International Journal of Innovative Research in Science, Engineering and Technology
ISSN ONLINE(2319-8753)PRINT(2347-6710)
ISSN ONLINE(2319-8753)PRINT(2347-6710)
S. Anjanadevi, D. Vijayakumar , Dr. K .G. Srinivasagan
|
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Innovative Research in Science, Engineering and Technology
Cloud computing is an emerging, computing paradigm in which tasks are assigned to software, combination of connections, and services accessed over a network. This connections and network of servers is collectively known as the cloud. Instead of operating their own data centers, users might rent computing power and storage capacity from a service provider, paying only for what they use. Cloud storage involves the delivery of data storage as service including database. If the data is stored in cloud, it must provide the data access and heterogeneity. With the advances in cloud computing it allows storing of large number of images and data throughout the world. This paper proposes the indexing and metadata management which helps to access the distributed data with reduced latency. The metadata management can be improved for a file system in large scale applications. When designing the metadata, the storage location of the metadata and attributes is important for the efficient retrieval of the data. Indexes are used to quickly locate data without having to search over every location in storage. Based on these two models, the data can be easily fetched and the search time was reduced to retrieve the appropriate data.
Keywords |
| Metadata, Cloud Storage, Index, Google File System, Hadoop Distributed File System |
INTRODUCTION |
| Cloud Computing is an emerging technology which categorize and schedule service based on the Internet. The concept of cloud computing includes the Web 2.0, web infrastructure, virtualization technologies and other emerging technologies. With the cloud computing technology, users use a variety of devices with laptops, smart phones, PCs, PDAs to access storage, and application-services offered by cloud computing providers. Some advantages of the cloud computing technology include cost savings, high availability, and scalability. |
| In Cloud, there are different types of cloud services. They are Infrastructure as a service, Software as a service (Saas), and Platform as a service (Paas). In Iaas, the clients control and manage the systems in terms of the applications, storage, and network connectivity, operating systems, but do not they control the cloud infrastructure. Example: Amazon EC2. In Saas, clients purchase the ability to access and use an application or service that is hosted in the cloud. Example: Salesforce.com. In Paas, clients purchase access to the platforms, enabling them to use their own software and applications in the cloud. Example: Google AppEngine. There are different types of deployment models in cloud. They are Private cloud, Public cloud, Hybrid cloud. In private cloud, the cloud infrastructure has been organized, maintained and operated for a specific organization. The operation may be internal or with a third party on the premises. In Public cloud, the cloud infrastructure is available to the public on a commercial basis by a cloud service provider. In Hybrid cloud, it can be a combination of private and public clouds that support the requirement to maintain some data in an organization. |
| The primary uses of cloud computing is for data storage. Cloud storage is one of the services which provide storage resource and service based on the remote servers. Cloud storage is a model of online storage where data is stored on various third party servers. It will be able to provide storage service at a lower cost and more reliability and security. The advantage of cloud storage is it enables users at any time access data. There are different cloud storage systems. Some have focus on storing Web email messages or digital pictures. Others are available to store all methods of numerical data. Some cloud storage systems are small processes, but others are so large that the physical equipment can fill up an entire warehouse. The services that provide cloud storage systems are called datacenters. |
| The HDFS is one of the storage systems. The Hadoop distributed file system (HDFS) is a distributed, scalable file system written in Java for the Hadoop framework. Each node in a Hadoop instance usually has a single namenode which is a cluster of datanodes form the HDFS cluster. HDFS stores large files in the range of gigabytes to terabytes across several machines. It succeeds reliability by replicating the data across multiple hosts, and requires RAID storage on cloud. The replication data is stored on three nodes. HDFS added the high-availability capabilities and allowing the main metadata server the NameNode to be failed over manually to a backup in the event of failure. This paper proposes the design of cloud storage system which focus on Metadata organizer, Level indexer and PC cluster based storage system in HDFS. The rest of this paper is organized as follows. Section 2 refers to the Related works. In section 3 presents Cloud Storage Architecture. In section 4 describes Evaluation and Analysis of the model. Finally, section 5 is the Conclusion and References. |
RELATED WORK |
| The paper proposed by sai Wu et al [11], describes an indexing framework for the Cloud system based on the structured Overlay. The indexing framework reduces the amount of data transferred inside the Cloud and facilitates the deployment of database back-end applications. The Cloud system dynamically allocates computational resources in response to customer’s resource reservation requests and in accordance with Customer’s predetermined quality of service. |
| A RAMCloud Storage System (RCSS) was proposed by YifengLuo et.al [7]. It is used to allow efficient random read accesses in cloud environments. Based on the HDFS, RCSS adds the available memory resources in an HDFS cluster to form a cloud storage system, which backs up all data on HDFS managed disks, and gets data from disks into memory. RCSS can achieve high I/O performance with low latency and high throughput for random read accesses.` |
| Cloud storage system is difficult to balance the providing huge elastic capacity of storage and investment of expensive cost for it. To solve this issue in cloud storage infrastructure, low charge PC cluster based storage server was proposed by Tin TinYee et.al [9]. PC cluster based storage server provides the hardware and software devices for large amount of data storage. The framework of Cloud based Cluster PC System (CCPS) consists of three layers. They are web based application services layer, Hadoop Distributed File System (HDFS) layer and PC cluster layer. The web based application layer offers interface to store their applications such Virtual Machine (VM) images, dataset and multimedia data, etc. |
| HDFS does not perform well for large numbers of small size files. Bo Dong et.al [12], examine the reasons of small file problem of HDFS: (1) large numbers of small files force burden on NameNode of HDFS; (2) correlations between small files are not considered for data placement and (3) There is no optimization mechanism is provided to improve I/O performance. According to file correlation features, files are classified into three types: logically related files, structurally-related files, and independent files. Based on these, an optimized approach is designed to improve the storage and access efficiencies of small files on HDFS. File merging and prefetching scheme is used for structurally related small files, whereas file grouping and prefetching scheme is used for managing logically-related small files. |
| A W Leung et.al [14] describes the Spyglass, a file metadata search system that achieves scalability by exploiting storage system properties. By designing using an index that exploit storage properties, Spyglass is able to achieve significantly better query performance than existing solutions, while using less disk space. Gurmeet Singh et.al [13] describes that the data intensive applications produce and analyze petabytes and terabytes of data that are distributed in millions of files or objects. To manage these large data sets, metadata needs to be managed. There are various types of metadata that are specialized for particular types of metadata cataloguing and discovery. In this paper, they present the design of a Metadata Catalog Service (MCS) that provides a mechanism for storing and accessing descriptive metadata and allows users to query for data items based on desired attributes. |
CLOUD STORAGE ARCHITECTURE |
| Cloud storage infrastructures are focused on providing users with easy interfaces and high performance services. The main objective of this paper is to propose efficient cloud storage for the fast access of data to minimize the search time of consumer This architecture describes the user interface configuration is used to connect to indexing and metadata to determine the storage, which is described in Fig. 1. The cloud is setup in Eucalyptus cloud platform. Eucalyptus is free and open-source computer software for building private cloud computing environments. Eucalyptus enables pooling compute, storage, and network resources that can be dynamically scaled up or down as application workloads change. Eucalyptus consists of five components. They are Cloud Controller (CLC), Walrus, Cluster Controller (CC), Storage Controller (SC), and Node Controller (NC). The Cloud Controller (CLC) handles the incoming requests and it acts as the administrative interface for cloud management. The CLC accepts user API requests and manages the compute, storage, and network resources. Walrus is providing a mechanism for storing and accessing virtual machine images and user data. Walrus can be accessed by end-users, whether the user is running a client from outside the cloud or from a virtual machine instance running inside the cloud. |
 |
| The Cluster Controller (CC) acts as the front end for a cluster within a Eucalyptus cloud and communicates with the Storage Controller (SC) and Node Controller (NC). The SC communicates with the Cluster Controller (CC) and Node Controller (NC) within the distributed cloud architecture and manages Eucalyptus block volumes and snapshots to the instances within its specific cluster. The Node Controller (NC) hosts the virtual machine instances and manages the virtual network endpoints. The NC downloads and caches images from Walrus as well as creates and caches instances. |
| Eucalyptus user console has the following systems: The dashboard is the starting point for using the Eucalyptus User Console. From the dashboard, users can access landing pages for instances, storage items (volumes and snapshots), and networking and security objects (key pairs, security groups, and IP addresses). An instance is a virtual machine which is essentially an operational private computer that contains an operating system, applications, network accessibility, and disk drives. A Manage Instances allows users to view a list of instances, create new instances, and connect to, reboot, terminate, and delete instances. Users can also associate/disassociate IPs from instances, attach/detach volumes, and use an instance as a model to create an auto scaling launch configuration, view logs, and stop/start EBS-backed instances. The Storage allows users at how many storage objects are running and access the various storage object management screens. Manage Volumes allows users to view a list of your volumes, create new volumes, attach and detach volumes to a running instance, and delete volumes. Manage Snapshots allows users create a volume from a snapshot and register a snapshot as a machine image that can then be launched as an instance. Manage Images allows users to view a list of images, create auto scaling launch configurations from an image, and launch instances from an image. |
| /change profile is to display the search result of the current user. In the search result page, user can view or change your identity’s profile. View access key is to displays the search result of the current user’s access key. Change password is The Eucalyptus Administrator Console has the following areas: View to displays a dialog to change password. Download new credentials is to downloads the current user’s credential package in a zip file. A Eucalyptus Machine Image (EMI) is a special type of pre-packaged operating system and application software that Eucalyptus uses to create a virtual machine instance. An EMI contains all necessary information to boot instances of your software. An EMI can contain whatever software you want to meet your needs. |
| The Hadoop distributed file system (HDFS) is a distributed, scalable file system written in Java for the Hadoop framework. Before installing the hadoop, create a designated hadoop user on the system and install the Preliminary Software. After that install, format and run the Hadoop. |
 |
 |
| A user interface is the interaction between users and cloud. A cloud storage system wants data server connected to the Internet. A client sends copies of files to the data servers, which will records the information. When the client needs to retrieve the information, they access the data server through a Web storage interface. The server then sends the files back to the client or allows the client to access and manipulate the files on the server itself. Databases are created to function large quantities of information by inputting, storing, retrieving, and managing that information. The high performance storage server provides expensive cost. To address this problem, the efficient cloud storage system is implemented with low cost and nodes that are organized into PC cluster based data center. |
| A PC cluster is a collection of computer nodes, all nodes can be used individually or collectively as a cluster. In PC cluster, the large files can be stored by striping the data across multiple nodes. PC cluster consists of one NameNode as server and many DataNodes as clients. PC System uses HDFS (Hadoop Distributed File System) to store data in the collection of the nodes. NameNode manages the whole PC cluster and maintains the metadata of HDFS that contains the current locations of blocks, monitoring the states of all nodes in the cluster and the information of blocks. NameNode is recorded any changes to the file system namespace such as opening, closing, renaming files and directories. It also defines the mapping of blocks to DataNodes. The DataNodes store the physical storage of the files. DataNodes also perform block creation, replication and deletion upon instruction from the NameNode. In PC cluster, files are divided into blocks that are stored as independent units. Each block is copied to a small number of single machines for fault tolerance. |
| An index is a data structure that improves the speed of data retrieval operations on a database and the use of more storage space to maintain the extra copy of data. Indexes are used to rapidly locate data without having to search every row and every time a database is accessed. Index could provide the data pointer that specified to the data value set which is stored in specified column and then order these pointers according to the specified sort order. The first column contains a copy of the primary or candidate key of a table and the second column contains a set of pointers holding the address of the disk block where that particular key value can be found. |
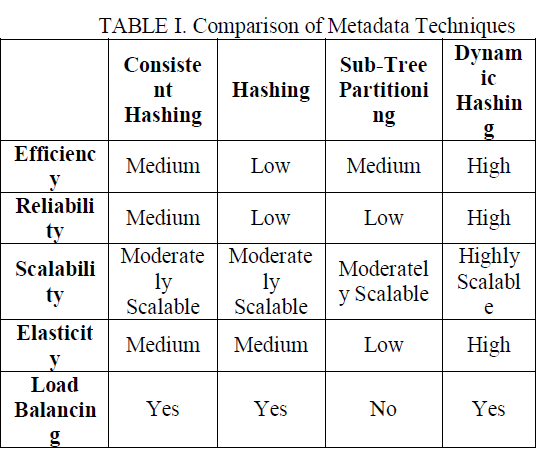
| The metadata file is the major operation in searching files in cloud storage systems. The metadata refers to high level information about who is using the content, how the content is being used, and when multiple pieces of content are being used. It also identifies the number of partitions and the number of levels of the stored file. Before a file is retrieved the related metadata is to found and permission to be accessed to be obtained. Metadata is managed separately by one or more specialized metadata servers. To distribute metadata among multiple servers some techniques are used like Sub-Tree Partitioning, Hashing technique, Consistent Hashing and Dynamic Hashing. |
| `In sub tree partitioning, namespace is divided into many directory sub trees, each of which is managed by individual metadata servers. The metadata may not be evenly distributed, and the computing and transferring of metadata may generate a high time and network overhead. In hashing, metadata can be distributed uniformly among cluster, but the directory locality feature is missing. It has slow directory operations such as listing the directory contents and renaming directories. In Consistent hashing, the output range of the hash function is treated as a ring. Not only the data is hashed, but also each node is hashed to a value in the ring. In Dynamic hashing, the metadata can be distributed uniformly among cluster, it works dynamically and the directory locality feature will not lose. Thus the efficiency is high than the other three technique. |
PERFORMANCE EVALUATION |
| In Table I, the comparison of metadata techniques is defined with various attributes such as efficiency, reliability, scalability, elasticity and load balancing. In Fig. 4, the efficiency, reliability, scalability, elasticity and load balancing refers to 1,2,3,4 and 5 in the graph respectively. In Dynamic Hashing technique the efficiency is high as compare to other three techniques. Thus it dynamically works in the distribution of metadata and routing of metadata request is effectively done using dynamic hashing which leads to improvement in system reliability and elasticity. In this the data bucket is divided into equal size which is evenly distributed over the NameNodes which leads to efficient load balancing because of even distribution. |
 |
| In consistent technique the data bucket is not correctly divided into equal size which leads to less load balancing. Thus the elasticity and scalability is moderate which leads to less efficiency. In Hashing technique the efficiency is low since hashing destroys the locality of metadata which causes the opportunity to prefetching and storing the metadata in bucket. In hashing the hash function uses the search-key of the bucket. This search key is unique. Due to the uniqueness of search key in hashing dependency is generated which leads to low reliability and low elasticity. In Sub-Tree partitioning the performance is medium compare to hashing technique. Thus reliability and elasticity decreases. The cloud storage has two parameters. First, the load intensity is specified that in this case is the rate at which files arrive. Second, we specify the service demand is also specified that is the average service requirement of a file. The average response time of the system with different arrival rate are shown in Fig. 5. |
 |
 |
| In our system configuration 3 DataNodes are used and consumed about 50 GB Hard disks storage of each PC for installation of an operating system and other software installation. The available storage capacity of these PCs is shared together, and then it can provide 3 x 50 = 150 GB of storage capacity. The storage capacity remains unused and can be utilized if shared to store huge amount of data. If the system configuration used the number of 20 DataNodes, then the available storage capacity can provide 20x50=1000 GB. Therefore, storage capacity of the server can be increased depending on the number of node in PC cluster. The average storage capacity of PC cluster based storage server is shown in Fig. 6. In this paper, we have adopted dynamic hashing technique to distribute the metadata evenly among the metadata server. As compare to other techniques dynamic hashing evenly distributes load to the server and consumes less memory and provides high efficiency in HDFS. |
CONCLUSION |
| There has been a significant advancement in the area of cloud computing. However knowledge about the storage in cloud is not yet discovered. This project is helpful in acquiring the storage with index and metadata and the PC cluster process in HDFS, which will help to minimize the search time of consumer and fast access of the data. This will guarantee the minimization of the search time of consumer. |
References |
|