International Journal of Innovative Research in Science, Engineering and Technology
ISSN ONLINE(2319-8753)PRINT(2347-6710)
ISSN ONLINE(2319-8753)PRINT(2347-6710)
Kusma Kumari Cheepurupalli1, Raja Rajeswari Konduri2
|
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Innovative Research in Science, Engineering and Technology
Reverberation suppression is a crucial problem in speech communications. The intelligibility of the speech signal will be degraded by strong reverberation. This paper presents a novel signal processing scheme that offers an improved solution in reducing the effect of interference caused due to reverberation. It is based on the combination of empirical mode decomposition (EMD) and adaptive boosting (AdaBoost) techniques. AdaBoost based EMD filtering technique is used for reverberation corrupted speech signal to decrease the noisy components present in the received signal. An improvement in the probability of detection is achieved using the proposed algorithm. The simulation results are obtained for various reverberation times at various SNR levels.
Keywords |
| Empirical Mode Decomposition, AdaBoost, feature extraction, signal de-noising, reverberation suppression |
INTRODUCTION |
| In room acoustics, the speech signals that are captured with a long distant microphone exhibit severe reverberation due to reflection from the walls and any objects in the room. Along with the reverberation, the received signal is distorted by the noise generated due to fan rotations or air conditioners present in the room. The perceived quality and intelligibility of the received speech signal is degraded by both the background noise and reverberation. Some of the applications like Automatic Speech Recognitions (ASR) Hearing aids, hands-free teleconferencing, scene analysis etc were seriously affected by these difficulties. [1] Hence there is a need for joint suppression of the reverberation and background noise effects. |
| There has been significant research on single microphone additive noise suppression algorithms. If the noise is negligible, the speech enhancement task is just speech de-reverberation. Bees et.al, [2] employed a cepstrum based method to estimate the Room Impulse Response (RIR), and used a least squares technique for inversion. In the similar manner various methods have been published in the literature to reduce the affect of noise. Among them, Empirical Mode Decomposition [3] is considered as one of the best method for noise reduction application. |
| The motivation behind the use of EMD as a filtering technique is that it is completely adaptive and data driven method that operates on non-linear and non-stationary data which are generally encountered in the real environment. The main advantage of EMD is it does not depend on the filter orders as like linear and adaptive filters [4, 5] and also does not require any basic or prior function as in the case like Wavelets [6, 7]. EMD also exhibits stable performance along with moderate speed and less complexity. |
| In our previous work [8, 9] the noise reduction problem due to interference signals was addressed using EMD as a filtering technique in which the selection of Intrinsic Mode functions (IMFs) which are used for signal reconstruction, was done manually. In this paper we propose the use of Adaptive Boosting technique [10] to adaptively select the IMF’s produced by EMD. |
| Sections II and III describes the brief introduction on EMD and AdaBoost techniques and section IV presents the description of new structure of the AdaBoost based EMD filtering technique by considering a speech signal s(t) as the original input signal which is corrupted by both reverberation and noise (additive white Gaussian noise) as n(t). The superior performance of the new algorithm is demonstrated using a set of simulation results. |
EMPIRICAL MODE DECOMPOSITION |
| Empirical Mode Decomposition (EMD) is relatively unconventional method in Signal Processing proposed by Nordon Huang of NASA [5]. The decomposition method used in the EMD is called as âÃâ¬Ãâ¢SiftingâÃâ¬Ãâ process. The introduction of these instantaneous frequencies for complicated data sets, are used to eliminate the spurious harmonics that may present in nonlinear and non-stationary signals. |
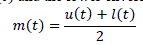 |
ADAPTIVE BOOSTING (ADABOOST) |
| The AdaBoost algorithm was introduced in 1995 by Freund and Schapire [10]. A good overview is given in [11]. AdaBoost is widely used for improving the performance of any kind of learning algorithm, see [12] for details. AdaBoost is an efficient method which is used to increase the accuracy and robustness of the given learning algorithm. By giving a set of examples with initial weights, AdaBoost trains an initial weak learner with the given training dataset. It then focuses those training examples which are misclassified. Then, the second weak learner is trained with an updated training dataset which increases the weights of these misclassified examples. Finally, an ensemble is combined linearly by these trained weak learners with corresponding weights. The algorithm is described as follows: |
| The input data required for the AdaBoost algorithm are: |
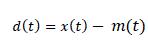 |
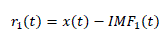 |
ADABOOST BASED EMD – PROPOSED METHOD |
| In this paper, a novel classification scheme for the IMFs using AdaBoost algorithm as shown in Fig. 1 is proposed. The AdaBoost technique works out the operation in two stages i.e., in terms of training and testing process. |
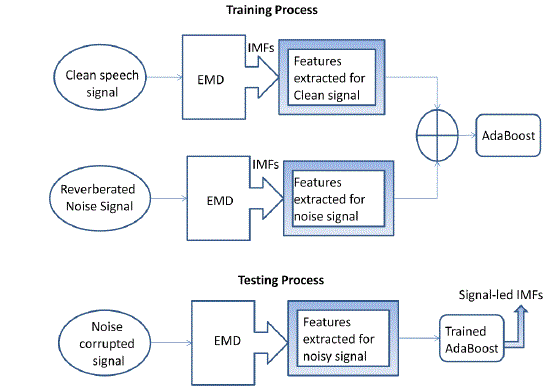 |
| From Fig.1 we can observe that the algorithm is first trained by using the feature extracts of the IMFs produced by EMD for the clean signal and noise individually. Once the algorithm is trained, then it is used in the testing process. The noise corrupted signal is applied to EMD and IMFs are obtained by decomposing the noisy signal. Then features are calculated for all the noisy IMFs and applied to the AdaBoost algorithm. Now the AdaBoost algorithm will distinguish the noise-led IMFs and signal-led IMFs and produces the ensemble of signal-led IMFs based on the feature extracts. |
| In this paper for the feature extraction some of the features like mean, variance, skewness and kurtosis [13, 14] both in frequency and time domain are calculated for all the noisy IMFs. Binary classification scheme is used to achieve accuracy in differentiating the signal and noise IMFs in the AdaBoost algorithm. In this paper we considered T as 50 and L as 500. To achieve more accuracy the value of T may be increased but at the cost of computational complexity. |
SIMULATION RESULTS |
| The numerical examples considered in this paper for reverberation suppression in noisy speech are a clean signal which is a wave file with Reverberation times (RT60) as 1, 2 and 3 seconds. The noise signal considered as Additive white Gaussian at various SNR levels ranging from -10dB to 10dB. The tables and plots describes the performance and robustness in probability detection of AdaBoost based EMD.As a comparison the same process is repeated with basic EMD as dereverberation technique. The threshold value Vt selected as 0.15. |
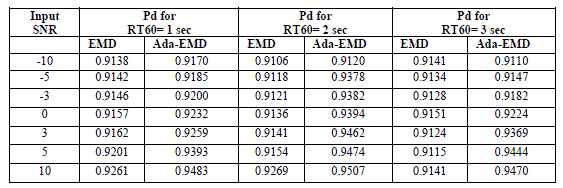 |
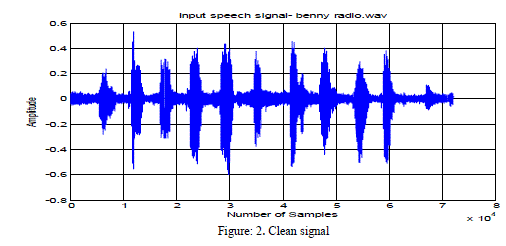
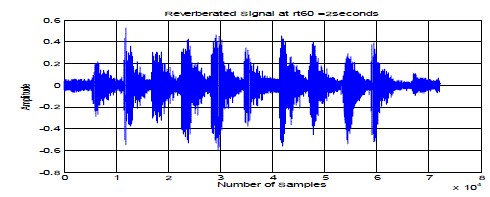
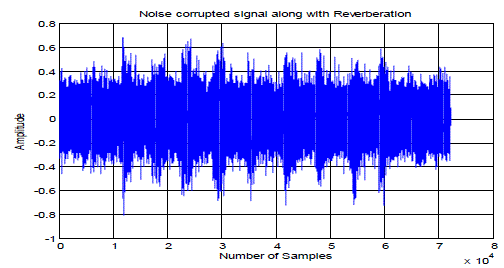
| The table showed above describes the performance of AdaBoost based EMD in terms of probability detection. The plots presented here are considered for the input SNR as -3dB and the reverberation time (RT60) as 2 seconds. Fig. 2 corresponds to the input signal which is a pure speech signal. Fig. 3 describes the plot details of reverberated speech signal. Fig. 4 is the noise corrupted speech signal along with reverberation. |
 |
 |
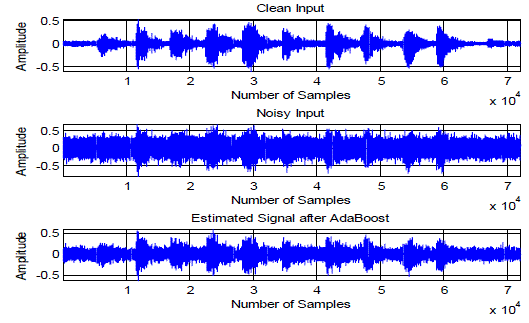
| Fig. 5 provides the details of simulation plots obtained using EMD only, i.e., de-noising is done with basic EMD. In this plot the estimated signal is obtained by manual selection of IMFs. Fig.6 describes the simulation plots in which the estimated signal is obtained by combining the IMFs that are adaptively selected by AdaBoost i.e., based on the feature extraction, the signal-led IMFs are classified by AdaBoost. In the training process the total IMFs produced for the clean speech signal are 16, the IMFs produced for reverberated noise signal are 17 and in the testing process the IMFs produced by EMD are 16. The Selected IMFs by AdaBoost technique are IMFs 3, 4, 5, 8, 9, 11, 12, 13, 14, 15 and 16 which are used for reconstruction of the speech signal. |
 |
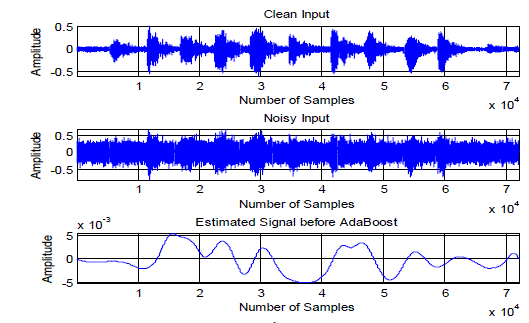 |
| From the plots it is evident that the reconstructed speech signal is looking almost similar as the input signal which proves the ability of AdaBoost based EMD as one of the best method that can be used for the joint suppression of the reverberation and the background noise effects. |
CONCLUSION |
| Thus Empirical Mode Decomposition is one of the best methods to reduce the noise present in a received signal. AdaBoost guarantees an exponential decrease of error with the increase of number of hypothesis. Both theoretical and empirical results demonstrate that AdaBoost has an excellent generalization performance as robust learner. |
| AdaBoost based EMD technique in combination with various parameter estimation methods can be used to improve the performance of the Direction of Arrival (DOA) calculation for sound signals in SONAR application which is the future scope of this paper. |
 |
ACKNOWLEDGMENT |
| This work is being supported under the project âÃâ¬Ãâ¢Robust Signal Processing Techniques for RADAR/SONAR CommunicationsâÃâ¬Ãâ by Ministry of Science & Technology, Department of Science & Technology (DST), New Delhi, India, under Women Scientist Scheme (WOS –A). |
References |
|