International Journal of Innovative Research in Science, Engineering and Technology
ISSN ONLINE(2319-8753)PRINT(2347-6710)
ISSN ONLINE(2319-8753)PRINT(2347-6710)
| Mr.S.Krishnaraj, Mr. M. V. Prabhakaran M.E. Computer science Dept, Adhiparasakthi college of Engineering, Melmaruvathur, Chennai, India |
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Innovative Research in Science, Engineering and Technology
Face recognition has received a great deal of attention from the scientific and industrial communities over the past several decades owing to its wide range of applications in information security and access control, law enforce, surveillance and more generally image understanding. A general partial face recognition method based on Multi-Key point Descriptors (MKD) that does not require face alignment by eye coordinates or any other fiducial points. The invariant shape adaptation makes image matching more robust to viewpoint changes which are desired in face recognition with pose variations. A Multi-Key point Descriptors (MKD), where the descriptor size of a face is determined by the actual content of the image. The MKD-SRC (Sparse Representation-based Classification) framework that works for both holistic faces and partial faces can be sparsely represented by a large dictionary of gallery descriptors. Multitask sparse representation is learned for an each probe face and the Sparse Representation-based Classification (SRC) approach is applied for face recognition a fast atom filtering strategy for MKD-SRC to address large-scale face recognition (with 10,000 gallery images). A new key point descriptor called Gabor Ternary Pattern (GTP) / Directional Local Extreme Pattern (DLEP) is developed for robust an discriminative face recognition.
Keywords |
| Partial face recognition, alignment free, Keypoint descriptor, sparse representation. |
INTRODUCTION |
| The problem of locating examples of known object in images. Image interpretation used rigid models is well established. However, in many practical situations objects of the same class are not identical and rigid models are inappropriate. In medical applications, for instance the shape of organs can vary considerably through time and between individuals. In addition, many industrial applications involve assemblies with moving parts or components whose appearance can vary. In such cases flexible models or deformable templates can be used to allow for some degree of variability in the shape of the imaged objects. One motivation is to achieve robust segmentation by using the model to constrain solutions to be valid examples of the class of images modeled. |
| A suitable model also provides a basis for a broad range of applications by coding the appearance of a given image in terms of a compact set of parameters that are useful for higher-level interpretation of the scene. A PFR (Partial Face Recognition) system will enable them to identify a suspect in a crowd by matching a partial face captured by a mobile phone to a watch list through a wireless link real time. Second, given a photo of a certain unlawful event PFR is needed to recognize the identity of a suspect based on a partial face. |
| There are common criteria relevant to edge detector performance. The first and most obvious is low error rate. It is important that edges that can occur in the image should not be missed and that there be no spurious responses. In all the above cases, system performance will be hampered by edge detector errors. The second criterion is that the edge points be well localized. That is distance between the points marked by the detector and the "center" of the true edge should be minimized. This is particularly true of stereo and shape from motion, where small disparities are measured between left and right images or between images produced at slightly different times. |
Proposed Method |
| A Multi-Keypoint Descriptor (MKD) representation for both the gallery dictionary and the probe images. Multitask sparse representation is learn for each probe face and the Sparse Representation-based Classification (SRC) approach is applied for face recognition. A general partial face recognition approach without requiring face alignment, the MKD-SRC framework that works for both holistic faces and partial faces, and outperforms SRC in addressing the onesample- per-class problem. A new Keypoint descriptor, called the Gabor Ternary Pattern (GTP), which outperforms the Scale Invariant Feature Transform (SIFT) descriptor, and a fast atom filtering strategy for MKD-SRC to address large-scale face recognition (with 10,000 gallery images). |
| We have addressed the problem of recognizing a face from its partial image and proposed an alignment free approach called MKD-SRC. The approach represents each face image with a set of Keypoint descriptors (GTP and SIFT), and constructs a large dictionary from the gallery descriptors. In the descriptors of a partial probe image can be sparsely represented by the dictionary and the identity of the probe can be inferred accordingly. A comparison with two commercial face matchers, Face VACS and PittPatt shows that MKD-SRC particularly with the proposed GTP descriptor is well suited for general partial face recognition problem. In case partial face cannot be detected our approach can still provide a matching score will give a manually cropped face region. Given a general framework of MKD SRC it would be useful to apply MKD SRC to other image classification areas such as object categorization. |
CANNY EDGE DETECTOR |
| The Canny edge detector is an edge detection operator that uses a multi-stage algorithm to detect a wide range of edges in image Canny's aim was to discover the optimal edge detection algorithm. In this situation, an "optimal" edge detector means: |
| ïÃâ÷ Good detection – the algorithm should mark as many real edges in the image as possible. |
| ïÃâ÷ Good localization – edges marked should be as close as possible to the edge in the real image. |
| ïÃâ÷ Minimal response – a given edge in the image should only be marked once, and where possible, image noise should not create false edges. |
 |
2.1 SRC (Sparse Representation-based Classification) |
| The sparse representation-based classification (SRC) is a robust face recognition method. Sparse representation has recently been applied to a variety of applications in computer vision and image processing. However, its computational complexity is very high due to solving a complex l1-minimization problem. To improve the calculation efficiency a novel face recognition method called sparse representation-based classification. |
| Based on image reconstruction SRC assigns a test input to the class with the smallest reconstruction error using the corresponding sparse representation. The SRC has been shown to produce impressive performance on face recognition and attracts more attention of the researchers since both feature extraction (i.e., sparse representation) and classification can be achieved simultaneously without the need to train additional classifiers. Besides face recognition, SRC has also been applied to handwritten digit recognition. In order to derive sparse representation for signals like images one needs to utilize an over complete dictionary for reconstruction purposes and deploys a sparsity constraint on the resulting weight coefficients. |
2.2 SCALE INVARIANT FEATURE TRANSFORM |
| The SIFT descriptor is invariant to translations rotations and scaling transformations in the image domain and robust to moderate perspective transformations and illumination variations. |
| Scale-Space Extreme Detection: The first stage of computation searches over all scales and image locations. It can be implemented efficiently by using a difference of Gaussian function to identify potential interest points that are invariant to scale and orientation. |
| Keypoint Localization: At each candidate location a detailed model is fit to determine location and scale. The Keypoint are selected based on measures of their stability. |
| Orientation Assignment: One or more orientations are assigned to each Keypoint location based on local image gradient directions. All future operation are performed on image data that can be transformed relative to the assigned orientation scale and location for an each feature there by providing invariance to these transformations. |
| Keypoint Descriptor: The local image gradients are measured at the selected scale in the region around each Keypoint. The transformed into a representation that allows for significant levels of local shape distortion and change in illumination. |
| A SIFT descriptor is a 3-D spatial histogram of the image gradients in characterizing the appearance of Keypoint. The gradient at each pixel is regarded as a sample of a three-dimensional elementary feature vector formed by the pixel location and the gradient orientation. Samples are weighed by an gradient norm and accumulated in a 3-D histogram h, which (up to normalization and clamping) forms the SIFT descriptor of the region. The additional Gaussian, weighting function is applied to give less importance to gradients farther away from the Keypoint center. Orientations quantized into eight bins and the spatial coordinates into four each as follows: |
 |
| They accept as input a Keypoint frame which specifies the descriptor center size and its orientation on the image plane. The parameters influence the descriptor calculation described below: |
| ïÃâ÷ Magnification factor. The descriptor size is determined by multiplying the Keypoint scale by this factor. |
| ïÃâ÷ Gaussian window size. The descriptor support is determined by a Gaussian window which discounts gradient contributions farther away from the descriptor centre. The standard deviation of this window is set by sift set window size and expressed in unit of bins. |
2.3. Gabor Ternary Pattern Descriptor |
| Gabor filtered have been successfully used for face recognition both due to their robustness to variations in the face appearance (caused by ageing, changes in the illuminations, etc.,) and close relationship with the receptive fields of simple cells in the mammalian visual cortex. They have been used as a complementary feature set to local pattern features as well as the pre-processing stage of local pattern features where local pattern features are applied on the Gabor filtered images. However, local pattern features are computed over a Gabor-filtered image suffer from the same shortcomings as when they are computed on an intensity image. |
| In Gabor as the name suggests the features are computed from Gabor filtered images obtained by convolving the image with multi scale multi orientation Gabor kernels – overall we use 40 different Gabor kernels that span 5 different scales and 8 different orientations over the range 0 to 2p. However in the contrast to all other methods that compute local pattern features (due to dimensionality problem) independently over different Gabor images, the flexibility of LBP(Local Binary Patterns) allows it to capture the patterns cooccurrence statistics over the neighboring scales and orientations by concatenating the computed codes from the neighboring scales and orientations at the local pattern level. |
 |
DIFFERENCES WITH RELATED METHODS |
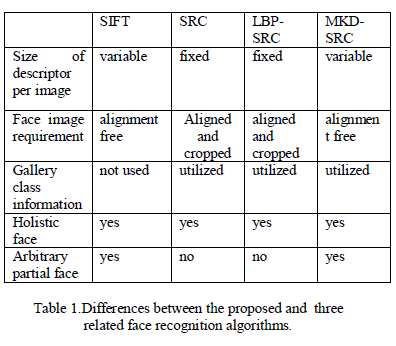
| The differences between the proposed method and three related methods for face recognition are listed in Both SIFT and MKD-SRC use variable-size description; they are alignment free and can be used for both holistic and partial face recognition. In contrast, both SRC and LBP-SRC (which uses LBP histograms instead of pixel values in SRC) use a fixed-length description; they require face alignment and cannot be applied to general partial face recognition problem. All SRC based methods exploit gallery class information for face recognition, but SIFT matches each pair of images separately. The difference among SRC, LBP-SRC and MKD-SRC lies in the feature representation. Since both SRC and LBPSRC require face alignment and use a single fixed-size feature vector to represent an image, each column of their corresponding dictionaries is related to one gallery image. However in such scheme a partial face might have difficulty in alignment and representation due to some unknown missing facial regions. A contrast MKD SRC uses a variable size description; each image is represented by a set of descriptors. |
| The MKD dictionary is composed of a large number of gallery descriptors making a possible to sparsely represent descriptors from a probe face, regardless of being holistic or partial. Note that although LBP SRC also extracts local features (LBP histograms) from the image, they are extracted at a certain fixed number of predefined locations after alignment. Some other existing face recognition approaches based on SIFT include however, all of them depend on pre-aligned face images. |
Fast Filtering |
| In practice, the size (K) of the dictionary D can be of the order of millions, making it difficult to solve (10). Therefore, adopt a fast approximate solution. For each probe descriptor yi, we first compute the following linear correlation coefficients between yi and all the descriptors in the dictionary D: |
| Ci = DT yi, i=1,2,….,n. |
| Then, for each yi , keep only L (L << K) descriptors according to the top L largest values of ci, resulting in a small sub dictionary D(i) M*L. Next, D is replaced by D(i) is adjusted accordingly. |
| Then set L = 100 in our algorithm. According to our previous finding, this approximate solution speeds up the computation with no significant degradation in the recognition performance. The selection of the top L elements (note that this can be done in O (K) by the Introselect algorithm the computation time of the filtering step scales linearly with respect to K (the number of gallery Keypoint). Thus, the algorithm scales almost linearly with respect to the gallery size for each probe image (considering an average number of Keypoint per image). The overall MKD-SRC algorithm is outlined in Algorithm 1. The parameter values has been used in this paper are summarized. They were fixed for all the experiments reported in the paper. |
 |
 |
PERFORMANCE AND COMPARISON |
| The proposed MKD-SRC algorithm was compared to the SIFT matching approach with the same key points and descriptors. The SRC algorithm was not compared because it is not applicable to partial face recognition without prior alignment. The performance of the cumulative matching characteristic (CMC) curves of the two algorithms. It can be seen that the proposed MKDSRC algorithm significantly improves partial face recognition performance compared to that of the SIFT matching. The rank- 1 recognition rate of MKD-SRC is 81.31%, while that of SIFT matching is 58.70%. It appears that the particular region contains rich information for recognition, while face patches with closed eyes, or partial mouth/cheek are not easy to recognize (note that only three images per subject were randomly selected in the gallery set). For a partial mouth patch or a cheek patch, very few Keypoint could be detected. |
References |
|