International Journal of Innovative Research in Science, Engineering and Technology
ISSN ONLINE(2319-8753)PRINT(2347-6710)
ISSN ONLINE(2319-8753)PRINT(2347-6710)
J.Ida princess1, V.Nithya1, P.Arjun2
|
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Innovative Research in Science, Engineering and Technology
Cartoon is popular and successful media in our life, its creation is usually of high cost and labor intensive. The computer assisted systems are designed to reduce the time cost of the cartoon production and to develop novel systems that can synthesize new cartoons by reusing existing cartoon materials. For that purpose, we propose a method for cartoon character retrieval with two applications, namely content based cartoon image retrieval and cartoon clip synthesis. In order to retrieve similar cartoon characters two issues are considered. The first issue is how to represent the cartoon characters. The color histogram, hausdorff edge feature, skeleton features and curvature scale space are used to represent the color, shape and gesture of the cartoon characters. The second issue is to combine these features using semi-supervised multi-view subspace learning algorithm. This algorithm uses patch alignment framework to construct and align local patches. Aligned patches have high dimension, it is not efficient to retrieve similar character. In order to improve the efficiency, alternating optimization is utilized for reducing high to low dimensional subspace. Within that space similar characters can be retrieved. This method is useful for animators and cartoon enthusiasts to effectively create new animations.
Keywords |
| Cartoon character retrieval, Multiview subspace learning, clip synthesis, patch alignment framework. |
INTRODUCTION |
| Cartoon plays important roles in many domains, e.g., entertainment, education, and advertisement. It has attracted much research attention in the field of multimedia and computer graphics. To produce cartoon movie clips, key-frames drawing, in-betweening, and painting require a large amount of human labor. |
| Therefore, it is valuable to develop a computer-aided system to reduce the labor in cartoon clip production. There is a large scale cartoon library which consists of various animation materials, including character design, story board, scenes, and episodes. It is useful for animators and cartoon enthusiasts to effectively create new animations by reusing and synthesizing. But this is too complicated for non-professional users who may want to produce cartoon clips either for fun or other purposes. In the cartoon industry, there is existing software to reduce the human labor in producing new cartoon clips. For example, Toon Boom [15] is well-known commercial software for cartoon creation, which covers the entire animation workflow from sketching to publishing. By using this software, the cartoonists can draw a few cartoon images and reuse them to produce new cartoon clips. However a limitation is that Toon Boom does not support cartoon image retrieval. |
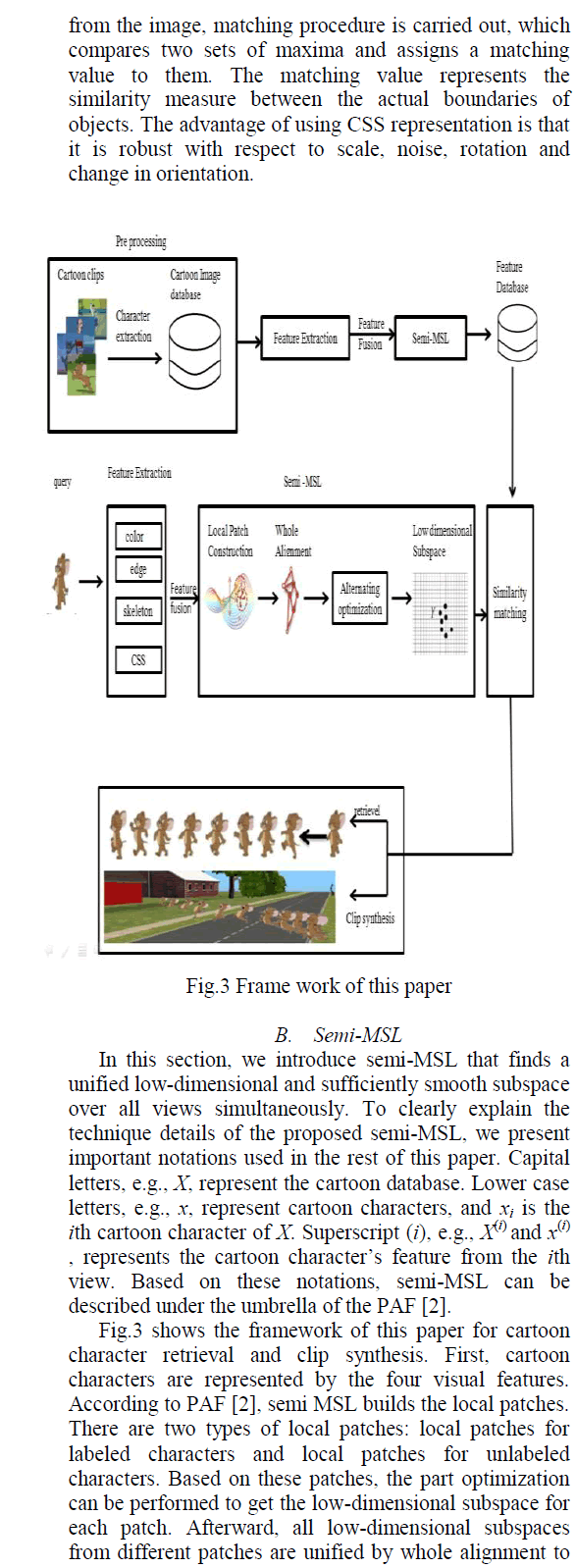
| In this paper, to perform cartoon image retrieval and clip synthesis four features are considered. i.e., color histogram (CH), edge feature (EF), skeleton feature(SF) and curvature scale space(CSS) .These features reveal different characteristics of a cartoon character. But the simple concatenation of these features results in curse of dimensionality problem. |
| For this purpose semi supervised Multiview subspace learning algorithms have been developed. Semi-MSL uses âÃâ¬Ãâ¢patch alignmentâÃâ¬Ãâ framework (PAF) [2] that has two stages: local patch construction and whole alignment. Each patch is constructed by one sample and its related ones according to both the characteristics of the data set and the objective of the algorithm. In the whole alignment stage, all part optimizations are integrated together to form a consistent global coordinate for all independent patches. After alignment, it obtains a high dimensional subspace which is not efficient to retrieve the similar cartoon characters. Thus Semi-MSL adopts an alternatingoptimization [16] which is used to combine multiple features from different views for dimensionality reduction. Finally, a compact subspace is achieved for subsequent retrieval and synthesis. |
| The following is the organisation of the remainder of this paper.In Section II related works are investigated. Section III, Cartoon character retrieval is analyzed. The results of experiments on cartoon character retrieval and clip synthesis are given in Section IV. Finally, Section V concludes this paper. |
RELATED WORKS |
| In this section, we briefly review related works (content based image retrieval and clip synthesis) and discuss the difference between them. |
| A. Content Based Image Retrieval |
| Content-based image retrieval (CBIR) is a long standing research topic in the field of multimedia. In the early years, CBIR algorithms mainly use low-level visual features, such as color feature and texture feature to compute image similarity. However, despite the intensive research effort, the performance of CBIR systems is not satisfactory due to the well-known semantic gap[11]. In [12] and [13] Haseyama and Matsumura have proposed a cartoon image retrieval system, where they define Regions and Aspects to compute cartoon image similarities. However, the partial features are not suitable for cartoon character gesture recognition. It can only be used to retrieve face image of cartoon characters. |
| B. Cartoon Clip Synthesis by Recycling |
| Recently, a few systems have been proposed to synthesize new multimedia data by reusing existing resources. For example, a system is proposed in [10] to synthesize new video from a series of existing video clips by reordering the original video frames. In [3] Juan and Bodenheimer developed Graph based cartoon clip synthesis (GCCS) that combines similar characters into user-directed sequence based on dissimilarity measure in edges. It performs well for simple cartoon characters. GCCS fails to generate smooth clips because edges can encode neither the color information nor the gesture pattern. Yang et al. [6] recently proposed a Retrievalbased Cartoon Clip Synthesis (RCCS) that combines similar characters based on dissimilarity measure in cartoon characters motion and edges. Based on these two features, RCCS uses an unsupervised bidistance metric learning (UBDML) algorithm to measure dissimilarity. Drawback of RCCS is that, they fail to retrieve dissimilarity in color and gesture. Furthermore they developed Cartoon gesture space (CGS) [7] which represents the characters based on color, edge and motion, cannot accurately characterize the gestures of character. |
| C. Feature Fusion |
| There are a growing number of scenarios in pattern recognition where different features are used. For feature fusion three algorithms are used i.e., multiple kernel learning (MKL), Gaussian process (GP), and features concatenation. These algorithm support only labeled information. In [17] Many researchers have introduced various spectral methods in the field of machine learning and data mining. Most of them directly concatenate different feature vectors to produce a high-dimensional vector and then perform dimension reduction. However the above mentioned method does not support unlabeled data. This problem can be overcome by using a method like semi-MSL which supports both labeled and unlabeled data. |
CARTOON CHARACTER RETRIEVAL |
| The similar cartoon characters has to be retrieved from cartoon database, which is prepared by extracting the characters from cartoon videos as shown in fig 1using LOG (Laplacian of Gaussian) filter , then color histogram, hausdorf edge feature, skeleton features and curvature scale space are extracted from cartoon characters. Fusion of these features is done by using semi-MSL algorithm. Alternating optimization are utilized by semi-MSL to obtained the low dimensional subspace. Based on each low dimensional subspace, a standard retrieval procedure is conducted for all characters in the database. For example, one cartoon character is selected as a query, and then all the other characters in the database are ranked according to the Euclidean distance to the query computed in the low-dimensional subspace. For each query cartoon character, the top 10 characters are obtained. The detailed work of the project is explained in the following sections (cartoon image feature extraction and semi-MSL). |
| A. Cartoon Image Feature Extraction |
| The data comes from 2D cartoon videos, which contain a character as shown in Fig.1. When the animator makes the cartoon, a sketch is painted before colorization. Then the edge around the character can be easily detected by using Laplacian of Gaussian (LOG) filter. After edge detection, the flood fill algorithm is used to fill the region surrounded by the closed edge. Finally, the cartoon character can be extracted by background subtraction. After obtaining the cartoon characters X = [x1, . . . , xN], we perform feature extraction CH x i CH , HEF xi HEF , SF xi SF , CSS xi CSS which is given in the following sections. |
 |
| 1) Color Histogram |
| CH is an effective representation of the color information. Color is one of the most reliable visual features that are also easier to implement in image retrieval systems. Color histogram is the most common technique for extracting the color features of colored images. It tells the global distribution of colors in the images. It is defined as the distribution of cartoon characters. |
| In this paper each component of RGB color spaces are quantized into four bins (0–63, 64–127, 128– 191, and 192–255). Therefore, CH comprises 64 (4 × 4 × 4) bins. In this case, each component of CH for cartoon character xi is defined as xi CH(j) = cj/Ci where j=1, 2,...,64 where cj is the number of pixels with value j and Ci is the total number of pixels in xi. The distance between the characters cannot be measured accurately by using CH alone. Thus, it is necessary to consider the cartoon character’s shape and gesture information. |
| 2) Hausdorf Edge Feature |
| Shape is also important image content used in retrieval. The primary mechanisms used for shape retrieval include identification of features such as edges, lines, regions and boundaries. Edge features, which contain information about the shapes of objects, are frequently used to measure the dissimilarity between objects. To efficiently represent the character’s shape, we use a modified Hausdorff distance to calculate the edge distance. Let Ei be the edge point set of the cartoon character xi. Given two cartoon characters xi and xj , h( Ei, Ej) is defined as, |
 |
 |
 |
 |
| construction for unlabeled characters is used to reveal the manifold structure of data in the original high dimensional space. To preserve the local geometry of the patch, the nearby characters should stay nearby in the lowdimensional subspace. |
| b) Whole Alignment |
| For each patch Xj (i) , there is a low-dimensional subspace Y j (i). All Yj (i) can be unified together as a whole one by assuming that the coordinate for Yj (i) = [yj (i) , yj1 (i) , . . . , yjk (i) ] is selected from the global coordinate Y = [y1, . . . , yN], i.e., Yj (i) = Yj S(i) , wherein Sj (i) ∈ RN×(k+1) is the selection matrix. |
| c) Alternating Optimization |
| Because of the complementary characteristics of multiple views to each other, different views definitely have different contributions to the final low-dimensional subspace. In oder to well explore the complementary property of different views, a set of nonnegative weights σ = [σ1, . . . , σt] is imposed on different views independently. The σ with a larger value means that the view X(i) plays a more important role in obtaining the lowdimensional subspace. σl = 1 corresponding to the minimum tr(Y LS(i) YT ) over different views, and σl =0 otherwise. It means that only one view is finally selected. This solution cannot explore the complementary characteristics of different views. In order to avoid this problem, we set σi ← σi r with r > 1. The multiview subspace learning is realized by summing all views, |
 |
EXPERIMENTS |
| To test the performance of the proposed method, we collected Tom and Jerry cartoon images from the Disney cartoon series. There are 1000 cartoon images in the database which is used for experiment. Feature are extracted as explained in section 3. After that, a semi- MSL is constructed for each cartoon character. We test the proposed method both in content-based cartoon image retrieval and cartoon clip synthesis. |
 |
| A. Retrieval Evaluation |
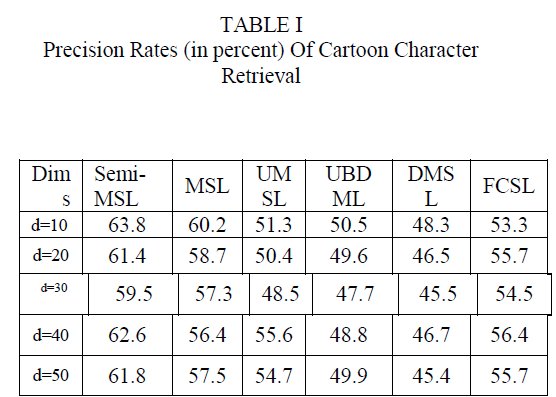
| First, the low dimensional subspaces of the cartoon database are learned by the subspace learning algorithms, including semi-MSL, MSL, UMSL, UBDML, CGS, FCSL, DMSL, and SSL, and second, based on each lowdimensional subspace, a standard retrieval procedure is conducted for all characters in the database. In detail, for each category, one cartoon character is selected as a query, and thus, 100 cartoon characters are used as queries, respectively. Then, all the other characters in the database (including other categories) are ranked according to the Euclidean distance to the query computed in the low-dimensional subspace. For each query cartoon character, the top N characters are obtained, among which the number of characters from the same class as the query shape is recorded. The precision rate, shown in table 1 is the ratio of the recorded number to N. |
| We first compare semi-MSL against other methods with different dimensionalities d on the database of Tom. Here, ASSL means the average performance of SSL with different features. In Table I, the dimensionality increases from 10 to 50, and we observe that the precision rates of semi-MSL are significantly better than those of the other methods. |
| Based on these results shown in Table I, we observe that semi-MSL achieves satisfactory performance when the dimensionality is around ten. The experiments conducted on the databases of Jerry also suggested similar results. |
| B. Clip Synthesis |
| SSL considers only one feature that is hausdorf edge feature for performing cartoon clip synthesis, hence the clip synthesized by using SSL is not smooth. In case of RCCS it uses two features, edge and motion direction feature. The clips synthesized by semi-MSL is smoother than SSL and RCCS, because RCCS neglects the color information in the distance metric learning, the characters in the synthesized results may have different colors and SSL uses only edge feature, hence it is not efficient. Hence in this section, we show that semi-MSL outperforms the SSL used in GCCS and the UBDML used in RCCS for cartoon clip synthesis. |
CONCLUSIONS |
| In this paper, we have defined Four visual features, i.e., CH, HEF, and SF, CSS to represent the color, shape, and gesture information of a cartoon character. However HEF feature is used to extract the shape of the cartoon character, it is not efficient. Because of, affine transformation. So we proposed CSS feature for extracting shape with affine transformation. To efficiently and effectively combine these visual features for subsequent retrieval and synthesis tasks, we developed a new multiview learning method named semi-MSL. It encodes different features from different views in a physically meaningful subspace. In this unified subspace, the Euclidean distance can be directly used to measure the distance between two cartoon characters. After ranking similar cartoon characters can be retrieved. Experimental evaluations on cartoon character retrieval and clip synthesis suggest the effectiveness of the visual features and semi-MSL. |
References |
|