International Journal of Innovative Research in Science, Engineering and Technology
ISSN ONLINE(2319-8753)PRINT(2347-6710)
ISSN ONLINE(2319-8753)PRINT(2347-6710)
P.Jeyadurga, Prof. P. R. Vijaya Lakshmi, J.S.Kanchana
|
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Innovative Research in Science, Engineering and Technology
Feature clustering is a feature reduction method that reduces the dimensionality of feature vectors for text classification. In this paper an incremental feature clustering approach is proposed that uses Semantic similarity to cluster the features. Pointwise Mutual Information (PMI) is widely used word similarity measure, which finds Semantic similarity between two words and is an alternative for distributional similarity. PMI computation requires simple statistics about two words for similarity measure, that is number of cooccurrences or correlations between two concepts of fixed size are computed. Once the words from preprocessed documents are fed, clusters are formed and one feature (head word) is identified for each cluster which are used for indexing the document. PMI assumes that a word have single sense, but clustering can be optimized further if polysemies of words are considered. Hence PMI may be combined with PMImax, which estimates correlation between the closest senses of two words also, thereby better feature reduction and execution time compared with other approaches.
Keywords |
| Feature reduction, feature clustering, Semantic similarity, Pointwise Mutual Information (PMI). |
INTRODUCTION |
| Text classification is the problem of estimating true class label for a new document. High dimensionality of feature vectors of the document can be an obstacle for classification algorithms. Therefore feature reduction approach is applied before text classification algorithm is applied to document. Feature extraction and Feature selection are earlier approaches that were developed for feature reduction of which feature extraction worked better. But all these feature reduction algorithms had higher computational complexity. Feature clustering is an effective approach for reducing the dimensionality of the document. The basic idea is to group the features into clusters that are highly related and a single feature is extracted from each cluster thereby reducing number of features. Initially Backer and McCallum [3] proposed a feature reduction technique based on clustering, that uses distributional similarity to cluster. Later clustering based on this similarity combined with learning logic for text classifier was proposed by Al-Mubaid and Umair [2].Bekkerman et al [4] and Dhillon et al [5] proposed various methods for feature clustering, but all those had various disadvantages. A new fuzzy similarity based self-constructing algorithm was proposed by Jung-Yi Jiang el al [8] for clustering. This method is an incremental feature clustering approach, where each word in the document set are represented as distributions and the similar words are grouped into clusters. Also each cluster is represented by a Membership function with statistical mean and deviation. The feature extracted from each is weighted combination of all the features in the cluster. This method was faster than other approaches and the extracted features were also better. We propose a Pointwise Mutual Information (PMI) [10] scheme for determining word similarity. Thus the words with high PMI similarity are grouped into a cluster. The reminder of this paper is detailed as follows: In Section 2, we explain the existing schemes for feature reduction and fuzzy similarity measure for clustering in detail and its working principle. In Section 3, presents the proposed PMI based feature clustering algorithm. |
| Experimental results are given in Section 4 and finally, conclusion is given in section 5.PMI is a semantic similarity measure where similarity between two concepts or words is found using their context overlap. |
II. RELATED WORK |
| A. Fuzzy clustering algorithms for mixed feature variables Symbolic variables may present human knowledge, nominal, categorical and synthetic data etc. Since1980s, cluster analysis for symbolic data had been widely studied. Miin-Shenetal[11] created a FCM objective function for symbolic data and then proposed the FCM clustering for symbolic data. They connected fuzzy clustering to deal with symbolic data. Fuzzy clustering algorithms for mixed features of symbolic and fuzzy data were proposed Numerical examples and comparisons are also given. Numerical examples illustrate that the modified dissimilarity gave better results. B. Dimension Reduction in Text Classification with Support Vector Machines Support vector machines (SVMs) have been recognized as one of the most successful classification methods for many applications including text classification by Hyunsoo Kim et al [6]. Even though the learning ability and computational complexity of training in support vector machines may be independent of the dimension of the feature space, reducing computational complexity is an essential issue to efficiently handle a large number of terms in practical applications of text classification. A novel dimension reduction method to reduce the dimension of the document vectors dramatically was adopted. And also decision functions for the centroidbased classification algorithm and support vector classifiers to handle the classification problem where a document may belong to multiple classes were introduced. Substantial experimental results shows that with several dimension reduction methods that are designed particularly for clustered data, higher efficiency for both training and testing can be achieved without sacrificing prediction accuracy of text classification even when the dimension of the input space is significantly reduced. C. Fuzzy Feature Clustering(FFC)Algorithm Fuzzy similarity-based self constructing algorithm was an incremental feature clustering approach to reduce the number of features for the text classification task proposed by Jung-Yi Jiang el al [8]. Here Cluster characterization was done by Gaussian distribution. A document set D of n documents d1, d2, . . . ,dn, with the feature vector W of m words w1, w2, . . . , wm and p classes c1, c2, . . . , cp are given as input to the classifier. First step is to construct word pattern for each word in W. For word wi, its word pattern xi is defined by, |
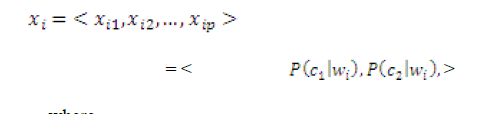 |
 |
| algorithm. Assume that k clusters are obtained for the words in the feature vector W. ïÃâ÷ Step 2: Find the weighting matrix T and convert D to D'. ïÃâ÷ Step 3: Using D' as training data, a classifier based on support vector machines (SVM) is built. A SVM can only separate apart two classes (+1 or -1). Therefore for p classes, p SVMs are created. Thus classifier is the aggregation of these SVMs. ïÃâ÷ Step 4: (Classifying unknown documents) suppose, d is an unknown document, first convert d to d'. Then feed d' to the classifier and get p values, one from each SVM, d belongs to those classes with 1 appearing at the outputs of their corresponding SVMs. The proposed system replaces the existing Fuzzy similarity for Semantic similarity using PMI for Feature clustering, which worked better than existing algorithm. |
III. PMI SIMILARITY |
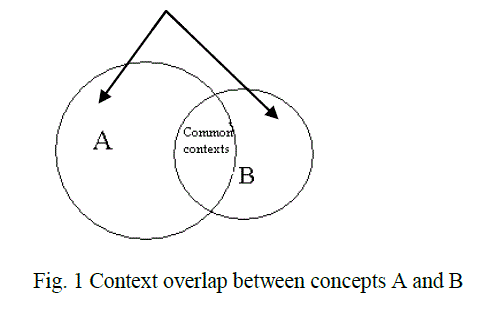
| In the existing methods the similarity between two words for clustering are calculated based on their distributions among the documents. For two given words, distributional similarity obtains collective contextual information for each word and computes how similar their context vectors are. That is for two concepts1 to be similar it does not require the concepts to co-occur in the same contexts2. Distributional similarity has the ability to find âÃâ¬Ãâ¢indirectâÃâ¬Ãâ similarity but it cannot classify them accordingly. In contrast semantic or PMI [10] similarity determines how much commonality they share for two concepts to be similar. Typically a concepts meaning can be determined by its context in which it occur. Therefore considering this fact, two concepts are said to be semantically similar if their contexts overlap as explained in Fig. 1. |
 |
| If the overlap between contexts of two concepts is larger, then co-occurrences of two concepts are also large. Therefore it is clear that the extent of commonality of context between two concepts is determined by the number of co-occurrences. PMI is a normalized measure of co-occurrences to represent the similarity. |
| Where fc1 and fc2are individual frequencies of two concepts c1 and c2in the corpus and C2) is the cooccurrence frequency of two concepts c1 and c2 in the context window of size d. Nis the total number of words in the corpus3.The optimal value of d was between 16 - 32 obtained by Terra et al [16]. A. Incremental Feature Clustering approach In our proposed approach, initially there is no cluster and a new cluster is created if needed. For each pair of word PMI similarity is calculated using (1) and compared with a threshold value (ρ). If the calculated PMI value is high then both the words are placed in the same cluster otherwise a new cluster is created for the dissimilar words. Threshold (ρ) is a predefined value based on the preferences of the user. If the value of ρ is high, then the number of clusters formed is also large, thus resulting more extracted features. Hence for smaller value of ρ, minimum features are extracted. Also care should be taken, that the value of ρ should not be too high or too low, which may result in false similarity measures. B. Feature Extraction and Classification For each cluster, a head word is selected based on occurrences (fc) of the word in the corpus. Head word is the extracted feature for each cluster and has higher fc value among all the other features in the cluster. This head word is compared with the new incoming word for PMI similarity. Given a set of Documents D and their corresponding classes as training dataset for designing a classifier, the steps are, ïÃâ÷ Preprocess the documents to obtain set of features. ïÃâ÷ Fix the threshold (ρ) and apply the proposed PMI based feature clustering approach for clustering. ïÃâ÷ Extract on feature per cluster to obtain D' ïÃâ÷ Using D' as the training data construct classifier that identifies the class label for the new document. Classifier is designed based on comparison between the distributions of features of the training document set among the clusters with the distribution features from the new document, for which the class label to be identified. If more number features from the new document is grouped in a cluster G, then the class label for the new document will be the class of the document for which there is more features grouped into this cluster G. 1. A concept is referred as a particular sense of word. 2. A context is a part of text or statement that surrounds a word and determines its meaning. 3. A corpus is a large collection of writings of a specific kind or on a specific subject. |
IV. EXPERIMENTAL RESULTS |
| The dataset selected is 20 Newsgroups [1] which contains a collection of 20,000 articles and are distributed over 20 classes. After preprocessing there were 25,7198 features in the dataset. Fig. 2 shows the execution time for the feature reduction method that uses our PMI approach and FFC algorithm. The x-axis in the graph represents the number of features extracted for various threshold ρ. The y-axis represents the execution time for the feature reduction procedure. Our proposed PMI based Feature Clustering approach is abbreviated as PMIFC in the figure. |
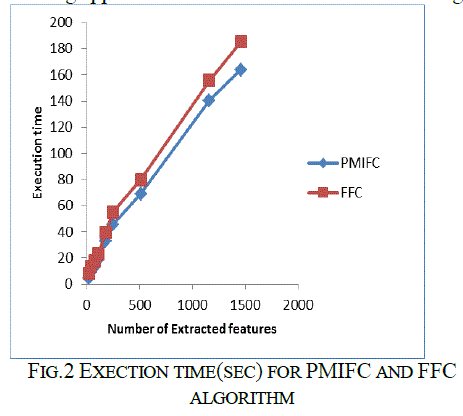 |
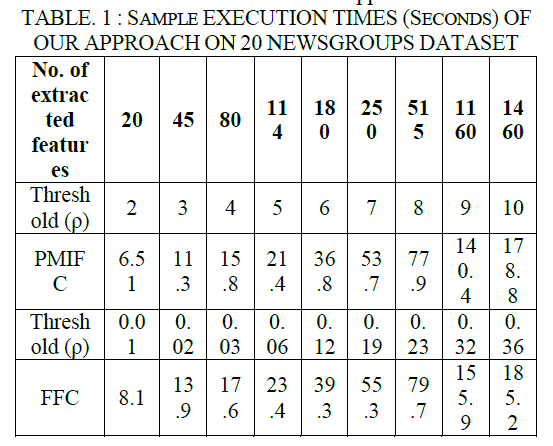
| Table. 1 gives the values of points in the Fig. 2 for different values of ρ. It is clear from the graph that as the threshold value increases, the number of extracted features and execution time also increases. It if found that execution time is reduced for PMIFC approach. |
 |
V.CONCLUSION |
| The PMI based clustering approach is proposed which finds similarity between the features based on their semantic similarity. PMI similarity works on the basic idea that if two words are similar then their contexts overlap and the context determines the words meaning. Hence the amount of co-occurances of the concepts in the context is determined for the similarity calculation. Based on this similarity the features are cluster. For each cluster a head word is selected based on its number of occurrences on the corpus. This extracted feature issued for indexing the document. Classifier is designed for this training dataset and used to find class label for new document. The execution time for proposed system is comparatively minimum for PMIFC and also better feature reduction was achieved. |
VI. FUTURE ENHANCEMENT |
| PMI similarity assumes that a word has single sense, but reality better feature reduction can achieved if polysemy of words are considered. PMImax is an enhancement on PMI that considers polysemy of word to find similarity. PMImax estimates correlation between the closest senses of two words also. Thus PMImax can combine PMI in the future for better results. |
References |
|