International Journal of Innovative Research in Science, Engineering and Technology
ISSN ONLINE(2319-8753)PRINT(2347-6710)
ISSN ONLINE(2319-8753)PRINT(2347-6710)
D.Anandha Kumar1 and Dr.P.Raviraj2
|
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Innovative Research in Science, Engineering and Technology
Requirement Traceability is one that tracks software project requirement in its source code for maintaining the consistency between them. It is an important process that it could be useful for the construction of software project in time within cost. Therefore it helps to complete the software project in a successful manner. Such an important process is needed to be enhanced for providing better accuracy of trust to requirement traceability link. In this paper, the user’s updating activity like bug tracking system, forum, cvs/svn repositories are used to improve the trust of requirement traceability link so as to complete the software project in more successful manner.
Keywords |
| Requirement traceability link, Experts, Bug tracking system, Forum, Repositories. |
INTRODUCTION |
| Requirements traceability could be used to describe and track the life of a requirement in software development process. That is in all phase of software development the requirements are tracked to find whether the source code is consistent to its requirement which is provided by the client in association with the requirement specification engineer. This process if done manually will lead to a costly task in software engineering. There comes the need for automatically tracing requirement in the source code. In traceability, it is important to consider of what and how to access and present the software artifacts. This lead us to know who want that software artifact, when or why that is wanted, also the software project characteristics. In requirement traceability, there arises a need to know the working practice. That is to know that whether there were sufficient resources, time support, ongoing cooperation and coordination or not. Requirement traceability also depends on the awareness of information required to trace, the ability to obtain and document required information, and the ability to organize and then maintain required information for flexible traceability of requirements [1]. |
| A. Enhancement By Information Retrieval Techniques |
| Information Retrieval (IR) approaches [2] are studied to be useful in recovering traceability links between freetext documentation and source code. This IR-based traceability recovery approaches could provide ranked lists of traceability links. Yet, the precision and recall value did not meet the saturation point. In reference [3], they have used the web trust models [4], [5], [6], [7] to improve precision and recall of traceability links. In this web trust model the cvs/svn repository are used as a main data to improve the value of precision and recall value. In this requirement traceability link’s improvement process the cvs/svn change log and the bug tracking system could be taken as expert. Based on the opinion of the expercould be used to remove and or adjust the rankings of the IR-based approaches produce traceability link. They [3] used Vector Space Model (VSM) based information retrieval approaches to produce the baseline requirement traceability link. Then the baseline link is combined with the trust model to give more surety to the baseline link. Thus it is studied that the combined use of IR-based approaches and trust model will result in the improvement of precision and recall value of requirement traceability link. |
| B. Uses Of Traceability Link |
| The traceability links provide hints on where to look for requirement’s implementation in code. The main role of the traceability links is to assist programmers in the assignment of a concept to the code and in the aggregation to abstract concepts. Fig. 1 shows that the requirement is tracked in the source code for its consistency. Here the requirement is given by the customer and the source code are stored in cvs/ svn repository. The CVS/SVN repository contains the same project with different version. These versions are created by the developers, whenever they update and compile the project. The source code with particular version which satisfies the requirement is used to make a link with the appropriate requirement. This link is called requirement traceability link (RTL) which is a set composed of three elements, they are requirement, source code and similarity value. |
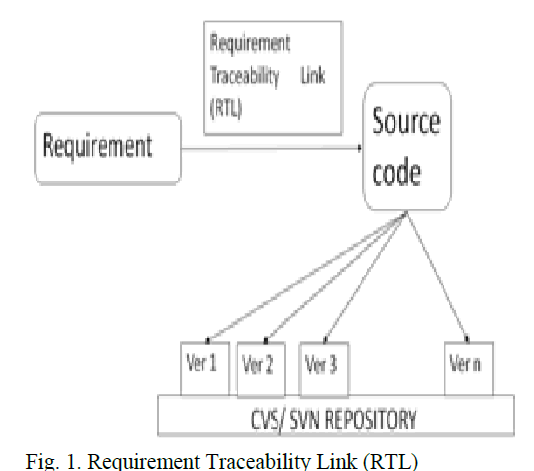 |
| Traceability links between code and other sources of information are a reasonable aid to perform the combined study of heterogeneous information and, finally, to associate domain concepts with code and vice-versa. |
| Traceability links between the requirement and the code are a solution to locate the areas of code that contribute to implement specific user’s functionality [8], [9], [10]. This is helpful to appraise the comprehensiveness of an implementation with respect to stated requirements, to devise complete and comprehensive test cases, and to infer requirement exposure from structure exposure during test time. Traceability links between requirements and code can also help to identify the code areas directly affected by a repairs request as confirmed by an end user. Finally, they are useful during code check up, on condition that inspectors with clues about the goals of the code at and in quality assessment, for a case in point, singling out loosely-coupled areas of source code that implement diverse requirements [15]. |
ENHANCEMENT BY PREPROCESSING REQUIRMENT AND SOURCE CODE |
| The requirement specification and the source code are the two documents which are considered as the higher level and lower level document. Software artifact’s documentations are mostly informally expressed. Such documents possibly related to requirement, bug logs, source code and related maintenance reports. Information retrieval could be used to recover traceability links between source code and free text requirement specification documents. For that it is needed to preprocess meaningful name like class name. Class will mostly implement most of the requirement in the source code. Therefore it is important to know the applicationdomain knowledge which would help to improve the semantic of the class identifiers. These identifiers can help to associate between high-level document and lowlevel document. |
COMPARING THE INORMATION RETRIVAL MODELS |
| A. Information Retrieval (IR) |
| The software engineer needs to trace the requirement in the source code which was developed. This is done to ensure that the developer is only doing what the client required. Here the information needed to retrieve is that the link between the client’s requirement and the source code developed. This link is called requirement traceability link. In information retrieval the major models to retrieve information are the Boolean model, the statistical model which also includes the vector space and probabilistic retrieved model [11]. While retrieving the requirement traceability link there may be two problems [12]. First, they retrieve irrelevant links between the requirement and source code. Second they do not retrieve all the relevant links. |
| B. Basic Measures For Retrieval Methods |
| The two measures mostly used to evaluate the effectiveness of a retrieval method are precision and recall. Let the set of links relevant to the requirement traceability be denoted as {relevant links} and the set of links retrieved be denoted as {retrieved links}. The set of links that are both relevant and retrieved is represented as {relevant links} {retrieved links}. Precision is identified as the percentage of retrieved links that are in fact relevant to the traceable requirement. This indicates the correct link retrieved response. It is formally depicted [3] as |
 |
| enhancement is provided for retrieving reqrirement traceability link. |
REQUIREMENT TRACEABILITY RETRIEVAL PROBLEM |
| A. Problem in Requirement Traceability |
| Let us consider the problem with some assumption. For example, in a banking project in version 1 the developer mainly concentrated on "balance enquiry module" and let it uncompleted. |
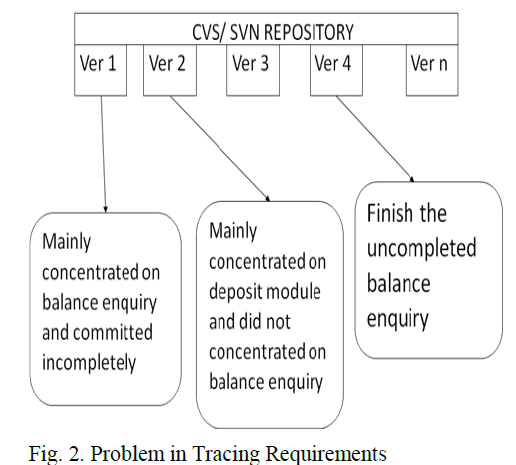 |
| Let us consider the problem with some assumption. For example, in a banking project in version 1 the developer mainly concentrated on "balance enquiry module" and let it uncompleted. In version 2 , the developer mainly concentrated on " deposit module" and did not concentrated on balance enquiry. In version 4, they finished the "balance enquiry module" which was incomplete in version 1. Likewise, in some version of cvs/svn repository developer took some requirement and kept which is in completed but in future the developer complete those requirement left incomplete in future version. Here the solution needed is to be trace the particular cvs/svn version that contains the completed requirement’s source code. |
| B. Ranking Process of RTL |
| The ranking process is required to give suggestion to the developer for to find automatically which version contains the source code of fulfilled requirements. Since the accuracy of textual similarity is less, ranking is used for second, third options to satisfy the develop need of requirement traceability. The ranking process is performed by maintaining the requirement by maintaining the requirement traceability link (RTL). |
| Requirement traceability link is a set contains the requirement, source code and its similarity value as elements. Here for illustration, version1 having requirement traceability link as { R1, S1,SV=6%} and version 2 {R1, S1, SV=9%} and version 3 {R1, S1, SV=5%}. While comparing the three versions version 1 is ranked in second position, version 2 is in first position and version 3 ranked as third position. |
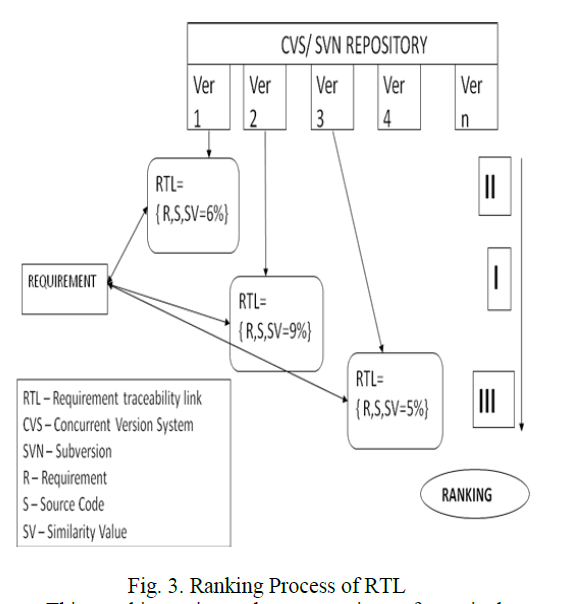 |
| This ranking gives the suggestion of particular requirement traced to find its full-fledged or completed source code version to frame the final output software and also in the development phase of software engineering. |
| C. Using Bug Tracking System |
| Since the textual similarity is not more accurately produce the best matched requirement traceability link, one have to move to some other means. So, the Bug tracking system is taken to improve the already made requirement traceability link with textual similarity measure. |
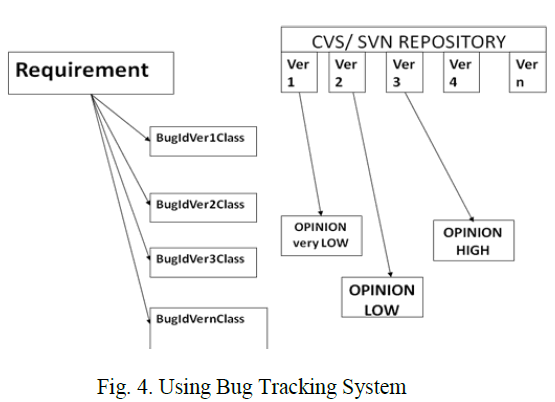 |
| The developer’s updating activity may be tracking the different modules’ bug. This bug is identified by bug tracking IDs. For illustration for a particular requirement’s coding in different version, we may count in which version; the bug post is found more. We may ReLink the textual similarity based ranking to this bug count based ranking which may future improve the accuracy. |
| D. Using Forum System |
| In forum, individual messages are organized by topic and discussion title. A discussion (also known as a "thread") is a series of messages along a specific topic of conversation. Each discussion begins with a comment or question that elicits feedback from others. By reading each post—that is, each individual message—in a discussion, one can see how it has evolved. |
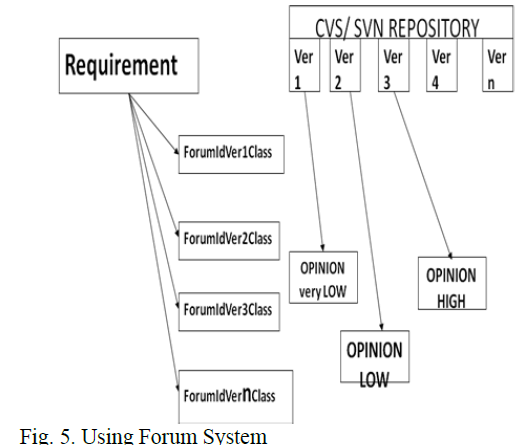 |
| By using forum as an expert system one can enhance the trust of the baseline requirement traceability links. |
| E. Necessity of ReLink |
| The relink or reranking is required to improve the requirement traceability link produced with textual similarity between the source code and requirement. |
 |
CONCLUSION |
| In finding or tracing the link between requirement and the source code automatically is the aim. But the accuracy differs from different methods. The efficiency of requirement traceability link is measured by the well known measure like precision, recall and fscore; through these measures the efficiency of the information retrieval techniques for the requirement traceability can be found. This technique of relink is used by the authors in the reference paper given below and used the same here for this technique that serves different need of requirement traceability. |
References |
|