International Journal of Innovative Research in Science, Engineering and Technology
ISSN ONLINE(2319-8753)PRINT(2347-6710)
ISSN ONLINE(2319-8753)PRINT(2347-6710)
| Sathish.S.N Project Manager, Infosys Limited, Mysore, India |
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Innovative Research in Science, Engineering and Technology
This paper aims to explain the concept of Data Mining features by taking a case study/project for analysis.
Keywords |
| Data Mining; Data Warehouse; Clementine; Association Rule; SPSS |
INTRODUCTION |
| Introduction to Case: |
| This case is about analyzing crimes which was recorded a stored in a data file. Objective of the case analysis is to find the following: |
| Explore data and explain patterns in “volume” crimes |
| Find related crimes which seem to have been committed by the same offender |
| Find related crimes even if they are widely distributed in time and geography |
| Introduction to Data: |
| The fictional crime reports used for the demo consist of 662 crimes (rows) which has taken place in a city. Each record contains 46 fields. These data are available in a .csv file. Let’s look at the fields which will go through analysis. |
 |
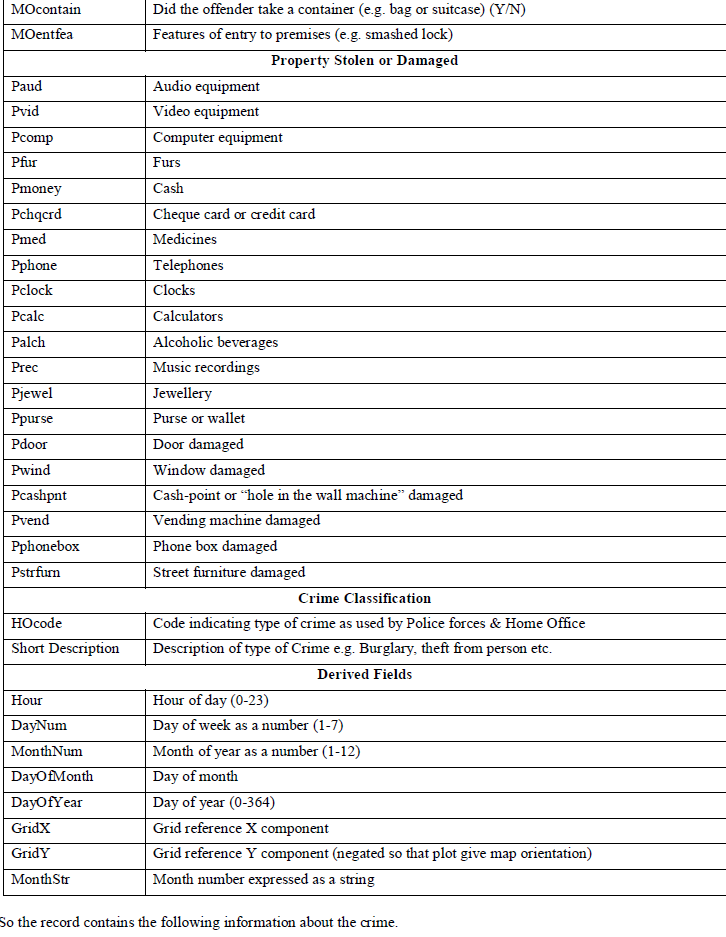 |
| Crime Report Information |
| o Ref no., date, time, day of week, grid reference of location |
| Modus Operandi |
| o Method of entry, point of entry, security features, method of dealing with alarm, what the offender posed as etc. |
| Property stolen or damaged |
| o Audio equipment, video equipment, computer, purse etc. |
| Other |
| o Home Office code, short description |
STREAM |
| Streams are created by drawing diagrams of data operations relevant to your business on the main canvas in the interface. Each operation is represented by an icon or node, and the nodes are linked together in a stream representing the flow of data through each operation. |
| Based on the case, we have designed the below stream: |
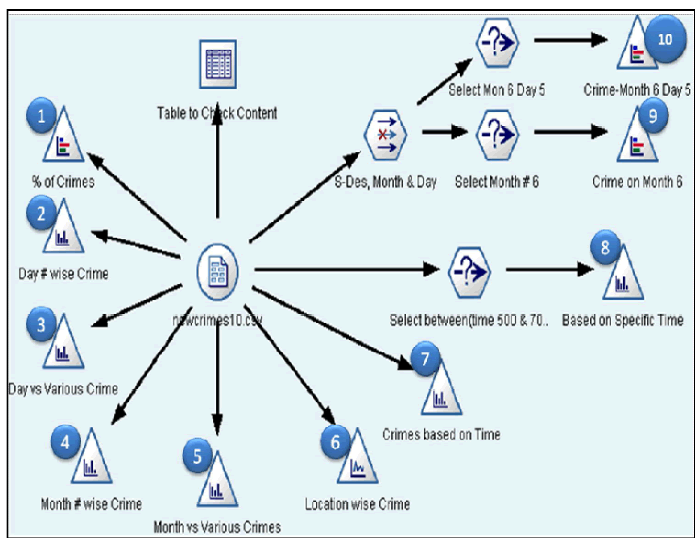 |
| Let’s do the analysis based on the above stream to derive some information from data which is provided. Lets first have look at all the nodes used in the above stream and find out their usage. |
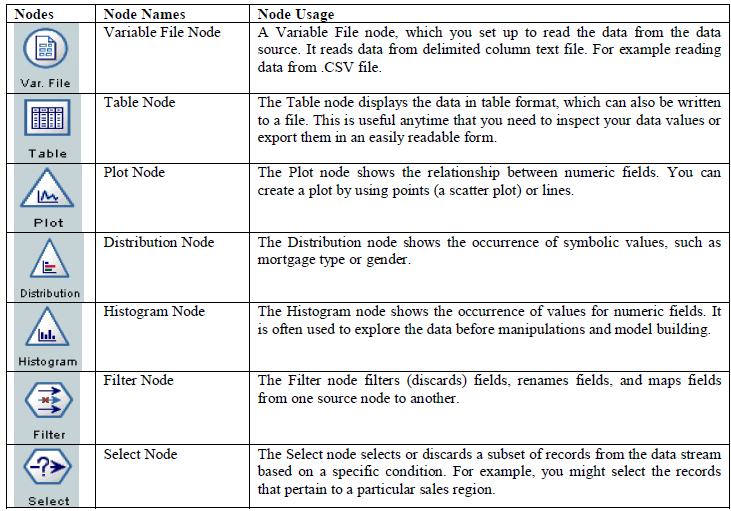 |
| Analysis: |
| 1. Figure 1 and 2 below shows the percentage (%) and the count of various types of crimes done from the dataset. |
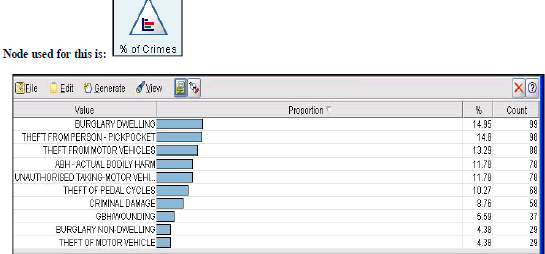 |
| From the above diagram we can conclude that Crime like “Burglary Dwelling” do happens more often. This represents % of occurrence and the number of occurrence of each crime from the dataset. Below figure (Fig-2) also represents the same information as above. |
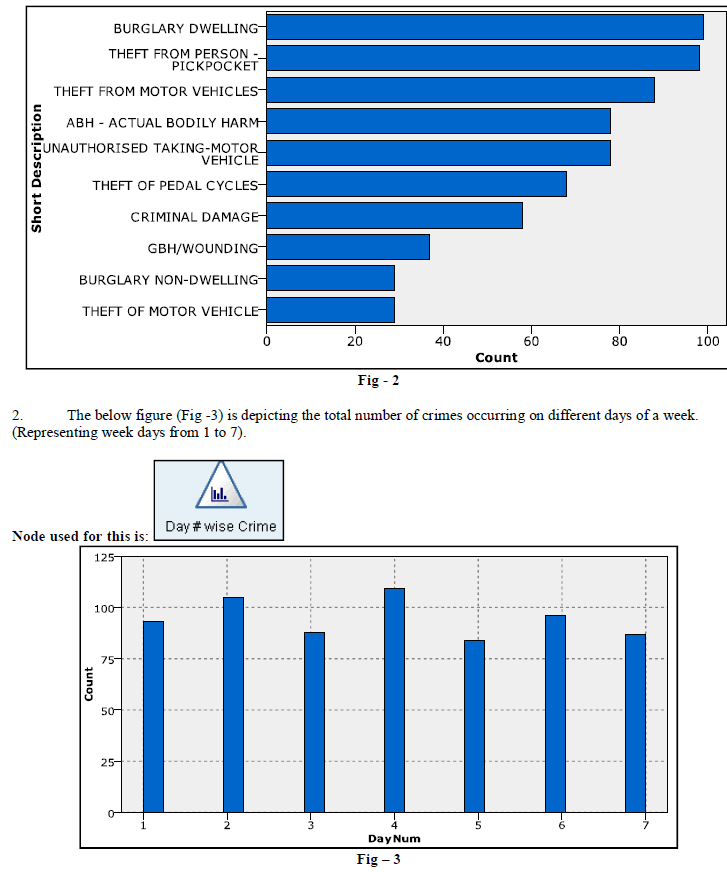 |
| Based on the output, we can say the maximum crime happens in Day2 and Day4. But, it is not very significant. Then, let us find what are the types of crime happens on those days and also, which crime is significant on that day. |
| 3. Below figure (Fig-4) represents the percentage of crimes occurring on each day. We observe that on day maximum number of crimes. |
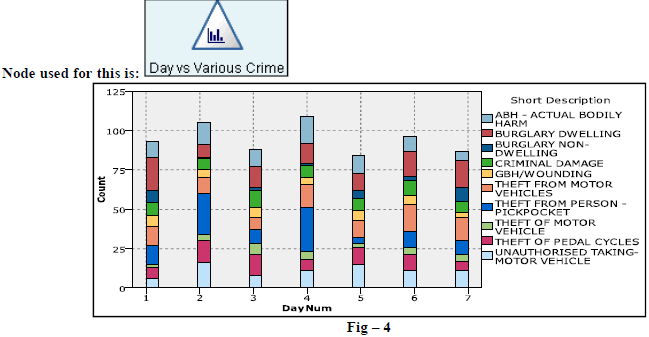 |
| From the above, we found that on Day2 and Day4 the ‘Theft from Pick Pocketing’ crime is happening. It leads one more question ‘what are events which happens on those day i.e Day2 and day4 which leads to the crimes?” |
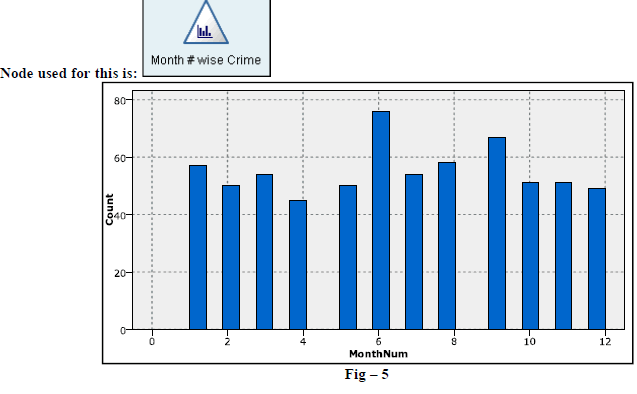
| 4. Below figure (Fig-5) represents the occurrence of crimes month wise and observation gives outcome as 6th month we do see more crimes. |
 |
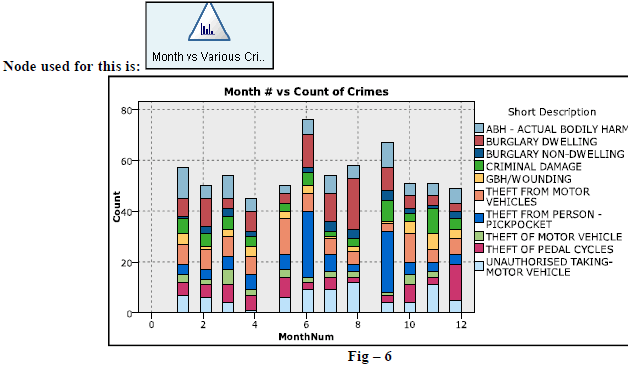
| 5. Below figure (Fig-6) represents the occurrence of various crimes month wise and observation gives outcome as 6th month we do see more crimes. |
 |
| 6. Below figure (Fig-7) represents the occurrence of various crimes location wise. In the data file location is provided by using coordinate values i.e. X Grid and Y Grid. |
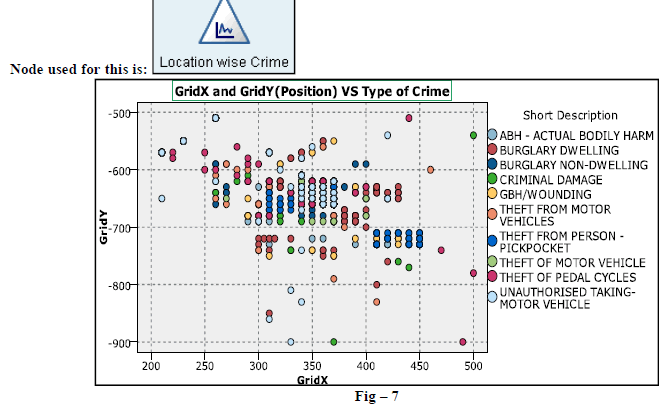 |
| 7. Below figure (Fig-8) represents the occurrence of various crimes based on the timing i.e. ranging from 1 to 2399(Representing 24 Hrs of the Day). |
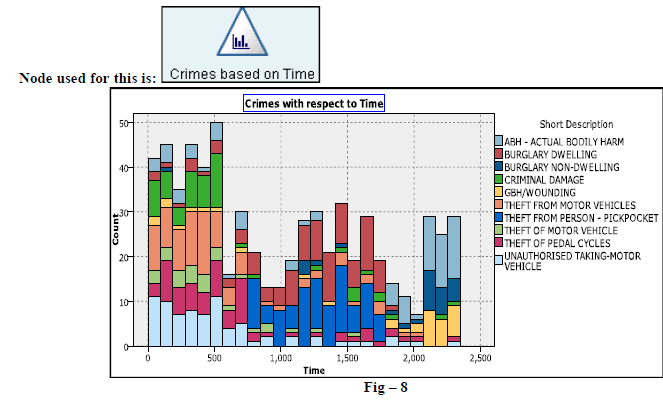 |
| 8. Below figure (Fig-9) represents the occurrence of various crimes based on the timing between 500 to 700. Here we have done slicing based on Fig-8 analysis. Here we have taken the help of “Select” Node to filter specific records. |
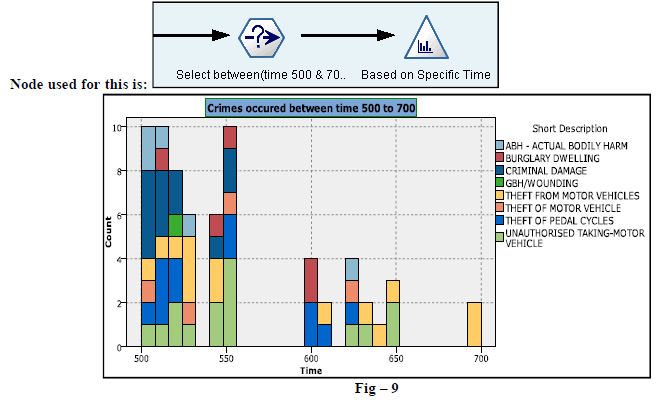 |
| 9. Below figure (Fig-10) represents the various crimes which has occurred during month number 6. Here we have taken the help of “Select” Node to filter specific records for month 6. |
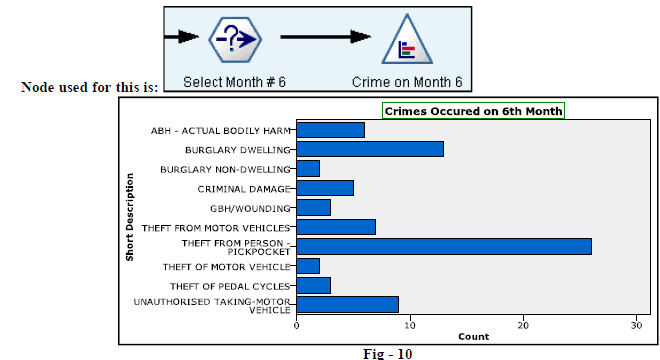 |
| 10. Below figure (Fig-11) represents the various crimes which have occurred during month number 6 and on 5th Day. |
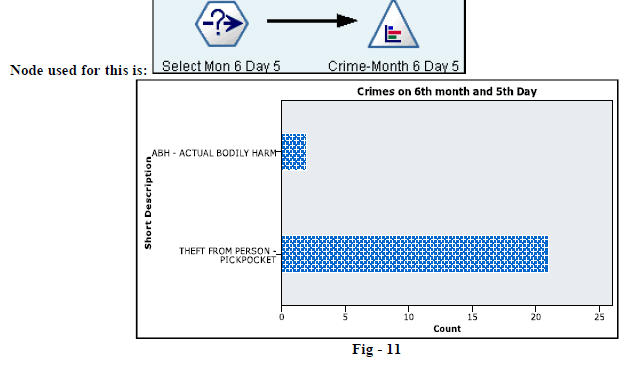 |
| 11. Below figure (Fig-12) represents the way to the filtering criteria which is going to pick up the records, which has the time field value between 500 and 700. This is used in the analysis number 8. |
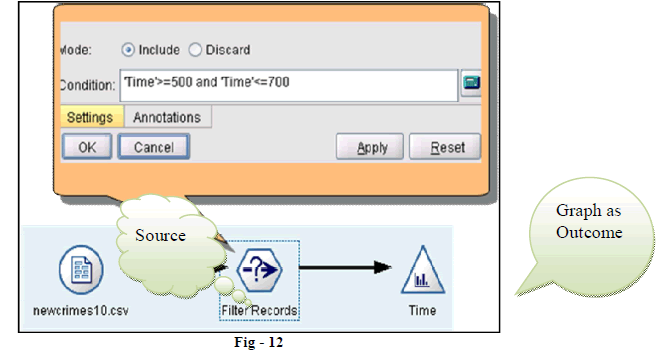 |
CONCLUSION |
| As we have said at the beginning that, from a huge dataset, how quickly we can be able to find out information which can help us in doing better planning. This tool do have very good features to do various kind of analysis. Here we have taken only those nodes or functionality in to consideration, which was required for this case. |
References |
|