International Journal of Innovative Research in Science, Engineering and Technology
ISSN ONLINE(2319-8753)PRINT(2347-6710)
ISSN ONLINE(2319-8753)PRINT(2347-6710)
Sheetala.S.C1 and U.D. Dixit2
|
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Innovative Research in Science, Engineering and Technology
In the past few years many offices maintained their documents in printed form, as this the volume of printed documents were increased they suffered from a problems like space to keep them and searching of particular document. Due to this reason and due to advances in information technology made the offices to keep their documents in image form, but even though they faced a problem of retrieving a particular document. In the area of document image processing and in the analysis and retrieval of document images, recognition of graph and its detection are basic research problems. So, many approaches came into field to retrieve documents among them we are focusing on logo approach. The most of government offices and companies represent themselves by their own and unique logo, their document with logos may allow the user to easily identify the logo and to decide to which company it belongs to, by this it gives declaration of document’s source and ownership .This paper provides techniques and methods evolved for logo detection, recognition, extraction and logo based document retrieval.
Keywords |
| Logo recognition, detection, segmentation, Document retrieval, Feature extraction, Logo extraction, Feature matching. |
INTRODUCTION |
| Logo is a small design used by an administration to identify its products, uniform, vehicles, etc. A logo is a graphic mark or emblem, which are usually used by government offices, private institutions and companies. |
| The design of logo and its features may help the users to differentiate the origin or ownership of a document. Logo may be a purely graphic or name of the organization/institutions/companies that is may be in the form of text or may be a combination of both graphic and text. Hence logos are categorized into three types: graphic logo, text logo and mixed logo as shown in Figure 1. In a document having text logo, the text in this document page and its logo are different. In this type of document the whole logo is considered as a picture which may include one or more parts. Fig. 1 shows some examples of logos from theTobacco-800 database [12]. |
 |
| Logo detection, recognition, extraction and logo based document image retrieval has many applications as listed below. |
| • For business documents. |
| • Government organizations. |
| • Thesis work of students and online books from digital libraries. |
| • Security requirements of document. |
| In this paper, we surveyed different techniques involved in logo detection, recognition, extraction and logo based document image retrieval that explains methods of logo detection, segmentation, feature extraction, and logo matching with document image database. |
| The remaining section of this paper contains as follows: In section II, we provided a flow of logo detection and logo based document retrieval. In section III, we explained briefly the techniques involved in logo detection, recognition, extraction and retrieval. In section IV, evaluation strategy is given. In section V, issues and challenges were discussed. Finally, section VI concludes this paper. |
GENERAL FRAMEWORK |
1. LOGO DETECTION |
| Fig. 2 shows flow diagram for Logo detection. It consist steps: pre-processing, feature extraction, Segmentation, and finally logo detection. The details of these procedures are presented in the following sections. |
 |
Pre-Processing |
| It includes steps like noise removal and binarization of document images. Noises present in document image (Salt and pepper noises) are reduced by employing suitable filters. |
Image Binarization |
| After reducing noise, it is necessary to binarize a document image that is in zeros and ones form, binarized image is defined as: |
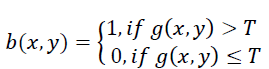 |
| Where b(x, y) is binary image, g(x, y) is the gray level of points (x, y), and T is the threshold value used for binarization. The pixel value of b(x, y) is zero for background and 1 for object. |
Feature Extraction |
| Here the meaningful information is extracted from the document images. Feature extraction reduces the storage size required to store complete document image. The features extracted from the document can be stored in the database for future use. Features helps to represent information with less space and provide better understanding of the content of that image. |
Logo Segmentation |
| The process of segmentation is to partition the feature extracted document image into smaller image using X-Y tree, top-down, hierarchical segmentation schemes, which are helpful in classifying the logo and non-logo region. This classification of logo and non-logo region is based on the features like width, height, aspect ratio and spatial density. Aspect ratio is defined as the ratio of width to height of logo. |
2. LOGO BASED DOCUMENT RETRIEVAL |
| Fig. 3 shows flow diagram for Logo based document retrieval. It consist steps: Feature extraction, logo detection, feature matching, retrieving documents. The details of these procedures are presented in the following sections. |
 |
Query Document |
| Query document is a request from end user to retrieve document from the database containing same logo. |
Feature Extraction |
| This step includes extracting the significant features from the document images. These extracted features are stored in database for future use. Feature extraction is nothing but finding out the number of connected components of black pixel. |
Logo Detection |
| This step includes segmenting the feature extracted document image into smaller images using X-Y tree, top-down, hierarchical segmentation schemes, by this we can classify the document having logo and non-logo region. The obtained documents having logo region are stored in database for future use. |
Features Matching |
| Features of logo which is stored in database in logo detection step are compared with the features of one of the document from the database, if more number of similar features are matched then that particular document are retrieved from the database. Here the logo features are matched with the features of each of the document that are indexed in database. Documents are then sorted in accordance with the result of matching method. These retrieved documents can be organized based on their ranking. |
RELATED WORK |
| Intially many literatures worked on logo recognition [1, 2, 3, 4, 5]. They worked on it by having the result of logo detection and segmentation approach. These recognition results are reported on University of Maryland (UMD) logo database [6], which includes 107 distinct gray scale logo images. |
| In 1997 Steve Seiden, Michael Dillencourt, Sandy Irani, Roland Borrey, Timothy Murphy [7], proposed “LOGO DETECTION IN DOCUMENT IMAGES”. In this paper there is a discussion about a problem that have been faced while classifying the document depending upon whether they contain logo or not, and the main goal of this paper was to determine the origin of the document. The scanned copy of documents is segmented into smaller images using X-Y tree, top-down, hierarchical segmentation schemes. There should be a limit on these numbers of segmentation so that the document can be further processed on sensible amount of time. In the next step features are extracted from each segment which is helpful in assorting the document depending on whether they contain logo or not. Feature extraction is nothing but deriving the number of connected components of black pixel. The extracted features are then compared with large dataset of logo to check out the individuality of logo. But the disadvantage of this paper is that they failed to work on text logo and on the logo having small components. |
| In 2003, T.D.Pham [8], proposed “UNCONSTRAINED LOGO DETECTION IN DOCUMENT IMAGES”. The meaning of unconstrained is that the detection of logo is not restricted to particular logo database. Threshold algorithm like Otsu’s method was used for segmenting the document image to binarize it into foreground and background pixel. A window of particular size is selected from this segmented document image which contains a logo as a part of it. An algorithm was developed for detecting logo from this window of gray scale document image. This detection was based on that the spatial density of logo region is more than the spatial density of non-logo region. But this assumption does not always hold. |
| In 2007 G.zhu and D. Doeramann [9], proposed a method for detecting and extracting a logo from document image. A method multi-stage boosting strategy is used for detecting logos and extracting it from the document image. Initially, fisher classifier was used for classifying document images into logos and non-logo region by extracting its features and its connected components. These classified regions which contain a logo are again classified by a cascade of other simple classifiers. By this it deletes false aspects from the document image and the detected logo candidate region are polished. Then the resolution of document image is reduced by selecting a defined scale; as a result the connected components of black pixels are merged, so that the logo region becomes a small gray scale box. Since this method of logo detection and extraction is based on connected components, hence it is time consuming. The main disadvantage of this method is that, when a space between logo and any other part of document image is small it will combine this logo region with the non-logo region, so that the detection of logo region becomes difficult in this case. |
| In 2009 H.wang and Y.Chen [10], proposed a method for detecting logos based on boundary extension of feature rectangle. Compared with other method it has some advantages such as it is independent of logo shape and it is fast. Here the flow of searching for black pixel goes from top- bottom and left- right. Initially irrespective of shape of logo, a black pixel is chosen which is taken as a seed pixel and its neighbour window of size 3x3 is considered as a feature rectangle. Then this rectangle goes on growing on all the four sides (top, bottom, left and right). If in any of these four sides a black pixel is observed, then it continues the process of growing, else if all the pixels in all the four sides are white pixel then it stops the process of growing the rectangle. However it fails in detecting X-Y separated logos. |
| In 2009 Guangyu Zhu and David Doermann [18], proposed a method for detecting, segmenting and matching logo from document images. Initially classifier like fisher classifier was used for classifying document image into logo and non-logo region. Then the false alarms which were present in this detected logo are deleted by using cascade of simple classifiers, and then these detected logos were stored in database for future matching purpose. The database of logos are then compared with document image by using two method like representation of shape context method proposed by S. Belongie et all[19] and neighbourhood graph matching method proposed by Y.Zheng et all[20]. By using first method the shape context of each point is calculated, which gives the classification of relative positions of all remaining points. Before matching the logos with the document image, weighted bipartite graph matching method were used to solve the correspondences between points. In second method each point is considered as vertex and if two vertices are back to back (neighbour) then they are considered as connected in the graph. Based on one to one matching method the match between shapes are equivalent to maximum number of match. |
| In 2011, Sina Hassanzadeh et al [15] proposed a novel method for detecting and recognizing logos for separated part logos in document images. To overcome the problem of detecting and recognizing logos for separated part logos in document images two methods like centroid coordinates and morphological dilation operation was introduced. It is used to combine the separated part logos in document images. In this paper it is described that logo is detected by firstly removing the noises that was present in scanned document by using median filters. This document image is then binarized and horizontal dilation operation is used for searching and expanding the shapes of structuring element of the query document image. The features like width, height, and aspect ratio of logo regions are extracted which was helpful for decision tree classifier for classifying the document image into logo and non-logo region. For logo recognition initially the boundary of binary logo image is extracted, these images are then normalized to reduce the sensitivity of the logo recognition to image size and orientation. The choice of bounding box of logo is very important step for logo recognition in which the size of this box should not be neither very small nor too large. This method of detecting and recognition of logo doesn’t work well on noisy image. |
| In 2012 A.A.Nejad and K.Faez [21] proposed “A novel method for extracting and recognizing logos”. This study is composed of three sub division. In first part pyramidal tree structure, vertical and horizontal analysis is used to identify the position of logo. Pyramidal tree structure is used to reduce the size and resolution of an image in a pyramid manner [22]. The base of pyramid is an image with high resolution and the tip of a pyramid is an image with low resolution. Vertical analysis is done from the top of the pyramid, if any level of pyramid lack horizontally then the analysis is done in the bottom level of the pyramid. The segmented region which is obtained by vertical analysis is analyzed horizontally for further segmentation in vertical direction. In second part logo is extracted by using boundary extension of feature rectangle [10]. In third part, for logo recognition the boundary of logo region is extracted, whose size and direction is then normalized, and after eliminating its skew angle, for feature extraction the bounding box of logo is then blocked. Later the important features are extracted which is then displayed in diagram for comparison. The main disadvantage of this method is that it fails to work on noisy images. |
EVALUATION PARAMETERS |
| In G.Zhu [10] it is said that the logo is detected only when the 75% pixels of the detected contains black pixels. For performance evaluation of logo based document retrieval following parameters are used: |
Accuracy |
| It is the percentage of number of correctly detected logos to the number of ground truth logos from the document image [10]. |
 |
| Where Rn is the number of pertinent match among retrieval, Rm is the total number of pertinent matches that was found in the database. |
ISSUES AND CHALLENGES |
| • The retrieval process of document is time consuming. |
| • Document degradation: Due to degradation of documents it is difficult to detect and retrieve the document using logo based approach. |
CONCLUSION |
| This paper provides the technical achievements in the field of logo recognition, detection, extraction and Logo based document retrieval. As well as efficiently and effectively we can retrieve document images using this logo based approach. |
References |
|