International Journal of Innovative Research in Science, Engineering and Technology
ISSN ONLINE(2319-8753)PRINT(2347-6710)
ISSN ONLINE(2319-8753)PRINT(2347-6710)
Dr. K.Sakthivel1, R.Abinaya2, I.Nivetha2, R.Arun Kumar2
|
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Innovative Research in Science, Engineering and Technology
Region Based Image Retrieval (RBIR) is an image retrieval approach which focuses on contents from regions of images. This approach applies image segmentation to divide an image into discrete regions, which if the segmentation is ideal, it corresponds to objects. Thus the capture of region is improved so as to enhance the indexing and retrieval performance and also to provide a better similarity distance computation. During image segmentation, a modified k-means algorithm for image retrieval is developed where hierarchical clustering algorithm is used to generate the initial number of clusters and the cluster centres. In addition, during similarity distance computation, object weight based on object’s uniqueness is introduced. Therefore considering images based on regions using RBIR allows the users to pay more attention to regional properties that may better characterize objects which are also made up of local regions. This strategy is able to better reflect the characteristics of the images from the perspective of image regions and objects.
Keywords |
| Region Based Image Retrieval (RBIR), Similarity distance computation, k-means algorithm, Hierarchical clustering algorithm, object weight. |
INTRODUCTION |
| Digital image processing is the technology for applying number of computer algorithms to process a digital image. The outcomes can be an image or either a set of representative characteristics or properties of original image. Digital image processing directly deals with an image, which is composed with many image points. These image points are also called as pixels, are of spatial coordinate that indicate the position of the point in the image, and intensity values. An Image Retrieval system is a computer system for browsing, searching and retrieving images from a large database of digital images. Most of the common techniques of image retrieval utilizes some method of adding metadata such as captioning, keywords, descriptions to images and also regions of images. |
| With the overwhelming growth of image databases, efficient image coding, manipulation, indexing and retrieval are required for effectively managing large image databases and make images easily accessible. Contentbased image retrieval (CBIR), querying images from large archives using image own content, has then become an important and hot issue in recent decades. CBIR methods exploit low-level image features such as color, texture and shape as keys to retrieve images. Region-based image retrieval methods(RBIR), which segment images into regions and retrieve images based on the similarity between regions, have been investigated extensively for an attempt to bridge the gap between low image features and high image semantic concepts. Semantic analysis and representation of image content is crucial for region-based image retrieval. Although the existing retrieval methods have improved the performance of RBIR, many of them still have one or more following limitations. Many RBIR methods cannot provide desirable low resolution for image segmentation. Since the amount of raw image pixels is often very large, for simplifying data and deleting redundant details, a number of image retrieval systems either divide an image into unit pixel blocks whose averaged values are regarded as the pixel features or quantize the color space of an image into limited number of bits. Both methods are mathematically similar to image sampling and rescaling, which cannot provide naturally low-resolution image for further image segmentation if an image contains high frequency information such as sharp color variations. |
| Concerning region representation, a number of image retrieval approaches derive global region characterization. For example, the color or texture histogram or the center of the feature vector set in one region is often taken as the region feature vector. It is also observed that color and texture features in region feature vector are commonly considered as separated ones, which is difficult and complex to tune the importance between two unrelated features in the distance functions for region matching. In this paper we propose a hierarchical approach for regionbased image retrieval. For RBIR, it first segments images into number of regions and extract the set of features, which are known as “local features” from segmented region. |
| A similarity measure determining the similarity between target region in the query and the set of segmented region from the other image is utilized later to relevant images to the query based on the local region features. Our goal is to tackle above problems and improve image understanding and representation for RBIR. Image retrieval systems, which compare the query image exhaustively with each individual image in the database, are not scalable to large databases. A scalable search system should ensure that the search time does not increase linearly with the number of images in the database. The clustering based indexing technique is presented, where the images in the database are grouped into clusters of images, with similar colour content using a hierarchical clustering algorithm. . At search time, the query image is not compared with all the images in the database, but only with a small subset. Experiments show that this clustering-based approach offers a superior response time with high retrieval accuracy. |
II. REGION BASED IMAGE RETRIEVAL |
| RBIR is an image retrieval approach which focuses on contents from region of images, not the content from entire image in early CBIR. For RBIR, it first segments images into number of regions and extract the set of features, which are known as local features from segmented region. A similarity measure determining the similarity between target region in the query and the set of segmented region from the other image is utilized later to relevant images to the query based on the local region features. The motivation of RBIR approaches are based on Figure II: Block diagram for Region Based Image Retrieval |
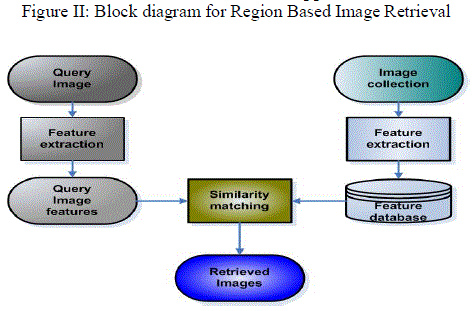 |
| the fact that high level semantic understanding of images can be better reflected by local features of images, rather than global features. In the Figure II the general block diagram for retrieving the image from the collection of images in a database is illustrated. Thus regions are considered while retrieving image using RBIR. |
III. EXISTING SYSTEM |
| a. Region-Based Image Segmentation with k means algorithm |
| k-means Clustering (KMC) algorithm of automation determination the clustering number K and an approach of region-based image segmentation is introduced. For this approach, firstly, a suitable color space is selected, the features of color, texture, and location are extracted, and the feature space is generated. Then, in this feature space, an image is clustering and separated into some regions by proposed method. Finally, the features of regions are extracted. |
| b. Image Segmentation by Clustering: |
| To humans, an image is not just a random collection of pixels, it is a meaningful arrangement of regions and objects. Most computer vision and image analysis problems require a segmentation stage in order to detect objects or divide the image into regions which can be considered homogeneous according to a given criterion, such as color, motion, texture, etc. Image segmentation is the first step in image analysis and pattern recognition. It is a critical and essential component of image analysis system, and it is one of the most difficult tasks in image processing, and determines the quality of the final result of analysis. Image segmentation is the process of dividing an image into different regions such that each region is homogeneous.Clustering is the search for distinct groups in the feature space. It is expected that these groups have different structures and that can be clearly differentiated. The clustering task separates the data into number of partitions, which are volumes in the n-dimensional feature space. These partitions define a hard limit between the different groups and depend on the functions used to model the data distribution. Clustering is a classification technique. Given a vector of N measurements describing each pixel or group of pixels (i.e., region) in an image, a similarity of the measurement vectors and therefore their clustering in the N-dimensional measurement space implies similarity of the corresponding pixels or pixel groups. Therefore, clustering in measurement space may be an indicator of similarity of image regions, and may be used for segmentation purposes |
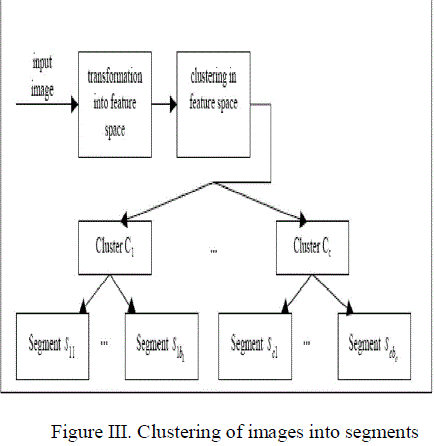 |
| The Figure III illustrates the segmentation of the input image into clusters. The clusters are grouped into segments. The segmented objects are used for image retrieval. |
| c. Color Features extraction |
| Color features are relatively easy to extract and match, and have been found to be effective for indexing and searching of color images in image databases. One of the main aspects of color feature extraction is the choice of a color space. A color space is a multidimensional space in which the different dimensions represent the different components of color. Most color spaces are three dimensional. An example of a color space is RGB, which assigns to each pixel a three element vector giving the color intensities of the three primary colors, red, green and blue. |
| d. Texture features extraction |
| Texture has local neighbourhood property. The selection of scale directly impacts the precision of texture representation. In this paper, texture features include contrast, polarity, anisotropy. According to the component L in L*a*b color space and the analysis of polarity feature using different scale parameters of Gauss function, we can get the optimal scale parameters, then, calculate contrast and anisotropy. |
| Image Region Segmentation Approach Based on KMC |
| Algorithm |
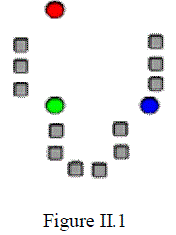
| An approach which can be self-deciding clustering number K and initial clustering centers for K-means clustering algorithm. Since K and initial clustering centers. The following are the steps involved, 1. k initial "means" (in this case k=3) are randomly generated within the data domain (shown in color).This is shown in Figure II.1 |
 |
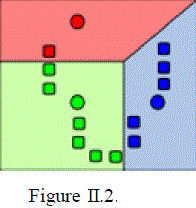
| 2. k clusters are created by associating every observation with the nearest mean. Similar pixels are then grouped together to form clusters. This is shown in Figure II.2. In the diagram it is obvious that pixels of red, green and blue color are grouped into same cluster. Thus in the second step similar pixels are formed into a group. |
 |
| 3. The centroid of each of the k clusters becomes the new mean. This is shown in Figure II.3 |
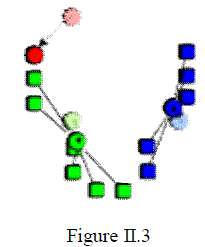 |
| 4. Steps 2 and 3 are repeated until convergence has been reached. This is shown in Figure II.4 |
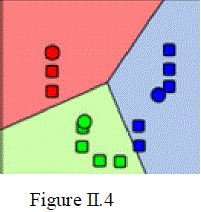 |
| Thus the k-means clustering algorithm is used for clustering similar pixels. Next, region segmentation is performed. Image region segmentation consists of the following two steps. (i)Initial regions are labeled (ii) region label in step(i) is based on the feature space of pixels, and the pixel points with the same label (the same clustering) may not be neighbor in 2-D space. So, these regions are re-labeled in this step. In addition, morphologic methods (dilation and erosion) are used to process the edge of regions. |
| f. Result of the existing Approach Based on KMC Algorithm |
| An approach which can be deciding clustering number k and initial clustering centers for k-means clustering algorithm. Since k and initial clustering centers are given, the clustering speed is fast. The virtue of KMCA-ADCN algorithm is the fast clustering speed, especially fit for image region segmentation. Comparison experiments between the proposed approach and the general k-means cluster algorithm (denoted by KMC), EM-MDL (Expectation Maximum-Minimum Description Length).KMCA-ADCN approach determines cluster number k and initial cluster centers firstly, then uses kmeans cluster algorithm. The general k-means cluster algorithm chooses a group of k(2~8) at first, then does clustering, finally, selects the k according to the error square sum. After segmentation, features of each region are described and saved to form feature database for RBIR(Region-based image retrieval) system. The following features are extracted. (1)Color features of region (2)Texture features of region (3)Location features of region Thus with the help of these features image is extracted. |
IV. PROPOSED SYSTEM |
| In this project, RBIR system is used for retrieving the image. RBIR system is based on combination of more than one low level feature of the digital image are color, texture, and shape. This is because the robustness of digital image retrieval and only using one low-level retrieval feature cannot achieve a good result. In this project, images in the database are of the standard size. Here, Block Color histograms are used to extract the color histogram of the image in the database and query image and in that algorithm, image is separated into n x n blocks. If it is 4 X 4 color histogram then it will be more effective. A cooccurrence matrix is adopted to extract texture features as it requires less computation and has a faster feature extraction speed. Moreover, the feature vector dimensions are also smaller. The texture features are extracted in 5 steps in our system namely Image color conversion, Grey-scale quantification, Feature value calculation, internal normalization, Texture feature comparison by Euclidean distance. The three main tasks of our region based image retrieval system are: |
| 1) Image segmentation to obtain objects/regions. Images are segmented by grouping pixels with similar descriptions to form objects/regions. |
| Object clustering for faster retrieval |
| 3) Similarity distance computation between the image query and database. |
| Feature selection during image segmentation is a crucial step. Every pixel, on the image is clustered using a modified k-means algorithm to group similar pixel together to form objects. To increase the retrieval speed during query, similar objects are clustered using a hierarchical clustering algorithm. The similarity distance algorithm is introduced to minimize the error obtained during image segmentation. Finally, the accuracy during retrieval is obtained by performing the modified k-means algorithm and Hierarchical clustering algorithm. The block diagram shown in Figure IV explains how an input image is segmented into color and texture features. The extracted features are considered separately and as a whole k-Means algorithm is applied. The technique uses regions to capture semantic content of images. Under the paradigm, various local features are extracted from each image in the database and image retrieval is formulated as searching for the best database match to the feature vector extracted from the query image. |
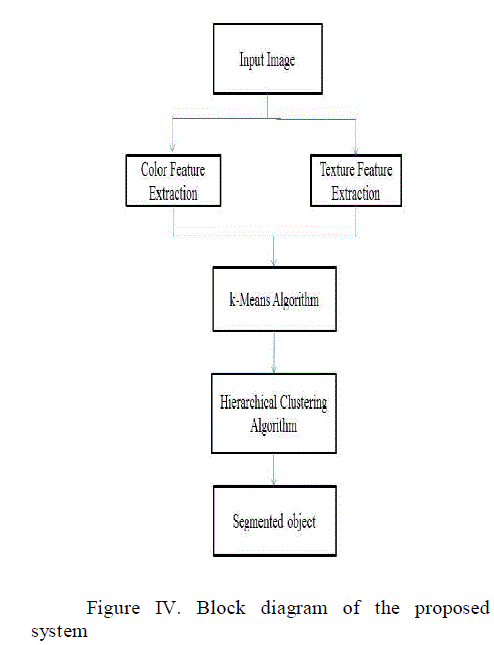 |
| a. Feature Extraction |
| The image is partitioned into 4 by 4 blocks, a size that provides a compromise between texture ranularity, segmentation coarseness, and computation time. A good texture granularity while reducing the number of total pixels per image, therefore decreasing the computation time. To segment an image into objects, six features are extracted from each block. Three features are color features, and the other three are texture features. The HSV color space is selected during color feature extraction due to its ability for easy transformation from RGB to HSV and vice versa. Since HSV color space is natural and approximately perceptually uniform, the quantization of HSV can be done. To obtain the other three features, we apply the Haar Wavelet transform to the L component of the image. The Haar wavelet is discontinuous and resembles a step function. It represents the energy in high frequency bands of the Haar wavelet transform. After a one-level wavelet transform, a 4 by 4 block is decomposed into four frequency bands, each band containing a 2 by 2 matrix. The shape features are not considered during similarity distance computation. IRM distance computation only for textured images, while non textured images considered the shape features. A textured image defined as an image of a surface, a pattern of similarity shaped object, or an essential element of an object. |
| b. Pixel Segmentation |
| After obtaining the features from all pixels on the image and store the information in an array and a modified k-means clustering is performed to group similar pixel together and form objects. The goal of kmeans algorithm is to partition the observations into k groups with cluster center that minimize the square error. The advantage of k-means algorithm it that it works well when clusters are not well similar from each other, which is frequently encountered in images. However, k-means requires the user to specify the initial cluster centers. The system performs hierarchical algorithm to the pixel image to obtain the initial cluster centers. The method is known to produce better clustering result compare to randomly generated initial clusters. Hierarchical clustering first merges pair of the closest pixels to form cluster. These clusters are then merged to generate a new bigger cluster and finally form a single cluster that covers the whole image. In the image database, compared to Euclidean distance, the Pearson correlation coefficient has been shown to produce better clustering result during image segmentation. |
| c. Object Clustering and Similarity Distance Computation |
| In order to increase the retrieval speed during query, similar objects are clustered to form classes. Many existing retrieval system try to compare the query image to all images in the database. The results in a high computational cost, especially when the database is large. To solve the problem hierarchical clustering to all the objects is performed. Each object described by six features which are the average features of all the member pixels. The information is in database. The query image goes through the same image segmentation algorithm with image database to obtain objects. These objects are compared to the cluster centers in the database above, and the overall similarity is calculated. The object in the database that has minimum distance will be returned to perform global image distance computation between query image and database image. To compute the overall distance computation between the query image and the returned image, match all the objects from the two images. From the two matched objects, the object distance is defined. The uniqueness of the object is based on the appearance of the object in the object cluster. When an object appear a more often in the database, it considers to be less unique and vice versa. To get the value of first hierarchical clustering is performed to cluster similar object in the same group. The uniqueness of object is obtained through the percentage of the number of objects that belong to the cluster compared to the total number of objects in the data. The definition of the overall similarity between two images captured by the overall distance between the images is a balanced scheme in similarity measure between regional and global matching |
| D. Similarity Distance Measure |
| To set a proper number of objects per image during hierarchical clustering, a similarity measure is compared against a threshold value. The value compares the length of a link in a cluster hierarchy with the average length of neighbouring links. Using the similarity measure value, pixels that are considered to be similar form a separate cluster. The number of cluster based on these measures is recorded and the average number of cluster for each similarity measure is computed. |
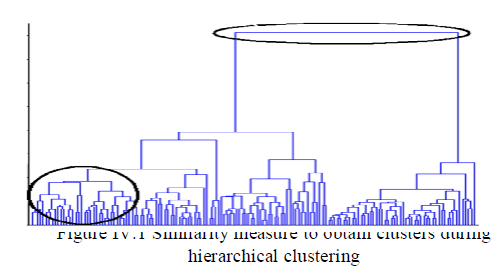 |
| d. Object Uniqueness |
| After obtaining all object features for all images, object clustering is performed using. Hierarchical clustering algorithm to obtain object groups. The cluster of object groups is necessary for two reasons: for faster image retrieval, and for determining the value of object uniqueness. The value of object uniqueness depends on the quantity of objects in a cluster because the larger the quantity in a cluster corresponds to a smaller value of object uniqueness. The way, object uniqueness is related to the result of object clustering. |
V. CONCLUSION |
| Data storage, searching and indexing large image databases efficiently and effectively has become a challenging problem. In order to solve the problem, there exist two distinct approaches in the literature. One solution is to annotate each image manually with keywords or captions and then search images using a conventional text search engine. |
| The system uses a modified k-means clustering algorithm to improve the image segmentation, and uses a new similarity distance measure where object uniqueness is considered during computation. The proposed system performs better when the contrast between the main object and the background is visible in the image and performs worse when the image is complex and the objects have smooth edges. During the implementation, by considering object uniqueness during similarity distance computation improve the accuracy during retrieval. The following are the advantages of the proposed method, 1) An improvement in image segmentation accuracy, especially for simple images 2) An improvement during similarity distance computation by using the parameter of object uniqueness into consideration. |
References |
|