International Journal of Innovative Research in Science, Engineering and Technology
ISSN ONLINE(2319-8753)PRINT(2347-6710)
ISSN ONLINE(2319-8753)PRINT(2347-6710)
S.Visalakshi1, V.Radha2
|
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Innovative Research in Science, Engineering and Technology
In real-time dataset, lots of missing values are prompt and habitually become a very serious problem in data mining. A dataset with missing value becomes a general problem of data quality. Some sort of missing data are present moreover in training set or testing set which will affect the accuracy of any learned classifiers. Handling of missing data is very significant, as they have a pessimistic blow on the interpretation and the result of data mining process. Handling of missing value techniques can be grouped into a bunch of four categories namely, Imputation methods, Maximum Likelihood, Machine Learning and Complete Case Analysis. The KNearest Neighbor (KNN) is one of the imputation techniques used to treat missing value. The drawback of KNN is overcome in the proposed KNN. The proposed technique is implemented and used for identify contamination in drinking water. Missing value is implemented in the water dataset. It helps to improve automatic water contamination detection scheme. Some of the existing and popular imputation techniques are compared, and it is proved that the proposed system produces better results compared to other imputation techniques.
Keywords |
| Potable water, Missing value handling, Imputation, Hot deck, Mean, K-Nearest Neighbor, Contamination detection, Data Pruning. |
INTRODUCTION |
| The process of mining hidden knowledge from database is called data mining. Data mining is capable of extracting hidden patterns from the dataset, predicting the future |
| trends and knowledge driven decision. Water is one of the natural resources used by all living and non-living beings. Potable drinking water is safe and sound enough to be consumed by humans. The potable water supplied to households, commerce and industry meet drinking water standards [1]. In many parts of the world, it is difficult to access potable water and the public are still using contaminated water for daily routine. As the use of nonpotable water for food preparation leads to widespread acute and chronic illnesses, it has become a major cause of death and misery in many countries. In developing countries, reduction of waterborne disease is a major goal. Contamination can be intentional and non- intentional [2]. The main goal of the research is to identify the contamination present in drinking water. |
| Real-life data is surrounded by noise, is inconsistent and is incorrect. Many existing industrial and research data contains missing values. Data preparation, cleaning and transformation comprise the majority of work in all kinds of data mining applications. The major task in data pre-processing is Data Cleaning (filling in missing values, smoothing noisy data, identifying or removing outlier and resolving variation), Data Integration (integrating the database from multiple sources (n-number of databases, data dice or documents), Data Transformation (process normalization and aggregation), Data Reduction (reduce the volume but no change in analytical results) and Data Discretization (reduction in part of the dataset especially for numerical datasets). The reason for missing value includes manual data entry, equipment errors and incorrect measurements. In real time, missing value handling is categorized into four groups, namely, Complete Case Analysis, Imputation Methods, Maximum Likelihood Method and Machine Learning Methods. The most common problem faced in data mining and database is missing values. If the missing value rate is <1% then it can be trivial, 1-5% is manageable, 5-15% need some sophisticated methods to handle missing values and if the missing value rate is > 15% then the dataset must be handled carefully with sophisticated tools [3]. Missing values may generate bias and affect the quality and performance of the classification algorithm. In this paper, experimental and research work concentrates on handling missing values of the real time data which are collected from distribution point. Sample water is collected from different distribution points for detecting contamination and the data contains many missing values. This paper focuses on handling missing value and removing outlier (anomalies) from the data. The experimental result of this paper gives information on how the missing value and outlier detection is performed. Imputation means replacing a new value wherever the data is missing in the database. [12]. According to Pedro J.et.al, the KNN imputation method search for more similar instances in the entire dataset. Hence, it takes more time for finding similar instance. (To find new value for the replacement of missing value).To overcome this problem, clustering is introduced to search a neighbor value for replacement, and it is illustrated with an example of real-time data. The performance of the proposed algorithm has been compared with existing imputation techniques and it performs very well. Also the result shows improvement. In Section II the literature study is discussed and in Section III the proposed techniques are explained. Section IV reports the experimental results of the enhanced KNN imputation technique. Finally, Section V presents the conclusion and scope for future study. |
LITERATURE STUDY |
| The first task of data mining is pre-process of the data. Missing attribute values becomes more common problem in real world data sets. The most important task in data pre-processing is to find the missing attribute values. Missing values occur during data collection, repeated diagnosis test, experimental set and so on. Several studies have been focused on developing algorithms that deal with missing data [4, 5, 6].Generally, missing values in data mining are handled using the following three different ways: |
| ïÃâ÷ Discard the missing attribute value, |
| ïÃâ÷ Maximum likelihood approaches, and |
| ïÃâ÷ Imputations of missing attribute value. |
| Jerzy W. Grzymala-Busse and Witold J. Grzymala- Busse analyzed the two different methods of handling missing values. They are sequential and parallel methods [7]. Insequential method, missing value is replaced with known value, but in the parallel method knowledge is retrieved directly without imputing the missing values from the original dataset. Sequential methods include deleting cases with missing attribute values, replacing missing attribute value with the most common value of attributes, assigning all possible values for missing attribute, replacing the mean value of the numerical attribute, closest fit case, etc. In parallel method, missing value will be considered during the process of acquiring knowledge. The method includes Learning from Examples Module, Version 2 (LEM2), C4.5 (“don’t care”) and CART. Also, the author presents the work based upon the percentage of missing values. The handling of missing value techniques varies from one dataset to another dataset. To handle the missing attribute values, the best possible methods or universal methods should be preferred, using the criterion of optimality and multi-fold cross validation experiments. |
| Yoshikazu Fujikawa and TuBao Ho, analyze the existing methods to deal with missing attribute values and the report is given along with evaluation of processing cost and quality of imputing missing values. Three new cluster based methods are also proposed to impute missing values and the result shows that proposed clusterbased algorithm works effectively [8]. |
| Hai Wang and Shouhong Wang propose a framework for rough set rule generation method which will enable the user to mine patterns to attain an association rule. The author also proposes four different approaches to deal with missing data [9]. The first approach for missing value is to eliminate all the missing value from the dataset. The second approach is to estimate the missing value in the dataset (Imputation). The third approach is to use common “unknown attribute value” for missing data. The fourth approach is treating the missing data as nondeterministic data. Pattern of missing data is also discussed briefly, through associated rule induction. A general pattern of missing data includes set-off, closing; hiding and disclosing are expressed by prototypes of association rules. Rough sets rule induction technique is a powerful tool for discovering knowledge. |
| Fourteen different imputation approaches for classification are presented [10]. The following three different problems arise with missing values in data mining. They are loss in effectiveness; obstacle in handling and investigate the data; unfairness resulting from differences between missing and complete data. If the dataset is having any incomplete data either in the training set or in testing set and might be present in both (training and testing), it is sure that prediction accuracy of the classifier is degraded. Three sections of classification are used to categorize them and examine the best imputation strategies. The literature study for classification with various imputation methods is investigated and comparison is made for different imputation methods. This concludes that imputation method helps to fill the missing value better than the case deletion method. |
| Bhavisha.et.al explains about imputation methods like Parametric, Non-Parametric and Semi-Parametric methods [11]. |
| A novel KNN imputation using feature weighted distance, based on mutual information, was proposed by [13], which helps to improve the classification performance of missing data. It surveys the popular imputation methods such as Mean and Mode Imputation (Mimpute), HotDeck Imputation (HDImpute) , KNN and Prediction model. |
TECHNIQUES FOR MISSING VALUE |
| The KNN algorithm is one of the popular approaches to handle missing data problem. KNN imputation (used to estimate missing value for imputation) employs the knearest neighbor algorithm to estimate and replace missing data. The main advantages of KNN are that it is capable of estimating both the qualitative and quantitative attributes. It is not possible to create a predictive model for each attribute with missing data. To perform KNN, it needs three different variable values: making a decision on how many neighbors are taken for estimation in each of the iteration, training data and metric to measure the closeness. The main factor of this method is distance metric. The main problem in KNN is that, it will check the whole dataset to find similar instance for imputation. Selecting the “k” value and the measure of similar instance will reflect the result greatly. The above problem is solved by introducing clustering (pruning algorithm) before it starts searching for the k-nearest neighbor value. The proposed method for missing value is presented in Figure 2 below. The data is given as input to the system. To remove the outlier, pruning algorithm (Clustering) is applied. Once the data is pruned, classify the dataset into complete and incomplete instances. The main purpose of introducing pruning algorithm is to reduce the time complexity, and thus automatically speed up the process of handling missing values and classification. |
| The procedure for pruning algorithm is given below: |
| 1) First step includes: Identify all clusters and divide into small and large clusters with the help of KMean clustering. The small clusters are removed from the dataset. |
| 2) The second step works only with large clusters and uses relevancy metric called Cluster Validity Index (CVI) to identify irrelevant data. The CVI is good performance measure if the diversity of the subsets is high. When large portion of features are irrelevant, then it is likely to get a couple of clusters with similar information separate by the unimportant features. The parameter mainly used to identify weak clusters that do not have any influence on the final result. |
| 3) Most important part of the proposed pruning algorithm is the selection of irrelevant cluster. This is achieved by applying K-means algorithm iteratively with different parameters to create subset of clusters. The CVI is then used to identify weak clusters with irrelevant data and merge similar clusters together. The Quality of cluster is evaluated by using Cluster Validity Index which is shown in following Equation 1. |
 |
| performance of the classification process. The process is repeated until the CVI of clusters remains unchanged. |
| In the above algorithm, the CVI measure is used to select only those clusters that have relevant features. The threshold of convergence is set to 0.01 and the number of clusters k is set to 10. The clusters obtained for each distance metric is considered as a separate subset. The algorithm can considerably reduce the time complexity and in the worst scenario, all clusters can be combined after m-1 iterations. Although the pruning step does not always have a large impact on the performance, it may reduce the computational complexity. |
| The overall process of proposed algorithm is shown in Figure 2. Pruning method is applied to reduce the time complexity of the proposed algorithm, hence to speed up the process of missing value handling and classification. Find the nearest neighbor value using the proposed KNN in short time period. Real time water dataset which is collected from TWAD Board contains many missing values. The proposed algorithm is implemented and results are discussed in the following section. |
| This section concludes that missing values will be handled effectively with the help of proposed technique. Handling missing value is very important in data mining applications. If the missing values are more than 15%, then handling details difficult. To obtain accurate results, efficient techniques are needed to handle the missing values. The proposed and enhanced KNN predict and replace the missing values in a very short time. |
EXPERIMENTAL RESULTS |
| Many Imputation/Non-Imputation methods are there to deal with missing data which are developed in recent years. The basic steps for handling missing values along with imputation method are discussed Section II. In this section, experimental results about missing data are discussed. The real time dataset is collected from various distribution points. More than 5 parameters are considered to detect contaminations present in the drinking water. Water must be treated properly before it is distributed to the public. |
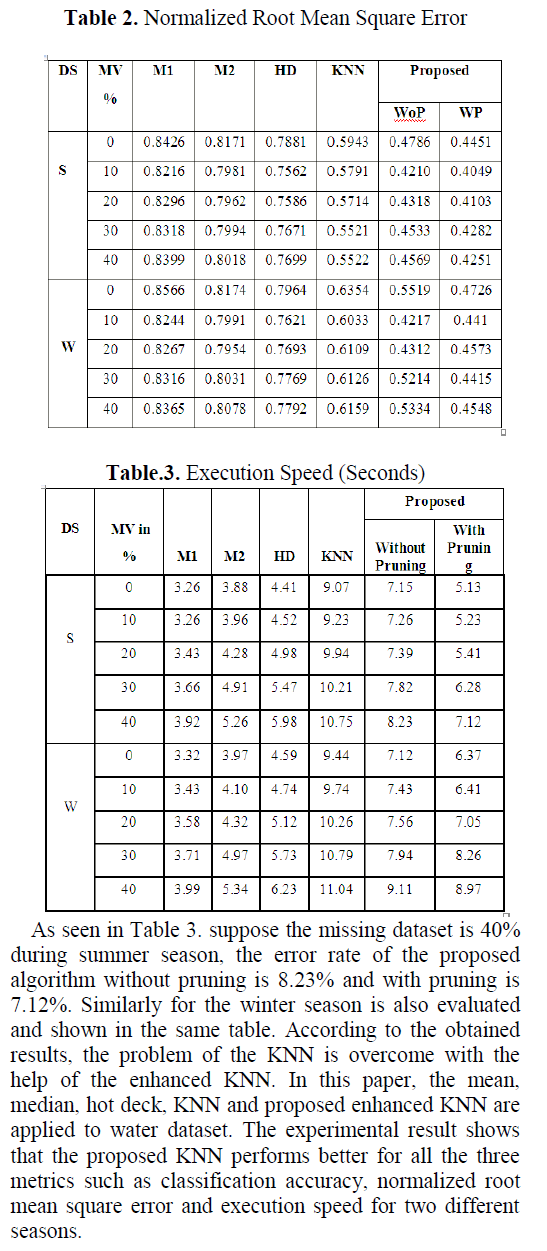
| In this paper, for removing the outlier, pruning algorithm is used. The pruned data will be given as input for further process of imputation. The dataset is classified as complete and incomplete instances. The complete instances are clustered, using K-Mean clustering. The incomplete instance are arrange, based upon the missing value percentage in ascending order, to find the nearest complete instance using distance metric. The enhanced KNN is used to impute the missing values in the dataset. The above implemented enhanced KNN is evaluated, using the three objective measures such as Accuracy, Normalized Root Mean Square Error (NRMSE) and Execution Speed. |
 |
 |
 |
CONCLUSION |
| In this paper, imputation method is used to replace the missing values. The enhanced KNN method is used to classify and impute the missing instances in the collected datasets. The proposed method selects the K-nearest neighbor, considering the input instances relevant to the target class instances. The imputation is done based on the Euclidean distance metric. During the missing value estimation, this enhanced KNN imputes missing values in a short span of time and improves the classification accuracy, NRMSE and execution speed. The result shows the best performance compared to other substitution methods. In future, the same algorithm can be used for different real time applications and implemented for database repositories. |
ACKNOWLEDGEMENT |
| The authors express their gratitude to TWAD Board for their whole hearted support in providing dataset for research. |
References |
|