International Journal of Innovative Research in Science, Engineering and Technology
ISSN ONLINE(2319-8753)PRINT(2347-6710)
ISSN ONLINE(2319-8753)PRINT(2347-6710)
Radha.M 1, Theepigaa.TH 2, Rajeswari.S 3, Suganya.P 4
|
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Innovative Research in Science, Engineering and Technology
Extracting information from semi structured documents is a very difficult task, and is going to become more and more dangerous as the amount of digital information available on the Internet grows. In reality, documents are often so large that the data set returned as answer to a query may be too big to convey interpretable knowledge. In this Tree-Based Association Rules (TARs) are used mined rules, which provide approximate, intensional information on both the structure and the contents of Extensible Markup Language (XML) documents, and can be stored in XML structure as well. This mined information is later used to provide: 1) a concise idea-the gist-of both the structure and the content of the XML document and 2) quick, approximate answers to queries. A prototype system and experimental results demonstrate the effectiveness of the approach. The mined rules are used for user query processing. The updation in the mined document and the optimization of the algorithm is going to be performed
Keywords |
| Concise idea, TAR’s, Approximate answers, XML |
INTRODUCTION |
| In the real world, computer systems and databases contain data in mismatched formats. XML data is stored in simple text format. This provides a software and hardware self-determining way of storing data. This makes it much easier to make data that can be shared by different applications. In this paper the xml data has been mined using the tree based association rules. |
| In data mining, association rule learning is a popular and well researched method for discovering interesting relations between variables in huge databases. It is proposed to identify strong rules discovered in databases using different measures of interestingness. In this paper, we introduce a proposal for mining and storing Tree-Based Association Rules (TARs) as a means to represent intensional knowledge in XML. By instinct, a TAR represents intensional knowledge in the form SB => SH, where SB is the body tree and SH the head tree of the rule and SB is a subtree of SH. The rule SB => SH states that, if the tree SB appears in an XML document D, it is possible that the “wider” , tree SH also appear in D. This paper addresses the need of getting the gist of the document previous to querying it, both in terms of content and structure. Discovering frequent patterns inside XML documents provides high-quality knowledge about the do document content: frequent patterns are in fact intensional information about the data contained in the document itself, that is, they indicate the document in terms of a set of properties rather than by means of data. Approximate query answering is the first system providing fast response times for queries of large databases by avoiding or minimizing accesses to the base data at query time. Aqua provides well-accurate, estimated answers to queries using small, pre-computed synopses of the fundamental base data. For sql queries that usually take minutes to answer, Aqua can supply an estimated answer in seconds, providing immediate response to the user. |
| The path join algorithm is used for mining the trees. The trees are unordered, and the frequent sub trees are induced sub trees and maximal. Other contributions of the paper include: a compact data structure is used to compress the trees in the database, and at the same time the original tree structure is kept. Path Join, uses a new candidate sub tree generation method, which is localized to the children of a node in a tree and thus substantially reduces the number of candidate sub trees. In the previous paper they are not discussed about the updatability of both the document storing TARs and their index. In this paper the updatability of the mined TAR’s when the original xml data set change. |
II. FUNDAMENTAL CONCEPTS AND RELATED WORK |
A. Fundamental concepts |
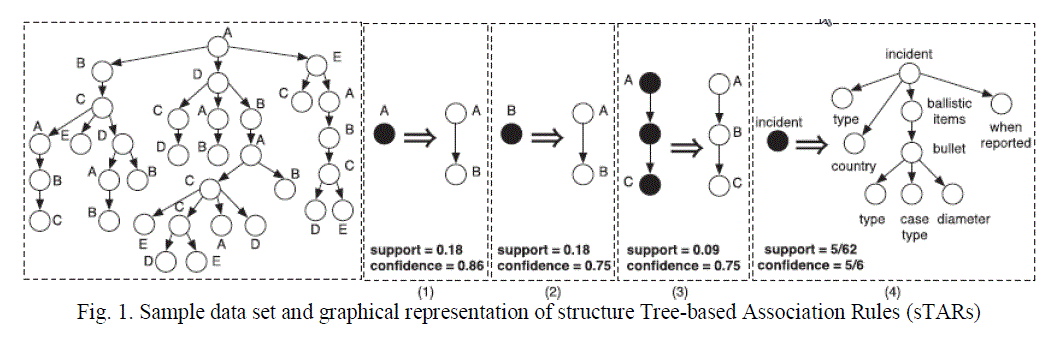
| The co-occurrence of the tree have been found using the support and confidence. The rule holds with support sup in T (the transaction data set) if sup% of transactions contain X ïÃÆÃË Y, Sup = Pr(X ïÃÆÃË Y). The rule holds in T with confidence conf if conf% of transactions that contain X also contain Y, Conf = Pr(Y | X). A Tree-based Association Rule is a tuple of the form Tr = (SB,SH, sTr, cTr) , where SB =(NB, EB, rB , lB, cB) and SH=(NH, EH, rH, lH, cH) are trees and sTr and cTr are real numbers in the interval [0,1] representing the support and confidence of the rule, in that order, (defined below). A TAR describes the simultaneous occurrence of the two trees SB and SH in an XML document. For the sake of accessibility, we shall often use the short notation SB => SH, SB is called the body or antecedent of Tr while SH is the head or subsequent of the rule. Additionally, SB is a subtree of SH with an additional property on the node labels: the set of tags of SB is contained in the set of tags of SH with the addition of the empty label “€”:lSB (NSB) ïÃÆàlSB (NSB)Ú{€}The empty label is introduced because the body of a rule may contain nodes with not mentioned tags, that is, blank nodes. |
| Given an XML document, we take out two types of TARs. |
| ïÃâ÷ A TAR is a structure TAR (sTAR) iff, for each node n contained in SH, cH(n)= +, that is, no data value is there in sTARs, i.e., they afford information only on the structure of the document (see Fig. 1). |
| ïÃâ÷ A TAR, SB => SH, is an instance TAR (iTAR) iff SH contains at least one node n such that ,cH(n) ≠ +that is, iTARs provide information both on the structure and on the data values contained in a document. |
 |
B. Related work |
| The problem of discovering association rules between items in a large database of sales transactions. Apriori and AprioriTid, are the two algorithms that differ from fundamental algorithms. Two proposed algorithms can be combined into a hybrid algorithm, called AprioriHybrid[1]. The problem of discovering all frequent tree-like patterns that have at least a minsup support in a given collection of semi-structured data. The efficient pattern mining algorithm FREQT [2] proposed for discovering all frequent tree patterns from a large collection of labeled ordered trees. FREQT is an incremental algorithm that simultaneously constructs the set of frequent patterns and their occurrences level by level. The algorithm, POTMiner, [4] is able to identify both induced and embedded sub trees and, as special cases, it can handle both completely ordered and completely unordered trees. Existing tree mining algorithms cannot be directly applied to this important kind of trees. POTMiner, to identify frequent patterns in partially-ordered trees, a particular kind of trees that is present in several problems domains. |
| One important problem in mining databases of trees is to find frequently occurring sub trees. However, because of the combinatorial explosion, the number of frequent sub trees usually grows exponentially with the size of the sub trees. They present CMTreeMiner,[3] a computationally efficient algorithm that discovers all closed and maximal frequent sub trees in a database of rooted unordered trees. Several types of traversal patterns have been proposed to analyze the browsing behavior of the user. One drawback of such one-dimensional traversal patterns for the Weblogs is that the document structure of the Web site, which is essentially hierarchical (a tree) or a graph, is not well captured. A novel algorithm, path join,[8] is proposed. The algorithm uses a compact data structure, FST-Forest, which compress the trees and still keeps the original tree structure. Path join generates candidate sub trees by joining the frequent paths in FSTForest. |
| A TreeMiner Algorithm to discover all frequent sub trees in a forest, using a new data structure called scope-list[9]. Implementation of framework for non-redundant candidate sub tree generation. It needs a systematic way of generating candidate sub trees whose frequency is to be computed. The candidate set should be non redundant. It needs efficient ways of counting the number of occurrences of each candidate in the database. Mining embedded sub trees in a collection of rooted, ordered, and labeled trees. The notion of scope is used for a node in a tree. The framework for non-redundant candidate sub tree generation. Computing the frequency of a candidate tree by joining the scope list of its sub trees. A new tree mining algorithm, DRYADEPARENT, Which is based on the hooking principle first introduced in DRYADE. The DRYADEPARENT [7] outperforms the current top algorithm, CMTreeMiner, by orders of magnitude on data sets where the frequent tree patterns have a high branching factor. The search space of tree candidates is vast, mainly when the frequent trees to find have both a high depth and a high branching factor. |
| The mined knowledge is later used to provide, a crisp idea-the gist-of both the structure and the content of the xml document and quick, approximate answers to queries. Extracting information from semi structured documents is a very difficult task, and is going to become more and more critical, as the amount of digital information existing on the Internet grows. Certainly, documents are often so large that the data set returned as answer to a query may be too big to convey interpretable knowledge. The paper describe an approach based on Tree-based Association Rules (TARs): mined rules, which provide estimated, intentional information on both the structure and the contents of extensible markup language documents, and can be stored in xml format as well. |
III. ARCHITECTURE |
| The server containing the relational database and the data collected from the web application will store in the mysql database. Each time the data entered in the application form is updated in the database. The table format data is converting into the xml document. The xml document will be stored in an xml database. An xml document is model as a tree, with nodes equivalent to elements and attributes. |
| The xml document will be analyzed by the tree based association rules. Association rules describe the co-occurrence of data items in a large amount of collected data and are represented as implications. Association rule represent patterns in the data without a specified target variable. It is intended to identify strong rules discovered in databases using different measures of interestingness. Tree based association rules will produce the mined rules from the xml document. Xml query language can extract data from existing XML documents and construct new xml documents. |
| Algorithms for discovering large item sets make multiple passes over the data. In the first pass, count the support of individual items and determine which of them are large (with minimum support). In each successive pass, we start with a seed set of item sets found to be large in the preceding pass, then use this seed set for generate new potentially huge item sets, called candidate item sets, and count the actual support for these candidate item sets during the pass over the data. At the end of the pass determine which of the candidate item sets are essentially large, and they become the seed for the next pass. |
| The path join algorithm is going to use to extract the information from the xml document. The collected information will be stored as xml data. It requires only one scan of the relevant data to evaluate path queries with not predicates. It does not generate any intermediate results. Its memory space requirement is bounded by the congest path in the input xml document. |
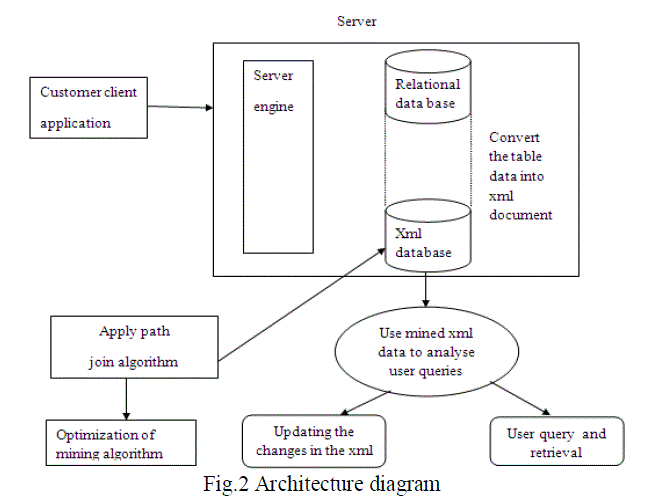 |
| The mined xml data will be analyzed for user queries. Using the keyword a user can formulate his need and retrieve related documents which need to be browsed for the relevant information. The correct information will be retrieved by the user. |
| If any changes in the original xml document the updation in the mined document is going to be processed. Using the mining algorithm the updation will be performed in the mined xml document. |
IV. MODULES METHODOLOGY |
A. CONVERSION OF TABLE DATA INTO XML DOCUMENT |
| In this the data which is available on that database tables are converted into Xml document. Which is further used to retrieve document based on the user queries. In this phase the JAXP (JAVA Architecture for XML Parser) is used. JAXP used to convert the table format data into xml data. The Java API for XML Processing (JAXP) trail provides an introduction to Java API for XML Processing JAXP. A logical xml document component which either begins with a start-tag and ends with a matching end-tag or consists only of an empty-element tag. The lettering between the startand stop-tags, if any, are the element content and may include markup, including other elements, which are called child elements. |
| the xml conversion newDocumentBuilder function is used to create the xml document. The user defined tags are created using the createElement function. The new file is created in the given path. The resultant xml document will be written the created file. Each time a new user entered in the application that will be updated in the database. The xml document also updated according to the database changes. |
B. IMPLEMENTATION OF PATH JOIN ALGORITHM |
| The main idea of path join algorithm is all maximal frequent paths are found. Then the frequent sub trees are mined by joining the frequent paths. The maximal frequent paths are special frequent sub trees. A path expression can be evaluated by join operations to avoid potentially high cost of tree traversals. It will generate candidate sub tree by joining the frequent paths. |
C. UPDATION OF XML DOCUMENT AND QUERY PROCESSING |
| The mined xml data will be analyzed for the user query processing. Using the keyword a user can formulate his need and retrieve related documents which need to be browsed for the relevant information. The query formulation can use multiple keywords to retrieve the correct information. If any changes in the original xml document the updation in the mined document will be processed. Using the mining algorithm the updation will be performed in the mined xml document. In xml the information request is done through xpath expressions. |
D. OPTIMIZATION OF MINING ALGORITHM |
| In the optimization of the algorithm the accuracy of the retrieved data will be checked. In the traditional mining algorithm the data retrieved by the user is not relevant to the user query. So that the normal user have to search on that retrieved information. The optimization will be performed using the Benson’s Algorithm . This is the method for solving linear multi objective optimization problems. This works by finding the well-organized extreme points in the outcome set. |
V. CONCLUSION |
| The mining process will directly work on the xml document, So users no need to impose what is antecedent and consequent of the rule. And the proposed system works for multiple keywords. The resultant data will be more relevant to the user query. In the second phase the path join algorithm is used to mine the xml document. The mined document is analyzed for the user queries and the correct information is retrieved by the user. And the updation in the xml document when the original document changes and the optimization of the mining algorithm will be performed. |
References |
|