International Journal of Innovative Research in Science, Engineering and Technology
ISSN ONLINE(2319-8753)PRINT(2347-6710)
ISSN ONLINE(2319-8753)PRINT(2347-6710)
A Ramachandran1, M Sai Kumar2, Dr. C. Nalini2
|
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Innovative Research in Science, Engineering and Technology
Image re-ranking, is an effective way to improve the results of web-based image search and has been adopted by current commercial search engines such as Bing and Google. When a query keyword is given, a list of images are first retrieved based on textual information given by the user. By asking the user to select a query image from the pool of images, the remaining images are re-ranked based on their index with the query image. A major challenge is that sometimes semantic meanings may interpret user’s search intention. Many people recently proposed to match images in a semantic space which used attributes or reference classes closely related to the semantic meanings of images as basis. In this paper, we propose a novel image re-ranking framework, in which automatically offline learns different semantic spaces for different query keywords and displays with the image details in the form of augmented images. The images are projected into their related semantic spaces to get semantic signatures with the help of one click feedback from the user. At the online stage, images are re-ranked by comparing their semantic signatures obtained from the semantic space specified by the query keyword given by the user. The proposed query-specific semantic signatures significantly improve both the accuracy and efficiency of image re-ranking. Experimental results show that 25-40 percent relative improvement has been achieved on re-ranking precisions compared with the state-of-the-art methods.
Keywords |
| Image search, image re-ranking, semantic space, semantic signature, keyword expansion, one click feedback. |
INTRODUCTION |
| WEB-SCALE image search engines mostly use keywords as queries and rely on surrounding text to search images. The user suffers from the ambiguity of the given query keywords, since it is hard for users to accurately describe the visual content of target images by only using keywords. For example, using “apple” as a query keyword, the images which are retrieved belongs to different categories, such as “red apple,” “apple organization logo,” and “apple laptops”, “apple iphones” In order to solve the ambiguity, content- based image retrieval [2], [3] with relevance feedback [4], [5], [6] is widely used. The feedback will be increased by 1 when the user clicks that particular image. Using relevance feedback one can easily go through the image in which many have chosen to use the same image. When the other user uses the same keyword to find the image in the web then the highest feedback received by the particular image will appear first. Images are re-ranked based on the learned visual similarities. However, for web-scale commercial systems, User’s feedback should be limited to the minimum without any online training. |
| Online image re-ranking [7], [8], which limits User’s effort to just one-click feedback, which is an effective way to improve search results and the interaction between the user and web is very simple. Major web image search engines have used this strategy [9]. The query keyword input is given by the user; a pool of images relevant to the query keyword is fetched by the search engine according to a word-image index file which is stored. Usually the size of the returned image pool is fixed, e.g., containing 900-1000 images. |
| By asking the user to select a query image displayed, so that it reflects the user’s search intention from the pool, and the remaining images in the semantic space are re-ranked based on their visual similarities with the query image. The visual features of images and the word image index file are pre-computed offline and stored.1 the main online computational cost is on comparing visual features. To get high efficiency, the visual feature vectors need to be short and their matching needs to be fast. Few popular visual features are in high dimensions and efficiency is not satisfactory if they are directly matched. |
WEB MINING |
| The world has been using the internet drastically and because of that the World Wide Web has been dramatically increased due to the usage of internet. The web acts as a medium for the user where large amount of information can be obtained for the use at low cost. The information available in the web is not only useful to individual user and also helpful to all business organization, hospitals, educational purposes and some research areas. The information available in the online is unstructured data because of development technologies. Web mining can be defined as the discovery and analysis of useful information from the World Wide Web data. Web mining is the application of data mining techniques to discover patterns from the web. It can be divided into three different types, which are Web content mining, Web usage mining and Web structure mining. Web structure mining involves web structure documents and links. Web content mining involves text documents and structures. Web usage mining includes data from user registration and user transaction. WWW provides a rich set of data for data mining. The web is dynamic and has very high dimensionality. It is very helpful to generate a new page, many pages can be added, removed and can be updated at anytime. Data sets available in the web is very large and occupy from about ten to hundreds of terabytes, and needs a large number of servers. A web page contain three forms of data, structured, unstructured and semi structured data. A number of algorithms are available to make a structured data, one such algorithm is a fuzzy self constructing. An unstructured data can be analyzed using term frequency, document frequency, document length, text proximity. Searching in the web has been improved by adding structured documents. Using clustering techniques we have to restructure the web information. |
| The upcoming section describes about the related work, intelligent semantic web- search engine, the methodologies used in this paper, experiments and results, and the screenshots to explain the concept. |
RELATED WORK |
| In this paper [3], Classic content-based image retrieval (CBIR) takes a single query image, and retrieves similar images. This author defines localized content-based image retrieval as a CBIR task where the user is only interested in a portion of the image, and the rest which are displayed is irrelevant. Unless the user explicitly marks the region of interest, localized CBIR must rely on multiple images (labeled as positive or negative) to learn which portion of the image is of interest for the user. A challenge for localized CBIR is how to represent the image to capture the content. The author presents and compares two novel image representations, in which it extends traditional segmentation based and salient point-based techniques respectively, and to capture content in a localized CBIR setting. |
| In this paper [10], the author proposes a novel and generic video/image re-ranking algorithm, Information Bottleneck re-ranking, which reorders results from text only searches by discovering the salient visual patterns of relevant and irrelevant shots from the approximate relevance provided by text results. The IB re-ranking method, based on a rigorous Information Bottleneck (IB) principle, which finds the optimal clustering of images that preserves the maximal mutual information between the search relevance and the high-dimensional low-level visual features of the images in the text search results. The experimental analysis has also confirmed that the proposed re-ranking method works well when there exist sufficient recurrent visual patterns in the search results, as often the case in multi-source news videos. With the help of the re-ranking technique the image can be ranked upon the user’s search intention.. |
| The re-ranking of images can be re-ranked based upon the feedback from the user. In this paper [11], relevance Feedback [12] is an important tool to improve the Performance of content-based image retrieval (CBIR) [3]. In a relevance feedback process, the user first labels a number of relevant retrieval results as positive feedback samples and some irrelevant retrieval results as negative feedback samples. A CBIR system refines all retrieval results based on these feedback samples. These two steps are carried out iteratively to improve the performance of the image retrieval system by gradually learning the user’s preferences. Relevance feedback schemes based on support vector machines (SVM) have been widely used in content-based image retrieval (CBIR). However, the performance of SVM-based relevance feedback is often poor when the number of labeled positive feedback samples is very small and this is mainly due to three reasons: 1) an SVM classifier is unstable on a small-sized training set; 2) SVM’s optimal hyper plane may be biased when the positive feedback samples are much less than the negative feedback samples, and 3) over fitting happens because the number of feature dimensions is much higher than the size of the training set. |
| Relevance feedback schemes are based on support vector machines (SVM) .In this paper [13], Training a support vector machine (SVM) requires solving a quadratic programming (QP) problem in a number of coefficients equal to the number of training examples. The standard numeric techniques for QP become infeasible for very large datasets. Practical techniques decompose the problem into manageable sub problems over part of the data or, in the limit, perform iterative pair wise [14] or component-wise [15] optimization. A disadvantage of using these techniques is that they may give an approximate solution, and may require many more passes through the dataset to reach a reasonable level of convergence. An on-line alternative, that formulates the (exact) solution for training data in terms of that for data and one new data point, which is presented in this. The incremental procedure is reversible, and decremental “unlearning” of each training sample produces an exact leave-one-out estimate of generalization performance on the training set. |
| In this paper [16], the accuracy of object category recognition is improving rapidly, particularly if the goal is to retrieve or label images where the category of interest is the primary subject of the image. However, existing techniques do not scale well to searching in large image collections. This paper identifies three requirements for such scaling, and proposes a new descriptor which satisfies them. We suggest that interesting large-scale applications must recognize novel categories. This means that a new category can be presented as a set of training images, and a classifier learned from these new images can be run efficiently against the large database. Note that kernel-based classifiers, which represent the current state of the art, do not satisfy this requirement because the (kernelized) distance between each database image and (a subset of) the novel training images must be computed. Without the novel-category requirement, the problem is trivial—the search results can be pre-computed by running the known category detector on each database image at ingestion time, and storing the results as inverted files. |
| In this paper [17] the author explored the idea of using high-level semantic concepts which is also called attributes, and to represent human actions from videos and argue that attributes enable the construction of more descriptive models for human action recognition. The author proposed a unified framework wherein manually specified attributes are: i) selected in a discriminative fashion so as to account for intra-class variability; ii) coherently integrated with data-driven attributes to make the attribute set more descriptive. Data-driven attributes are automatically inferred from the training data using an information theoretic approach. The framework is built upon a latent SVM formulation where latent variables capture the degree of importance of each attribute for each action class. They also demonstrate that the attribute-based action representation can be effectively used to design a recognition procedure for classifying novel action classes for which no training samples are available. They tested the approach on several publicly available datasets and obtain promising results that quantitatively demonstrate our theoretical claims. |
| In this paper [18], Determining the similarity of short text snippets, like search queries, which works poorly with traditional document similarity measures (e.g., cosine), since there are very few, and if any, terms in common between two short text snippets. The author address this problem by introducing a novel method for measuring the similarity between short text snippets (even those without any overlapping terms) by leveraging web search results to provide greater context for the short texts. In this paper, we done such a similarity kernel function, and mathematically analyse some of its properties, and provide examples of its efficacy. The author also shows the use of this kernel function in a large-scale system for suggesting related queries to search engine users. In analysing text, there are many situations in which we wish to determine how similar two short text snippets are. For example, there may be different ways to describe some concept or individual, such as United Nations Secretary- General" and \Ko_ Annan", and they would like to determine that there is a high degree of semantic similarity between these two text snippets. Similarly, the snippets \AI" and \Artificial Intelligence" are very similar with regard to their meaning, and even though they may not share any actual terms in common. |
INTELLIGENT SEMANTIC WEB SEARCH |
| We propose the semantic web based search engine which is also called as Intelligent Semantic Web Search Engines. Here we propose the intelligent semantic web based search engine and we use the power of xml meta-tags deployed on the web page to search the queried information. The xml page will be consisted of built-in and user defined tags. The metadata information of the pages is extracted from this xml into rdf. Practical results showing that proposed approach taking very less time to answer the queries while providing more accurate information. |
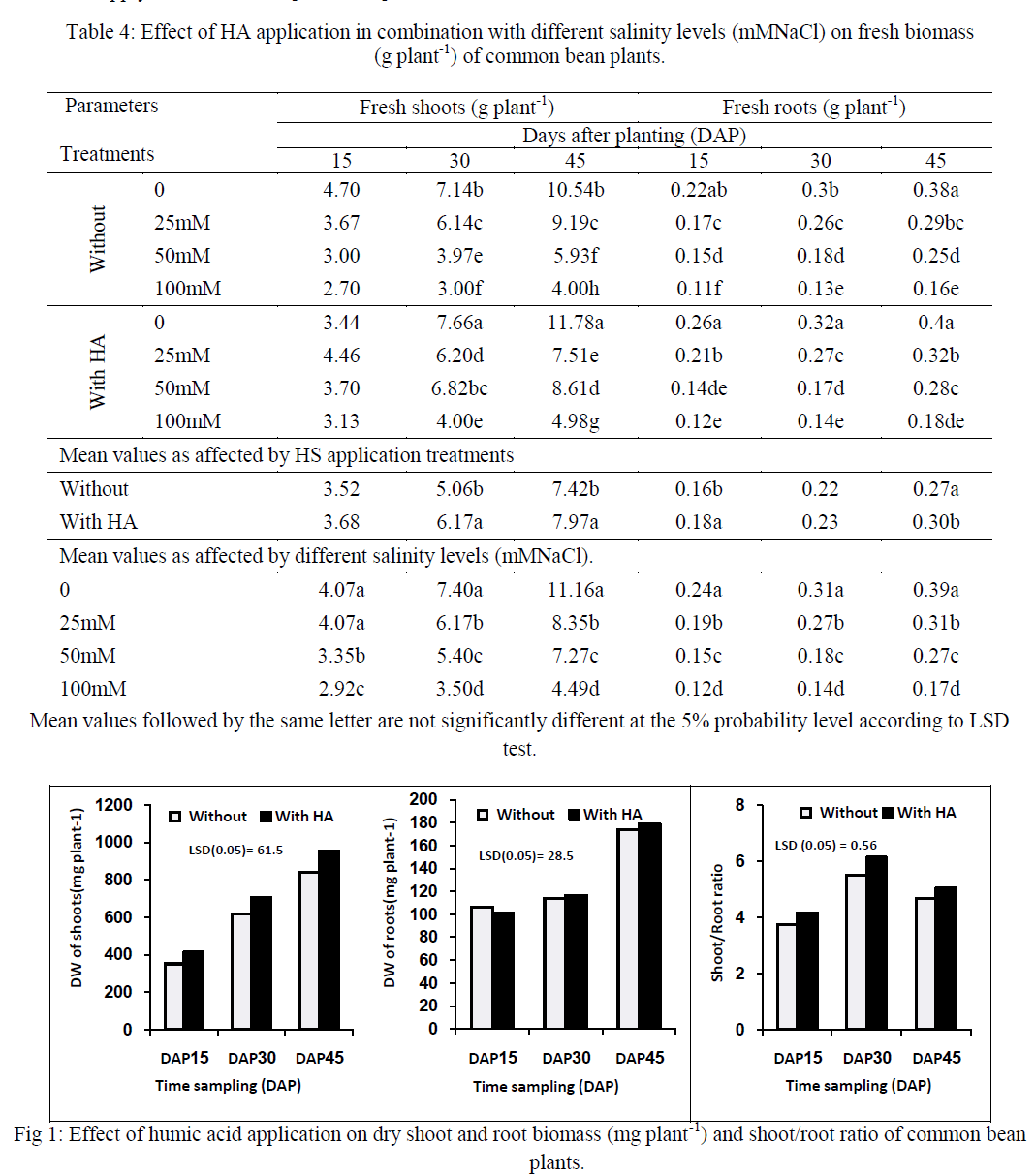 |
| “Fig. 1”, Shows the Architecture diagram. |
| In this above diagram Fig.1, when the user enters the query keyword the search engine searches the image based on the semantic signature assigned to that image while uploading. It then fetches the images from database using semantic signatures and re-ranks the image based on the one click feedback given by the user. The retrieved images are then displayed into the semantic space allocated for this. And then the images are viewed by the user. When the user clicks the particular image displayed in the semantic space the image will be displayed for download. Augmented image is displayed for each category in the same page where the image is available for download. In order to download the image the user has to login and then have to download. There are many modules in this. |
| For admin, it has authentication, upload files, signature file, and visual correlate. |
| For user, it has authentication, Search engine, view files, and information retrieval (augmented image). Visual correlate: If the admin uploads the same image more than once then it can remove the duplicate images and keep the original image alone. The duplicate images are removed by cross checking with the image size and file name |
METHODOLOGY |
| Keyword expansion |
| 1. There are 2 parts online and offline parts. |
| 2. In online stage reference classes representing different concepts related to query keywords are automatically discovered. For a query keyword, a set of most relevant keyword expansions (such as “red apple” and “apple macbook”) are automatically selected utilizing both textual and visual information. |
| 3. Set of keyword Expansions define reference classes for different keywords. |
| 4. A multi class classifier is trained on training set of reference classes. |
| 5. If there are k types of visual and textual features like colour, shape, texture we can combine them to train single classifier. |
| 6. At online stage pool of images are retrieved according to query keyword. Once user chooses query image semantic signatures are used to compute similarities of image with pre-computed semantic signatures. |
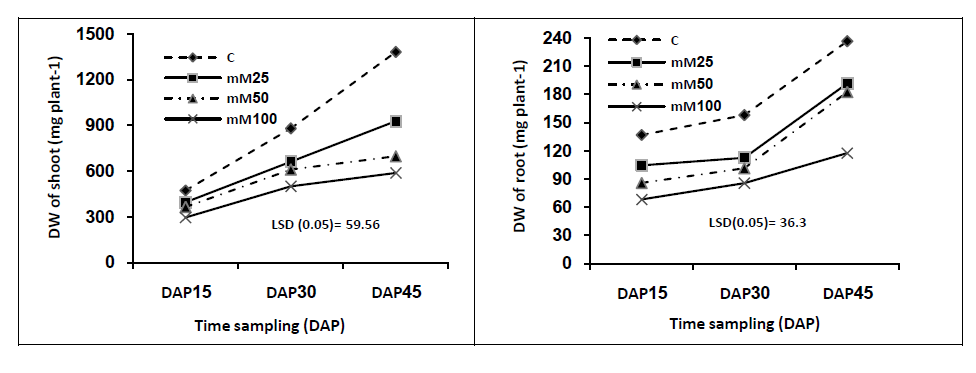 |
| “Fig. 2” Shows the Semantic Approach of Re-ranking of Images. |
| Semantic signatures |
| A user may provide query terms such as keyword, image file, image link, or click on some image, to search for images, and the system will return images "similar" to the query. The similarity used for search criteria could be Meta tags, color distribution in images, region/shape attributes, etc. Unfortunately, image retrieval systems have not kept pace with the collections they are searching. The shortcomings of these systems are due both to the image representations they use and to their methods of accessing those representations to find images. The problems of image retrieval are becoming widely recognized, and the search for solutions an increasingly active area for research and development. |
| One Click Feedback |
| Online image re-ranking which limits User’s effort to just one-click feedback, which is an effective way to improve search results and the interaction between the user and web is very simple. Major web image search engines have used this strategy. The query keyword input is given by the user; a pool of images relevant to the query keyword is fetched by the search engine according to a word-image index file which is stored. When the user clicks a particular image from the pool, the count of that image will be increased by one and the remaining images are re-ranked based on the count of each image. The highest count of image will be displayed first so that it may match with the user’s search intention. |
EXPERIMENTS AND RESULTS |
| In this paper, we have used various algorithms and methods to retrieve images from the database using semantic signatures. We have used windows 7 operating system to execute the project, Microsoft Visual Studio .Net 2010 has been used as an integrated development environment. We used ASP.NET as Front end and SQL server 2008 as back end. The language used for coding is C# and the processor to execute the project should be minimum with Pentium Dual Core 2.00GHZ and hard disk of minimum 40GB. |
| The stages involved in this project are displayed in the form of screenshots. |
| 1. Image upload by admin |
| 2. Image upload for File annotation |
| 3. User registration before search |
| 4. Search window |
| 5. Search using semantic signatures |
| 6. Search Results for Apple |
| 7. Preview of the image |
| 8. Login window to download |
| 9. Image available for download |
| 10. Image annotation displayed |
| 11. Feedback of the images |
| 12. Visual correlate |
 |
 |
CONCLUSION AND FUTURE WORK |
| A unique re-ranking framework is proposed for image search which gives one-click as feedback by user in the internet. The feedback of humans is reduced by integrating visual and textual similarities which are compared for more efficient image re-ranking. User has to do just one click on image, and then re-ranking is done based on that. Also duplication of images is detected and removed by comparing the image size and name. Specific query semantic spaces are used to get more improvised re-ranking of image. Features are projected into semantic spaces which are learned by expansion of keywords.The annotation assigned to the image is also displayed along with the download option. In the future work, we can extend this method to incorporate visual appearance coherence so that the IB (Information Bottleneck) clusters not only preserve information about search relevance but also describe the part of the visual appearance in every preview session of view. |
References |
|