-removal techniques exceedingly difficult. Another approach for building efficient systems, software fault tolerance [20], makes the system more robust by faults masking without removing it. One of the most well known software fault tolerance techniques is to employ functionally equivalent yet independently designed components to tolerate faults [5]. Due to the cost of developing and maintaining redundant components, software fault tolerance is usually only employed for critical systems. Different from traditional software systems, there are a lot of redundant resources in the cloud environment, making software fault tolerance a possible approach for building highly reliable cloud applications. Since cloud applications usually involve a large number of components, it is still too expensive to provide alternative components for all the cloud components. Moreover, there is probably no need to provide fault tolerance mechanisms for the non critical components, whose failures have limited impact on the systems. To reduce the cost so as to develop highly reliable cloud applications within a limited budget, a small set of critical components needs to be identified from the cloud applications. By tolerating faults of a small part of the most important cloud components, the cloud application reliability can be greatly improved. Based on this idea, we propose FTCloud, which is a component ranking framework for building fault tolerant cloud applications. the optimal fault-tolerance strategies for these significant components automatically. FTCloud can be employed by designers of cloud applications to design more reliable and robust cloud applications efficiently and effectively. |
| Contribution of this paper: |
| This paper identifies the critical problem of locating significant components in complex cloud applications and proposes a ranking-based framework, named FTCloud, to build fault-tolerant cloud applications. We first propose ranking algorithms to identify significant components from the huge amount of cloud components. Then, we present an optimal fault-tolerance strategy selection algorithm to determine the most suitable fault-tolerance strategy for each significant component. We consider FTCloud as the first ranking-based framework for developing fault-tolerant cloud applications. |
| We provide extensive experiments to evaluate the impact of significant components on the reliability of cloud applications. |
RELATED WORK |
| Component ranking is an important research problem in cloud computing [41], [42]. The component ranking approaches of this paper are based on the intuition that components which are invoked frequently by other important components are more important. Similar ranking approaches include Google Page rank [7] (a ranking algorithm for web page searching) and SPARS-J [16] (software product retrieving system for Java). Different from the Page Rank and SPARS-J models, component invocation frequencies as well as component characteristics are explored in the approaches. Moreover, the target of approach is identifying significant components for cloud applications instead of web page searching (Page Rank) or reusable code searching (SPARS-J). |
| Cloud computing [3] is being popular. The works have been done on cloud computing, including identifies the critical to address fault tolerant strategy [32], identifies the effects of failures on user’s applications, and surveying fault tolerance solutions corresponding to each class of failures [9], Too inadequate or too expensive to fit their individual requirements [34], etc. In recent years, a great number of research efforts have been performed in the area of service component selection and composition [30]. Various approaches, such as QoS-aware middle ware [38], adaptive service composition [2], and efficient service selection algorithms [37], have been proposed. Some recent efforts also take subjective information (e.g., provider reputations, user requirements, etc) to enable more accurate component selection [27]. Instead of employing non functional performance (e.g., QoS values) or functional capabilities, the approaches rank the cloud components considering component invocation relationship, invocation frequencies, and component characteristics. |
SYSTEM ARCHITECTURE |
| Fig.1shows the system architecture of the fault-tolerance framework (named FTCloud), which includes two parts: 1) ranking and 2) optimal fault-tolerance selection. The procedures of FTCloud are as follows: |
| 1. The system designer provides the initial architecture design of a cloud application to FTCloud. A component extraction can be done for the cloud application based on the weight value. |
 |
| 2. Significance values of the cloud components are calculated by employing component ranking algorithms. Based on the significance values, the components can be ranked. |
| 3. The most significant components in the cloud application are identified based on the ranking results. |
| 4. The performance of various fault-tolerance strategy candidates is calculated and the most suitable fault-tolerance strategy is selected for each significant component. |
| 5. The component ranking results and the selected fault-tolerance strategies for the significant components are returned to the system designer for building a reliable cloud application. |
PROPOSED WORK |
SIGNIFICANT COMPONENT RANKING: |
| The target of significant component ranking algorithm is to measure the importance of cloud components based on available information (e.g., application structure, component invocation relationships, component characteristics, etc.).The significant component ranking includes three steps (i.e., component Extraction, component ranking, and significant component determination) |
Component Extraction: |
| A cloud application can be modeled as a weighted, where a node c i represents a component and a directed |
 |
| 1. Randomly assign initial numerical scores between 0 and 1 to the components |
| 2. Compute the significance value for a component c i by: |
 |
 |
Significant Component Determination |
| The components of cloud application can be ranked based on obtained significance value and the top k (1 ≤k ≤n) most significant components can be returned to the cloud application’s designer. After that significant components can be obtained by the designer of cloud application at a time of architecture design and can employ various techniques to improve the resilience of the cloud application. |
FAULT-TOLERANCE STRATEGY SELECTION |
Fault-Tolerance Strategies |
| Software fault tolerance is widely adopted to increase the overall system reliability in cloud applications. Applying functionally equivalent components to tolerate component failures, thereby resilience can be improved. There are three most common fault-tolerance methods with formulas to find out the failure probabilities of the each fault-tolerant method. The failure probability should be within the range of [0,1]. |
Recovery block(RB). |
| Execute a component, if fails through acceptance test, then try a next alternate component. Order the different component according to reliability. Checkpoints needed to provide valid operational state for subsequent versions (hence, discard all updates made by a component). Acceptance test needs to be faster and simpler than actual code. A recovery block fails only if all the redundant components fail. |
| The failure probability f of a recovery block : |
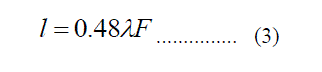 |
| The optimal fault-tolerance method selection problem for a cloud component with user constraints can then be formulated mathematically. First, the candidates which cannot meet the user constraints are not include. Then the fault-tolerance candidate with the best failure probability performance will be selected as the optimal strategy for component i. By the above approach, the optimal fault-tolerance method, gives the best failure probability performance and fulfill all the user constraints. |
| To identify optimal FT Strategy Selection: |
 |
| The above algorithm identifies optimal FT strategy selection for each of significant component. Based on result the designer have to apply the identified FT strategy, thus resilience of the cloud application can be improved. |
EXPERIMENT |
Experimental Setup |
| The significant component ranking algorithms are implemented by java language using cloudsim tool based on hundred nodes. To find out the performance of reliability increment, we compare four approaches, which are as follows: |
| No FT: No fault-tolerance strategies are employed for the components in the cloud application. |
| Random FT. Fault-tolerance strategies are employed to mask faults of K percent components, those components are randomly selected. |
| FTCloud: Fault-tolerance strategies are employed to mask faults of the Top-K percent important components (using significance value). The components are ranked based on the structural information of the cloud application. |
| AllFT: Fault-tolerance strategies are employed for all the cloud components. |
COMPONENT FAILURE PROBABILITY IMPACT |
| To learn the impact of the system resilience on cloud application, we compare RandomFT and FTCloud under probability set from 0.1 to 1 percent with a step value of 0.1 percent. Thousands node are taken for this execution. Implementation result shows cloud application failure probabilities Fig. 3. |
 |
| Fig. 3 explains FTCloud outperform RandomFT in all the application running time settings from 1 percent constantly as shown in Fig. 3 |
| The system resilience probabilities of the two methods become larger, when application runs. To build highly reliable cloud applications, then a larger number of significant components are needed. |
| The application failure probability of FTCloud approach decreases much faster than that of RandomFT, representing that have a more efficient use of the redundant components than RandomFT, by the increase the selection of more significant components. |
CONCLUSION AND FUTURE WORK |
| This paper proposes a component ranking framework cloud application’s component. The significance values of these components, how often the current component is called by other components, and the component quality. |
| After determine the significant components, we suggest an optimal fault-tolerance strategy selection algorithm to afford optimal fault-tolerance strategies to the significant components automatically, based on the user limits. The implementation results display the FTCloud approaches. |
| The current FTCloud framework can be engaged to bear crash and significance faults. In the future, we will examine more types of faults, such as Byzantine faults. Various types of fault-tolerance mechanisms can be extra into FTCloud framework effortlessly without Basic changes. We will also examine additional component ranking algorithms and add them to the FTCloud framework. Moreover, we will expand and practical FTCloud framework to other component-based systems. |
| In this paper, we only learn the most delegate type of software component extraction, i.e., weight value of an edge. as different applications may have dissimilar system structures, we will examine more types of component models in future work. |
| The future work also includes |
| • Allow more factors (such as invocation delay, output, etc.) when computing the weights of invocations links; |
| • Examining the component consistency itself moreover the invocation structures and invocation frequencies; |
| • More investigational testing on real-world cloud applications. |
| • more examination on the component malfunction correlations; and |
| • More new studies on collision of incorrectness of prior wisdom on the invocation frequencies and essential components. |
References |
|