International Journal of Innovative Research in Science, Engineering and Technology
ISSN ONLINE(2319-8753)PRINT(2347-6710)
ISSN ONLINE(2319-8753)PRINT(2347-6710)
Ms.Amrata Soni1, Ms.Hemlata Sunhare2, Mr.Sachin Patel2
|
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Innovative Research in Science, Engineering and Technology
The Semantic Web is a latest technique for organizing information and it characterize a huge interest area for the worldwide research group of people, however it is still far from a significant implementation. In this research we have proposed a scheme for information retrieval stand on ontologies, dynamic semantic network, and lexical chains, significant an approach for achieve and indexing consequences by means of a narrative metric to compute semantic relatedness between words. Our technique has numerous novelties, in meticulous concerning the utilize of a collective knowledge base from which we mine precise domain ontologies; furthermore, the anticipated semantic relatedness metric achieve optimally evaluate with further metrics in the using a general test set. In meticulous we are taking into consideration the opportunity of introduce several form of normalization for the semantic constituent with respect to the length of lexical chains and the size of the documents, applying our research news paper domain and we are improving the analysis accuracy of our system compared with other metrics.
Keywords |
| Knowledge Base, Semantic Web, Information Retrieval (IR), Ontology. |
INTRODUCTION |
| Incredible quantities of information are unreservedly reachable to all and sundry throughout digital networks specifically the World Wide Web. The entrance and verdict benefit between these massive quantities of information is not potential unless they are correctly classify and prepared. Different Information Extraction (IE) techniques have been developed to mine essential information from text documents [1]. By developing the Web, the essential of web page analysis has emerged. The Information extraction system that progression web pages are called Wrappers [2]. Through the appearance of the Semantic Web [3], various researchers have become concerned in the semantic method as facilitators for information extraction responsibilities. The use of ontologies [4] to mine information is increasing rapidly and can be seen as the expectations of IE. Verdict similarity between semantics of mine information is referred to the task of matchmaking; it is the task of discovery semantic similarity between metadata present by the document sources and users. Semantic matchmaking technique mostly focuses on the semantic distance between dissimilar objects in organize to discover appropriate matches among those objects. various challenge have been achieve to determine the similarity among documents based on Vector Space Model (VSM) [5] such as cosine similarity, and Dice coefficient [6]. Ontology based relationship dimension as a presently advance has been developed in two behavior primary, a measure of accessible ontologies are employed to support the task of correspondence quantity such as the WordNet. A different ontology support relationship estimate approach is based on learning from the exercise text quantity. Onto Learn is an illustration of ontology learning techniques that recognize terminologies from the data set, and by with some statistical methods filter them in organize to construct domain conception forest [10]. The present work aims to utilize the compensation of ontology based similarity determine technique. We use a predefined ontology that can be updated by training data set and the annotation process. In addition we apply the capability of WordNet to support the task computing relationship between documents. We recommend a framework that takes semi–structure documents from dissimilar resources and semantically annotate them. Then, a matchmaker classification investigates relationship between a user’s requirements and meta-data afford by the annotation. In order to accomplish this objective, we utilize the capability of GATE [11] as a text dispensation implement to annotate data. Then we utilize the perception of similarity among keywords (ontology instances) and by with the WordNet, as language taxonomy, we recommend definite metrics to determine similarity between documents. These metrics can discover the connection between the user’s requirements and accessible resource data. |
II. RELATED WORKS |
| Mylonas in at al [1] the methodology presented herein can be exploited towards the development of a more efficient, context-based image analysis environment. Its core contribution has been the implementation of a novel, multi-domain visual context interpretation utilizing a fuzzy, OWL-based, ontological representation of knowledge, as well as a visual context algorithm. Leyla Zhuhadar in at al [2] they were introduced the evaluation of a Cross- Language Ontology-based Search Engine model. They evaluated the methodology used to map the theory with the actual implementation of the Cross-Language search engine using a list of keywords randomly extracted from our hand-made bilingual thesaurus. They evaluated the system based on concepts and sub concepts driven from both languages (English and Spanish). They used Top-n-Recall and Top-n-Precision to evaluate the efficiency of the Cross-Language search engine on multiple levels. Dimitris K. Iakovidis In at al [3] proposed Ratsnake, a software tool for efficient, semantically-aware annotation of images and image sequences featuring novel annotation approaches. Its efficiency has been validated on a case study involving the annotation of sequences of chest radiographs. Yuxia Huang in at al [4] proposed a method to classify geographic features based on latent semantic analysis and domain knowledge. The empirical research indicates that the proposed method achieves satisfactory categorizing effectiveness. |
| Mylonas in at al [1] the methodology presented herein can be exploited towards the development of a more efficient, context-based image analysis environment. Its core contribution has been the implementation of a novel, multi-domain visual context interpretation utilizing a fuzzy, OWL-based, ontological representation of knowledge, as well as a visual context algorithm. Leyla Zhuhadar in at al [2] they were introduced the evaluation of a Cross- Language Ontology-based Search Engine model. They evaluated the methodology used to map the theory with the actual implementation of the Cross-Language search engine using a list of keywords randomly extracted from our hand-made bilingual thesaurus. They evaluated the system based on concepts and sub concepts driven from both languages (English and Spanish). They used Top-n-Recall and Top-n-Precision to evaluate the efficiency of the Cross-Language search engine on multiple levels. Dimitris K. Iakovidis In at al [3] proposed Ratsnake, a software tool for efficient, semantically-aware annotation of images and image sequences featuring novel annotation approaches. Its efficiency has been validated on a case study involving the annotation of sequences of chest radiographs. Yuxia Huang in at al [4] proposed a method to classify geographic features based on latent semantic analysis and domain knowledge. The empirical research indicates that the proposed method achieves satisfactory categorizing effectiveness. |
III. PROPOSED METHODOLOGY |
| In our visualization we can have Web search improvement with a hybrid technique that takes into description in cooperation syntactic and semantic information in a method that has as a possibility of knowledge, an ontology. We recommend using a query construction formed by a catalog of provisions to retrieve and a domain of interest to improve symbolize the dissimilar mechanism of the IR process (user interests, objects to retrieve). In our method the perspective of knowledge is WordNet [Miller 1995], a universal knowledge base prepared from a linguistic point of view. A concise narrative of this knowledge source is specified in the subsequent segment. Still if WordNet has numerous shortfalls in a quantity of intangible domains, it is one of the nearly all used linguistic resources in the examiner community. The most important objective of our effort is to intend a method proficient of retrieving and indexing results, attractive into explanation the semantics of the pages. This method should be capable to achieve the following tasks. Fetching: Searching Web documents enclose the keywords precise in the query. This undertaking can be proficient using traditional search engines. Preprocessing: confiscate commencing Web documents everyone those fundamentals that do not symbolize constructive information (HTML tags, scripts, applets, etc.). Mining: An examination of the documents’ satisfied from a semantic point of observation, assigning a achieve with admiration to the query. |
| Exposure: Indexing and recurring the document appropriate to the query. Currently we illustrate an illustration to initiate our framework and its associations with the proposed system Figure 1. By resources of the system interface, the customer suggests a query subsequent the structure formerly illustrate. The topic keywords are used in the fetching step where quantities of pages are fetched from traditional search engines (Bing, ask, Yahoo, Google) and then preprocessed by the module described in figure 1. On the further give a domain keyword is approved to the miner and an ad hoc component construct a semantic network dynamically take out from WordNet subsequent the algorithm accessible in figure 1. In the document analysis step lexical chains are acquire by intersecting the extract semantic association with each preprocessed page. A global rank is allocated to every page using a metric. From a elevated level point of view, the projected process is straightforward and follow a modular approach besides it is absolutely automatic and the relations with the scheme only occur throughout the query formulation. |
IV. STRUCTURAL DESIGN |
| The proposed system is based on numerous services. In this circumstance every software component performs events illustrate in the previous section in view of the semantic denotation of the Web documents. Figure 1 nearby an inclusive architectural observation of the proposed system. |
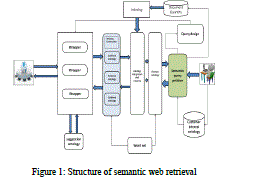 |
| the pages associated to the links and stores them in the Web Repository. The pages are retrieved by the Web Catcher while the Repository designer inserts them in the Web Repository. The structure of a Web page often has an appearance page that is collected of animations, images, and so on. Presently we presume that these objects do not give useful information to our system. The Web Fetcher retrieves, as default, the primary two levels in the site structure and stores them using the equivalent hierarchy, preliminary from the main link. In an equivalent way, it stores the pages with frames. Document Preprocessor: subsequent to the Search Engine Wrapper and Web Fetcher execute their proceedings we have in the Web Repository a set of Web pages associated to the user query. From a universal position of view, a Web page is collected of numerous parts. It is clear that the semantic content of a Web page relies on the body tag metatags have a exacting significance because they provide a synthetic explanation of the page. The HTML languages describe some tags to systematize a Web page. Consumers insert information in these tags and systematize contents in a structured way. In our system we endeavor to catch the dissimilar levels of in sequence considering title, Meta tag description; Meta tag keywords body. The Document Preprocessor analyzes the page and separates it into that mechanism, storing them in the Preprocessed Web pages storage area. In this step discontinue words are deleted and the outstanding words are tagged and stemmed. The stemming is attaining by resources of the WordNet morphological processor. Miner: The Miner analyze, from a semantic position of observation, the pages cleaned and accumulate in the Preprocessed Web page repository its core is the Dynamic Semantic set of connections (DSC). The DSC is produced by DSC planner, which produce it from WordNet by resources of the domain keyword present by the user in the query capitulation step, subsequent an hybrid algorithm explain in the next subdivision. This network symbolize the domain of significance of a user and with it, the Miner processes the information essential to examine the semantic satisfied of a page and events the relations between documents and the user’s in sequence needs represented by the DSC. In organize to compute these correspondences we realize a metric that takes into explanation both syntactic and semantic mechanism in the document study step. The anticipated metric is used by the universal Grader component and its productivity is a catalog of index pages exposed to the user. The particulars of the mining process are elucidate in the subsequently subdivision. |
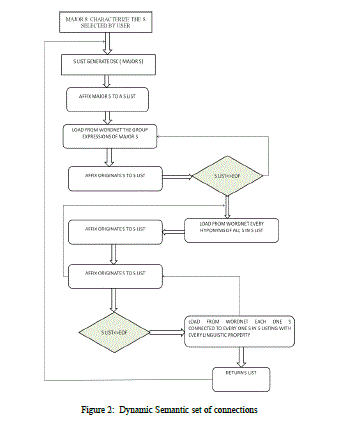
V. PROPOSED INFORMATION EXTRACTION ALGORITHM |
| In this segment we explain our anticipated algorithm to extract information from internet documents and we analyze in feature all the mechanism of our execute modules. The Dynamic Semantic set of connections In the proposed system, the achievement of the ontology is obtain by means of a DSC, dynamically construct using a dictionary based on WordNet [Miller 1995]. WordNet systematize its expressions using linguistic proprieties. Furthermore each domain keyword possibly will have numerous significance (senses) appropriate to the respectability of polysemy, so a user can prefer its appropriate sense of attention. In WordNet these senses are controlled in synsets collected of synonyms consequently, formerly the intellect is chosen, it is potential to obtain into description every one the achievable terms (synonymous) that are present in the synonyms. Outside the synonymy, we think other linguistic proprieties functional to the typology of the measured terms in organize to have a sturdily associated system. A semantic system is frequently used as a form of knowledge illustration: it is a graph consisting of Nodes which symbolize conception and edges which characterize semantic relationships between conceptions. We propose a dynamic building of the semantic association via the interaction with WordNet. As previously particular, a user interacts with the classification by means of a semantic query, specifying the topic keywords and the domain keyword. The DSC is constructing preliminary from the domain keyword that characterize the circumstance of concentration for the user. We then think all the section synonyms and build a hierarchy based simply on the hyponymy property; the last levels of our hierarchy communicate to the most recent level of WordNet. Following this first step we enrich our hierarchy by consider all the supplementary kinds of associations in WordNet. Based on these relations we can add other terms in the hierarchy, obtain a extremely associated semantic system. The algorithm to extract the DSC is described. We at present begin an example to better explain the proposed algorithm. We believe that a user is concerned in retrieving documents about the religion domain submits the word religion as the domain keyword. The system passes the domain keyword to the DSC Builder and fetches from WordNet the synset Religion. Following the algorithm the DSC Builder links to the synset Religion all the other synsets linked by the category terms property, which belong to related topical classes. Preliminary from these synsets we adjoin only hyponyms to the initial semantic system. The process of adding hyponyms stops at the last level of the hyponymy hierarchy in WordNet. After this step we add all the other synsets directly. |
VI. EXPERIMENTAL RESULT |
| We have experienced our system with a document base in use from an online newspaper archive [2]. For this application, the document class hierarchy includes News (subclass of Text Document), Photograph and Custom Graphic (subclasses of Media Document). With which all documents and domain classes are classified, as explained in Section. Our current implementation is compatible with both RDF and OWL. Building appropriate domain ontologies and a complete KB for a newspaper archive is an enormous undertaking, or would need very advanced semi-automatic knowledge extraction techniques that are not available yet in current state of the art. However, as stated in previous sections, our system tolerates incomplete ontologies and KBs. We have built news domain ontologies for testing purposes, matching to news domain, with classes such as Artist, Painter, testimonial, Company, Bank, Sportsman, Sports Team, Stadium, etc., and a small number of instances of each class. These ontologies were building by reading 200 news articles, and defining classes and instances by hand for concepts found in the documents. In total, 150 domain classes and 1,555 instances were created. We have also manually set labels and keywords for concept classes and instances. Then we have run the automatic annotation and weighting algorithm over a subset of the archive comprising 2,500 news articles, which generated 3,500 annotations, of which 355 were manually created. Once the KB was built, we tested the retrieval algorithm with some examples, and. We report next the observed results in four examples, showing different levels of performance of our method in different cases. The metrics are based on a manual ranking of all documents for each query, on a scale from 0 to 5. In the experiments, all the query variables were given a weight of 1. The measurements are subjective and limited, yet indicative of the degree of improvement that can be expected, and in what cases, with respect to a keyword-based engine. The retrieval times are too low to draw any significant observation regarding efficiency. |
| Query a. “News about players from India playing in cricket teams of shreelanka” |
| In this example the semantic retrieval algorithm outperforms keyword-based search because the KB contains many instances of cricket players and teams, some of which match the query. Keyword-based search only recognizes a document as relevant if it contains words like “player”, “india”, “shreelanka”, whereas the semantic search retrieves news about players and teams as soon as the name of the player or the team are mentioned in the documents. These are typical results when a search query involves a region of the ontology with some degree of completeness in terms of instances and annotations. These cases yield a high precision up to almost maximum recall. |
| Query b. “News about Indian cricket team presidents” In this example, the ontology KB has only a few instances of cricket team presidents, so not all documents relevant to the query are annotated. This causes precision to drop to lower values when recall increases. Although the total recall of semantic search is low, it still has a good precision for the top-ranked documents, which are the few ones annotated with instances in the KB. A few more documents where semantic search alone fails are still given a high ranking thanks to the combination with keyword-search, which shows here a comparable behavior to example a. |
| Query c. “News about cricket players” In this case the performance of the two algorithms is similar. For this example, we have intentionally removed most instances of players from the KB, leaving a relatively low number. Moreover, we have removed all lexical variants in the label and keyword Properties of player instances, except the player’s surname. As a consequence, many annotations are missing. Under these conditions, the semantic model alone performs much worse than keyword-based search. However, the combined search yields a similar final behavior to keyword-based search. |
 |
| But the semantic ranking places these wrong documents in a top position, whereas the keyword- based model does not rank them particularly higher than the correct documents. It can be seen that it is the automatic annotator, and not the retrieval system, which is failing here in the absence of the appropriate instances needed to solve ambiguities. One way to reduce the negative impact of incorrect annotations would be to introduce a factor in the automatic weighting algorithm that accounts for the proximity of the respective classifications of the documents and the instancesTesting this and other possible improvements to the automatic annotation strategies are one of our planned tasks for the immediate future. Figure 2 Evaluation of ontology- based search (combined with keyword-based) against keyword based only. The performance of both algorithms are shown for four different queries a, b, c, The graphics on top show the precision vs. recall figures (as defined in e.g. [16]), and the graphics below show the average relevance at different document cutoff values, for each query. |
VII. CONCLUSION |
| Semantic retrieval approaches can integrate and take advantage of SW and IR views and technologies to provide better search capabilities, achieving a qualitative improvement over keyword-based retrieval by means of the introduction and exploitation of fine-grained domain ontologies. The application of semantic retrieval models to the Web, and more specifically the integration of ontologies as key-enablers to improve search in this environment, remains an open problem. Challenges and limitations such as the size and heterogeneity of the Web, the scarceness of the semantic knowledge, the usability constraints, or the lack of formal evaluation benchmarks, can be pointed out as some of the main reasons for the slow application of the semantic retrieval paradigm at a Web scale. |
ACKNOWLEDGMENT |
| We would like to express our gratitude to all those who gave us the possibility to complete this paper. We want to thank the Information Technology of the Patel College of Science and Technology for giving me permission to commence this paper in the first instance, to do the necessary research work and to use departmental data. We are deeply indebted to our Master of Engineering supervisor Mr. Sachin Patel from the IT Department PCST whose help, stimulating suggestions and encouragement. We are also thankful to Ms. Hemlata Sunhare for her guidance. |
References |
|