International Journal of Innovative Research in Science, Engineering and Technology
ISSN ONLINE(2319-8753)PRINT(2347-6710)
ISSN ONLINE(2319-8753)PRINT(2347-6710)
Ms.Jyoti Pathak1, Mr.Rakesh Pandit2, Mr. Sachin Patel3
|
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Innovative Research in Science, Engineering and Technology
Apposite to the impenetrability in judgment real indecisive data, obtainable works on indecisive data mining simply employ whichever synthetic datasets or real datasets with synthetically produce probability value. This presents these mechanisms a mostly hypothetical flavour, wherever appliance domain is theoretical. In dissimilarity, in this paper the primary challenge to be appropriate indecisive data mining method real world appliance such as noise classification and clustering. Moreover, beyond the creation of indecisive features, this methodology is domain independent and consequently could be effortlessly extensive and estimate in other domains. In this research, we exploit the regularize framework and proposed an associative classification algorithm for uncertain data. The major recompense of SVM (support vector machine) is: recurrent itemsets capture every the dominant associations between items in a dataset. These classifiers naturally handle missing values and outliers as they only deal with statistically significant associations which build the classification to be vigorous. Extensive performance analysis has exposed such classifiers to be recurrently more precise. We proposed a novel indecisive SVM Based clustering algorithm which considers large databases as the major application. The SVM Based clustering algorithm will cluster a specified set of data and exploit the matching other works
Keywords |
| support vector machine, indecisive data, associative classification, fuzzy clustering |
INTRODUCTION |
| The digital insurrection has completed achievable that the data incarcerate be effortless and its storage have a almost null cost. As a substance of this, huge amount of extremely dimensional data are stored in databases incessantly. Due to this, semi-automatic technique for classification from databases is necessary. Support vector machine (SVM) is a dominant method for classification and regression. Training an SVM is frequently posed as a quadratic programming (QP) problem to discover a partition hyper-plane which associates a matrix of density n×n, where the n is the quantity of points in the data set. This requirements huge quantity of computational time and memory for large data sets, so the training Complexity of SVM is highly dependent on the size of a data set [1][5] a lot of efforts have been made on the classification for huge data sets. Sequential Minimal Optimization [12] convert the large QP difficulty into a series of diminutive QP problems, every one engage merely two variables [4][6]. [8] Converse large scale estimate for Bayesian inference for LS-SVM. The results of [7] demonstrate that a fair computational improvement can be acquire by means of a recursive strategy for large data sets, such as individuals concerned in data mining and text classification relevance. Vector quantization is useful in [8] to decrease an enormous data set by restore instance by prototypes. Training time for choose optimal parameters is considerably determined. Recommend a method based on an incremental learning method and a multiple proximal SVM classifier. Random Selection [2] is to choose data such that the knowledge is make the most of though; it could make simpler the training data set, misplace the remuneration of SVM, especially if the probability allocation of the training data and the testing data are dissimilar. On the other hand, unsupervised classification, called clustering is the classification of comparable objects into dissimilar collection, or furthers precisely, the separation of a data set into subsets (clusters), so that the data in every subset (ideally) contribute to various frequent traits. The objective of clustering is to split a restricted unlabelled data set into a restricted and discrete set of “natural,” hidden data structures. a quantity of consequences [1] illustrate that clustering method can facilitate to reduce complexity of SVM training. But, they necessitate further estimate to build the hierarchical structure. In this paper we propose a new approach for classification of large data sets, named SVM classification. In dividing wall, the quantity of clusters is pre-defined to keep away from computational cost for formative the optimal number of clusters. We merely segment the training data set and to eliminate the set of clusters with minor probability for support vectors. Based on the obtain clusters, which are distinct as mixed category and consistent category, we mine support vectors by SVM and form into concentrated clusters. Then we be appropriate de-clustering for the concentrated clusters, and acquire subsets from the innovative sets. in conclusion, we use SVM again and conclude the classification. An experiment is certain to demonstrate the efficiency of the new approach. The structure of the paper is organized as follows: |
II.RELETED WORKS |
| Indecisive data mining magnetize much concentration freshly. Numerous examine efforts focus on frequent itemset mining various algorithms have been proposed for definite data classification L. Manikonda in at [1] they was developed a new associative classifier which can be used for classification of images represented in the form of uncertain data records. This algorithm directly classifies positive class and negative class test images without any need of training the classifier on negative class dataset. By identifying the inefficiency of the traditional bag of words model, they have developed a modified bag of words model which helped in classifying positive. Metanat Hooshsadat and Osmar R. Z [2] probabilities attached to each attribute value. They was addresses the problem of devising an accurate rule-based classier on uncertain training data. There are many classification paradigms but the classifiers of interest to our study are rule-based. Opted for associative classifiers, classifiers using a model based on association rules, as they were shown to be highly accurate and competitive with other approaches. Michael Chau in at al [3] presents a framework for possible research directions in this area. They was also present the UK-means clustering algorithm as an example to illustrate how the traditional K-means algorithm can be modified to handle data uncertainty in data mining Charu C. Aggarwal in at al[4]focus on the frequent itemset mining on uncertain data sets. they was extended several existing classical frequent itemset mining algorithms for deterministic data sets, and compared their relative performance in terms of efficiency and memory usage. Note that the uncertain case has quite different trade-offs from the deterministic case because of the inclusion of probability information. Jiye Liang in at al[5]proposed feature selection for large-scale data sets is still a challenging issue in the field of artificial intelligence for large-scale data sets, they was developed an accelerator for heuristic feature selection and an efficient rough feature selection algorithm. In addition, an efficient group incremental feature selection algorithm was also introduced for dynamic data sets. |
III. PROPOSED METHODOLOGY |
| Building a classifier involves two steps: Primary Training: throughout the training phase, a classification replica is constructed and accumulated on disk. The individual objects or illustration are referred cooperatively as training dataset. Before construction the replica, this training set should be classified to add a class label to every object or instance. This replica can be put up using different classification method which comprise, Decision trees, Associative classifiers, Bayesian methods, Support vector machines (SVM), etc. Secord Testing: In this stage, the replica construct in the earlier step is used for categorization. Initial, the predictive accuracy of the classifier is anticipated. A test set which is complete up of test tuples and their connected class labels is used to determine it. These tuples are arbitrarily chosen from the universal data set and are not implicated while construction the classification replica previous. Classification method was developed as a significant constituent of machine learning algorithms in organize to mine rules and patterns from data that could be used for prediction. Dissimilar technique from machine learning, statistics, information retrieval and data mining are used for classification. They comprise Bayesian technique, Bayesian belief networks, Decision trees, neural networks, Associative classifiers, Emerging patterns, and SVM. SVM Based Amongst these associative classification has expanded a lot of attractiveness because of it’s the numerous reward given below Association rules incarcerate all the prevailing relationships between items in a dataset Low-frequency patterns are reduce at an premature stage before construction the classifier Classification replica is robust because of the statistical implication of associations between the item. Standardize Data creation: The standardize creation of data is described and our present the same briefly in the circumstance of classification. Given the positive class training dataset ARtr, the primary step in our algorithm is to extract dissimilar separate vectors. K-means clustering algorithm is used to cluster all the generated separate vectors Stotal for the training dataset. It produce a clustering C which has k quantity of dissimilar clusters – c1, c2, c3, ck after clustering, each ARtr . AR is characterizing in the customized form of where every expression represent the cluster associated with a fraction value. Choose the quantity of clusters while collect is also an important step. Since, lesser the quantity of clusters, extra is the loss of information concerning indecisive data which is also the same in case of higher number of clusters. Hence, decide the most favourable number of clusters is significant. In our algorithm while testing we have used the number of clusters based on the dataset measured. Indecisive Associative Classifier Training: the majority of the algorithms instruct their particular classifier with positive class and negative class datasets. But in Indecisive Associative Classifier Training, only a positive-class dataset is used for training the classifier. The primary step in training is to produce association rules for the indecisive replica. For produce the indecisive association rules, we contain used an indecisive algorithm which relies on the separation approach. The main reason for building an uncertain associative classifier instead of a traditional associative classifier is to handle the fraction value associated with the cluster identification in the customized model. After the creation of association rules, entropy and in sequence expand are intended for each rule produce. Given a rule aÃÂÃâ b, a is an itemset collected of unreliable numeral of attributes and a is the class label of the rule which is discover from the dataset. The probability of a is consider to be the maximum probability of all the attributes in each rule. The SE (aw, b) of a specified quality a with respect to the class attribute b is the decrease in indecision concerning the value of b when we recognize the value of b. Algorithm 1. Indecisive Associative Classifier Training Algorithm, produce a large set of rules (ARC), a lot of which are derelict. Reduce technique are used in organize to progress the efficiency. For the pruning process, SE of each rule ARi and rule length ARi., quantity of attributes in every rule ARw is evaluate to every one ARw+1 to ARw rules. A given rule ARw is prune (ARC= ARCÃÂÃâ ARw) if present exist another rule ARw with in sequence expand SEo and rule length ARLo) which is a superset of ARw, and ARLo |
 |
| Classification is complete by with a set of indecisive classification rules derivative during We increase this importance with the information gain SE (ARo) linked with the rule ARo as shown in figure 1 and consider this acquire consequence as the indecisive in sequence expand ARo. We compute the indecisive in sequence expand obtain while be appropriate every rule in the rule set ARC and append the ideals as shown figure1. This is the entirety indecisive in sequence expand which is established with a threshold –. If the value indecisive in sequence expand is superior than or equivalent to –, then the belong to the positive class or else it belong to the negative class. |
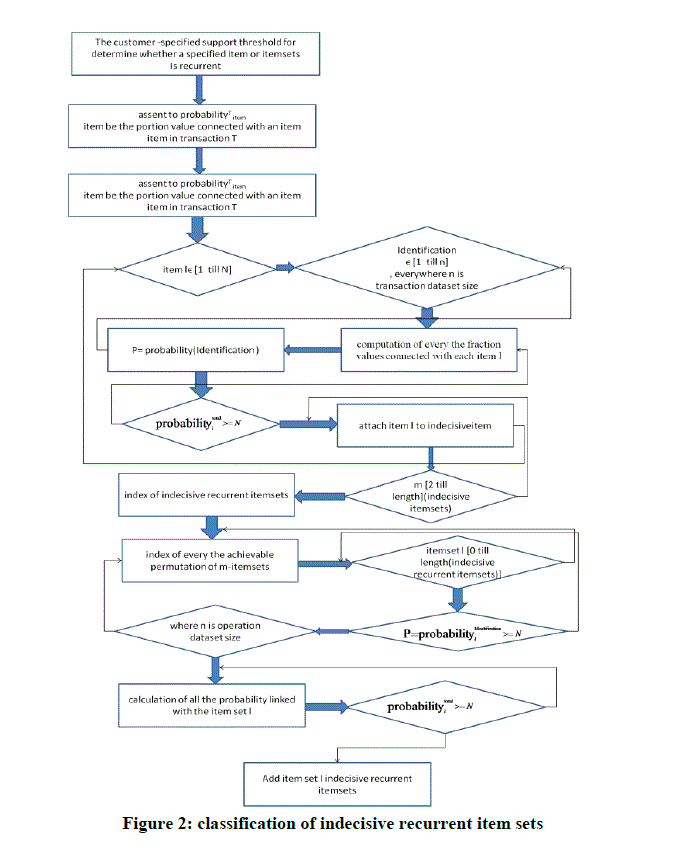
IV.CREATION OF INDECISIVE NUMEROUS ITEMSET TRANSACTION |
| Dataset A set of indecisive recurrent itemsets (iri) is identified in figure 2. As the subsequent step, each itemset in iri is measured as a innovative transaction. Using all these indecisive recurrent itemsets, a new transaction dataset is produce. Every recurrent itemset is one of the cluster-ids used in replica R. recognize all the dataset which enclose all the recurrent itemsets when characterize them as in replica R. Each of these dataset associated with a probability importance that is considered from the personage probabilities associated with every of the cluster ids. Statistical illustration of manipulative the probability value can be seen in every of the indecisive recurrent itemset (iri) is transformed. The entire procedure of generate recurrent itemset transaction dataset is give details figure 2. Clustering of datasets. Generate dataset indecisive recurrent itemsets is used for the concluding clustering where similar datasets are grouped into a same cluster. Illustration of iri can be seen in Figure 2 which is transformed to a expedient replica as exposed in that acts as an input for clustering algorithm. |
V.CLASSIFICATION OF INDECISIVE RECURRENT ITEM SETS |
| The major intend of indecisive data classification is to categorize a specified indecisive dataset which engage probability. Traditional classification approach cannot handle indecision. The presentation and excellence of classification results are mostly needy on whether data indecision is properly modelled and procedure. An instinctive method of behaviour indecision is to renovate the value to a predictable value and delicacy it as a definite data and then execute classification. In universal to handle improbability, advance that use probability density functions, improving activation function in neurons to handle uncertain values, etc., were developed. |
 |
| Data clustering on indecisive data using the traditional techniques might change the nature of clusters because of the occurrence of indecision. For clustering, there are numerous resemblance metrics which are used to assembly an item with other items. In case of indecisive data, if the distance function is used as a resemblance metric, its computation will be exaggerated by indecision. There are new metrics like distance density function, reach ability probability which are used as fraction of a density based clustering of indecisive data. a number of technique that are extensive from the clustering method for confident data are developed These developed techniques modify the significant metrics which deal with the similarity of data and transform them in such a way that they can handle indecision. |
VI. CONCLUSION |
| In this paper, we developed an innovative classifiable technique for large data sets. We proposed a novel indecisive SVM Based clustering algorithm which considers large databases as the major application. The SVM Based clustering algorithm will cluster a specified set of data and exploit the matching proposed other works. It takes the compensation of the SVM. The algorithm proposed in this paper has a similar idea as the sequential minimal optimization (SMO), i.e., in order to work with large data sets, we separation the original data set into several clusters and reduce the size of QP problems. |
ACKNOWLEDGMENT |
| We would like to express our gratitude to all those who gave us the possibility to complete this paper. We want to thank the Information Technology of the Patel College of Science and Technology for giving me permission to commence this paper in the first instance, to do the necessary research work and to use departmental data. We are deeply indebted to our Master of Engineering supervisor Mr. Sachin Patel from the IT Department PCST whose help, stimulating suggestions and encouragement. We are also thankful to Mr. Rakesh Pandit for his guidance. |
References |
|