International Journal of Innovative Research in Science, Engineering and Technology
ISSN ONLINE(2319-8753)PRINT(2347-6710)
ISSN ONLINE(2319-8753)PRINT(2347-6710)
| Ashok K. Panda1, Dhiren K. Sahu2, S.N.Dehuri3, M.R.Patra4 Associate Professor, Dept. of Computer Sc., MITS Engg College, Rayagada, Odisha, India1 PG Student of IT, Dept. of IT & Communication, Utkal University, Bhubaneswar, Odisha, India2 Associate Professor, Dept. of Systems Engg. Ajou University, Suwon, South Korea3 Reader, Dept. of Computer Science, Berhampur University, Berhampur, Odisha, India4 |
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Innovative Research in Science, Engineering and Technology
Document filtering is probably the most challenging task in the Web. Giving a prominent search result by filtering the document is a measure issue. Semantic similarity and large document clustering is the most difficult task as the web data has a lot of redundancy like outliers, missing values etc, data prepossessing is very much necessary. Search results produced by social search engine (web search) give more visibility to the content created. This paper focuses on semantic similarity measure, the F-measure for large document clustering. Document filtering is a task to retrieve documents relevant to user's profile. Generally, filtering systems calculate the similarity between the profile and each incoming document for retrieving documents with similarity having higher threshold value. With the increased use of the Internet and the World Wide Web, E-commerce transaction is growing rapidly. Therefore, finding useful patterns and rules of users‟ behaviours has become the critical issue for E-commerce and is used to tailor ecommerce services to meet the customers‟ need successfully. In this paper, we highlight the ArteCM clustering algorithm and implemented it which provides better results for document filtering for retrieving most relevant documents in E-commerce transaction.
Keywords |
| document filtering, e-commerce, clustering, world wide web, ArteCM clustering algorithm. |
INTRODUCTION |
| The birth of internet is really a gift to the mankind. In the recent years the growth and popularity of the internet has increased to such an extent that every person knows about it and uses it for various purposes. Some people use internet to know new things, while others use it as a means of entertainment. The use of internet is not only limited to the entertainment but it can also be used to conduct research related to work or study, get latest news etc. Now a dayâÃâ¬ÃŸs people uses internet for E-commerce. Popularity of E-commerce is so high that itâÃâ¬ÃŸs very difficult to manage web stuff. With each passing movement millions of web pages are added to this internet. The implementation of search engines on the internet made the process of searching some of the topics very easy. Querying the search engine for any particular topic would retrieve the results from the internet and those results are then presented to the users. But since there are many pages on the internet the results obtained by the search engines are also vast. It becomes really difficult for the user to get the particular page from the search engine. If it happened that the Page Rank of the particular page is high then it can be found on the first page of the search engine results, else it can be found at the end of the results. This results in the loss of time for the users as they had to spend the time looking for the particular required page. To overcome the drawbacks of the search technique, it is necessary that the search results are clustered. Clustering will help to group the similar pages together and the dissimilar pages are not grouped Presenting this grouped results to the user will help the users to get all the related pages to their query and also will reduce the time spent by them in searching the related page. Presently there are various recommendations and techniques to cluster the web pages. This paper proposes one of the clustering systems which clusters the web pages by taking in the user query. E-commerce : Electronic commerce [18], commonly known as E-commerce, is the buying and selling of product or service over electronic systems such as the Internet and other computer networks. Electronic commerce draws on such technologies as electronic funds transfer, supply chain management, Internet marketing, online transaction processing, electronic data interchange (EDI), inventory management systems, and automated data collection systems. Modern electronic commerce typically uses the World Wide Web at least at one point in the transaction's life-cycle, although it may encompass a wider range of technologies such as e-mail, mobile devices and telephones as well. |
| Web mining : Web mining is a very hot research topic which combines two of the activated research areas: Data Mining and World Wide Web. The Web mining research relates to several research communities such as Database, Information Retrieval and Artificial Intelligence. Although there exists quite some confusion about the Web mining, the most recognized approach is to categorize Web mining into three areas: Web content mining, Web structure mining, and Web usage mining. Web content mining focuses on the discovery/retrieval of the useful information from the Web contents/data/documents, while the Web structure mining emphasizes to the discovery of how to model the underlying link structures of the Web. The distinction between these two categories isn't a very clear sometimes. Web usage mining is relative independent, but not isolated, which mainly describes the techniques that discover the user's usage pattern and try to predict the user's behaviours. There are three phases in web mining [17] as given below: |
| 1. Infrastructure |
| âÃâàCrawling The Web |
| âÃâàWeb Search and Information Retrieval |
| 2. Learning |
| a. Similarity and Clustering |
| b. Supervised Learning |
| c. Semi Supervised Learning |
| 3. Application |
| Document Filtering : Document filtering is a task which monitors a flow of incoming documents, and selects those which the systems regard as relevant to the user's interest. Many document filtering systems use a similarity-based method to retrieve documents. The user's interest is expressed within the system as a profile. The similarity between the profile and each incoming document is calculated, and documents with similarities higher than a preset threshold are retrieved. Retrieved documents are sent to the user, who returns a relevance feedback to the system. This feedback information is used to update the profile for the upcoming flow of new documents. |
| Clustering : The process of forming the group of similar items is known as clustering. The process of clustering can be used in various fields such data clustering, document clustering, web clustering, etc. Given a certain data points, consider some of the data point as the centroid and calculate the distances of other points with respect to the chosen centroid. Putting the certain threshold on to the maximum distance, the data points which are within the threshold will gel with the respective centroids and the clusters are formed. The total number of clusters formed, depends upon the initial number of centroids selected for clustering. There are various types of clustering algorithms with some advantages and disadvantages. The main types of clustering algorithms are Partitional, Hierarchical and Density-based clustering algorithms. |
| Web Page : A web page [20] is a web document or other web resource that is suitable for the World Wide Web and can be accessed through a web browser and displayed on a monitor or mobile device. This information is usually in HTML or XHTML format, and may provide navigation to other web pages via hypertext links. Web pages frequently subsume other resources such as style sheets, scripts and images into their final presentation. Web pages may be retrieved from a local computer or from a remote web server. The web server may restrict access only to a private network, e.g. a corporate intranet, or it may publish pages on the World Wide Web. Web pages are requested and served from web servers using Hypertext Transfer Protocol (HTTP). Web pages may consist of files of static text and other web content stored within the web server's file system (static web pages), or may be constructed by server-side software when they are requested (dynamic web pages). Client-side scripting can make web pages more responsive to user input once on the client browser. |
| Web Content : Web content [21] is the textual, visual or aural content that is encountered as part of the user experience on websites. It may include, among other things: text, images, sounds, videos and animations. In Information Architecture for the World Wide Web, Lou Rosenfeld and Peter Morville write, "We define content broadly as 'the stuff in your Web site.' This may include documents, data, applications, e-services, images, audio and video files, personal Web pages, archived e-mail messages, and more. And we include future stuff as well as present stuff. |
| HTML head : In a web page there are two section , head and body. Body section contains the content that displays in the web page but head section doesnâÃâ¬ÃŸt have any role for the content. But there some information like title and Meta information that can be useful for the content is concern. |
| HTML Script Tag :HTML script tags are using for many client side interaction, form validation, animation and to give rich functionality to a web page |
| HTML Style Tag :HTML style tag using to add eye catching style, colour and positioning to the web page through internal as well as external style sheet |
| HTML No Script :Some of the old browser doesnâÃâ¬ÃŸt support script like java script or if JavaScript has been disabled in a web page the script tag will not work and scripts will display in the web page to avoid this no script tag are there to use |
| HTML Comment: Comment always adds additional information about a particular subject. Like wise in html also there are comments to describe the code functionality. |
| Stop Words : While calculating the frequency of the terms appearing the document, care is so taken that, the prepositions, conjunctions, adverbs, verbs are avoided. These are the terms form stop words. It is most likely that considering the stop words in the process of clustering will definitely lead us to wrong results. The reason to discard these stop words is, because of the frequency of these stop words in a document is very high. If these are not discarded, they will play role in calculating the inverse document frequency which will directly affect the cosine similarity index thereby effecting the clustering results. Stop words that are present in frequency in the documents are as exemplified below: "able,about,above,according,accordingly,across,actually,after,afterwards,again,against,ain't,all,allow,allows,almost,alon e,along,already,also,although,always,am,among,amongst,an,and,another,any,anybody,anyhow,anyone,anything,anywa y,anyways,anywhere,apart,appear,appreciate,appropriate,are,aren't,around,as,aside,ask,asking,associated,at,available,a way,awfully,be,became,because,become,becomes,becoming,been,before,beforehand,behind,being,believe,below,beside ,besides,best,better,between,beyond,both,brief,but,by,c'mon,c's,came,can,can't,cannot,cant,cause,causes,certain,certainl y,changes,clearly,co,com,come,comes,concerning,consequently,consider,considering,contain,containing,contains,corre sponding,could,couldn't,course,currently,definitely,described,despite,did,didn't,different,do,does,doesn't,doing,don't,do ne,down,downwards,during,each,edu,eg,eight,either,else,elsewhere,enough,entirely,especially,et,etc,even,ever,every,ev erybody,everyone,everything,everywhere,ex,exactly,example,except,far,few,fifth,first,five,followed,following,follows,f or,former,formerly,forth,four,from,further, etc. |
II. RELATED WORKS |
| An In Carullo et al paper [1] the ArteCM Algorithm describes the similarity measures on short documents which defines the speed & time of retrieving relevant short documents. Alexander Budanitsky and Graeme Hirst [2] focus on similarity or semantic distance in WordNet which were compared by examining their performance in a real-word spelling correction system. It determines the degree of semantic similarity, relatedness between two lexically expressed concepts. The paper by - Keiichiro Hoashi [3] proposes the use of a non-relevant information profile in order to retrieve more relevant documents without excessive retrieval of non-relevant documents. The object of this profile is to reject non-relevant documents which are similar to documents mistakenly retrieved in the past flow of documents. The paper [4] by- Chi Lang Ngo, [4] in their paper describing clustering based on rough sets , proposes a Tolerance Rough Set Clustering algorithm for web search results and implementation of the proposed solution within an open-source framework. The paper by Elizabeth D. Foused[5] shows implementation and testing of the SFC order as means for semantically representing the content of texts for the purpose of delimiting document set with a high likelihood of containing all those relevant to an individual query proving the results as promising. Nicola cancedda in his paper [6] describes the algorithm implemented by KerMIT consortium for its participation in the TREC 2001 filtering track consortium using a liner SVM with an innovative threshold section mechanism for the adaptive task using both a second order perceptron with uneven margin. Courtney Corley [7] presents a knowledge-based method for measuring the semantic similarity of texts. And introduced a method that combines word to-word similarity metrics into a text-to text metric showing the method outperforming the traditional text similarity metrics based on lexical matching. Eric Gaussier [8] proposed an online algorithm to learn category specific thresholds in a multi-class environment where a document can belong to more than one class. |
| In his paper Richard M. Paper [9] on “Advanced Decision Systems Division” is conducting a program of research to investigate machine learning techniques that can automatically construct probabilistic structures from a training set of documents with respect to a single target filtering concept, or a set of related concepts. Abbattista F in the paper [10] presents a personalization component that uses supervised machine learning to induce a classifier able to discriminate between interesting and uninteresting items making use of textual annotations usually describing the products in Ecommerce. In the paper of B. Piwowarski [11] ,the author proposes an approach to build a subspace representation for documents is a first step towards the development of a quantum-based model for Information Retrieval(IR) validating to apply into the adaptive document filtering task. Inderjit Dhillon [12] suggests techniques for feature or term selection along with a number of clustering strategies , significantly reducing the dimension of the vector space model. In his paper Oren Zamir [13] introduce a novel clustering methods that intersect the documents in a cluster to determine the set of words (or phrases) shared by all the documents in the cluster more faster than other standard techniques. Byoung-Tak Zhang [14] presented a method that acquires re-inforcement signals automatically by estimating userâÃâ¬ÃŸs implicit feedback from direct observations of browsing behaviours. The proposed learning method showed superior performance in information quality and adaptation speed to user preferences in online filtering. In the paper David A. Hull [15] systematically compare combination strategies in the context of document filtering using queries from the tipster reference corpus. Jamine Challan in the paper [16] describes a new statistical document filtering system called in -Route, for filtering effectiveness and efficiency that arise with such a system, and showed experiments with various solutions. |
III. THE PROBLEM STUDY |
| This section discusses the heuristics approach to fast, online document clustering based on domain specific similarity measures and describes the ArteCM algorithm [5]. Let D be the domain of documents d and D a given document collection, we define a normalized document similarity measure S: |
| a normalized similarity measure S between a set of documents and a single document: |
| The ArteCM Clustering Algorithm : Requirement : Choose threshold parameter ε, Choose threshold parameter η, be ÃâÃË a growing set of elements Ci from 2D. |
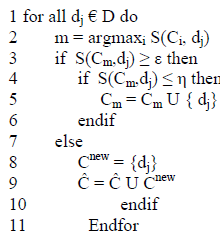 |
| A. A threshold parameter ε € [0; 1] that defines the minimum similarity S(Ci,dj) document dj must have in order to be assigned to cluster Ci.. |
| B. A threshold parameter η € [ε;1] that defines the maximum similarity Ãâ¦ÃÅ(Ci,dj) a document dj must have to contribute to the definition of cluster Ci. |
| C. The two parameters play a fundamental role in the cluster growing process; the ε parameter directly controls the granularity of the document collection partitioning; while η parameter controls the number of elements considered in similarity computations, having a strong impact on overall speed. A standard similarity measure SD - the Dice coefficient [10] with binary term weights, appropriate for our context and defined as: |
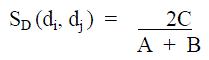 (4) (4) |
| Where C is the number of common terms between di and dj , A and B are the number of terms of di and dj , respectively. A novel similarity measure ST aimed to better fit the nature of the short documents domain where a “weighted” similarity measure can be easily applied in which common terms contribute with different weights in function of their typology (numbers, words, special chars, : : :). |
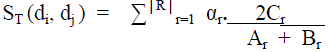 (5) (5) |
| Such that Σ r=1 âÃâÃâRâÃâÃâ α=1 and where F={f1,……..,fâÃâÃâFâÃâÃâ} is the set of term types and Cr is the number of common terms of type fr between di and dj, ÃÂÃÂr and ÃÂÃâr are the number of terms of type fr in di and dj respectively. |
| Discussions : |
| Evaluation Metrics : The evaluation phase takes into account cluster quality and speed, since we want to investigate fast clustering algorithms that can be applied on the fly on a collection of documents. In the Information Retrieval and Document Analysis field a widely accepted evaluation metric is the FMeasure (F1), as an harmonic mean between Precision and Recall [3] indexes. Given a collection of documents D = {d1;...; dN} and a list of labels L = {l1;....; lM} where M <= N we define the truth cluster set C = {C1; : : : ;CM} where Ci ={fdj : the label of document dj is li}. If a single cluster Ci and an approximation of it ^ Cj are considered, Fc is the F1 computed considering Ci as the set of relevant documents and ^ Cj as the set of retrieved documents. |
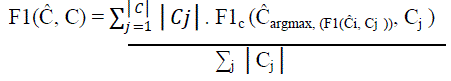 (6) (6) |
| Being ^ C a cluster set computed by an algorithm and following [4] the F1 within two cluster sets can be computed in terms of F1c: for each truth cluster the one with higher F1 is selected and then the weighted mean of F1 within all the cluster set is computed. The K-Means iterative algorithm is able to provide quite good results, even though the need to know something about the number of needed clusters can be a limit in the web domain. Computing time though linear in the document collection size, can increase unexpectedly. |
IV. IMPLEMENTATION |
| Web Document Filtering using Clustering : |
| Here the ArteCM algorithm has been implemented for web document clustering. The main objective is to get the whole content of the web site and then pre-process the content and clean it. A web page contains various unnecessary information like head, script, style, no script, comment including stop words. To get actually and useful content we need to clean the data. Get the title of the website, Meta keywords and Meta description of the web page , then we calculate the word count then assign the site to a token id , then comparing the site with another site and find the common words between them. Then calculate the dice coefficient similarity measure. Then this process will continue for all the document di that belongs to the document collection , D. The whole steps of operation as detailed below. The implementation process is carried out in the steps as follows : |
| a). Begins with fetching the content form the web site by unique web URL. |
| b). Then we pre-process and clean the content to get accurate result. |
| c). Then finding the word count of different portion of the content as unique word and whole word. |
| d). In the next step we compare the two sites finding their common word count and similarity measure. |
| e). Finally putting the dice-coefficient similarity measure in ArteCM algorithm we implement argmax operation it to create different clusters. |
| The whole process starting form fetching to similarity measure has been implemented using most popular and very fast growing server side programming language PHP and MySQL database. |
| Site Meta Data Table |
| The Table1 (Meta Table) contains the short name of the all type of word count do to lack of space we have to apply this technique to adjust the title of web pages 8 different type of word count. This data has been used bellow . |
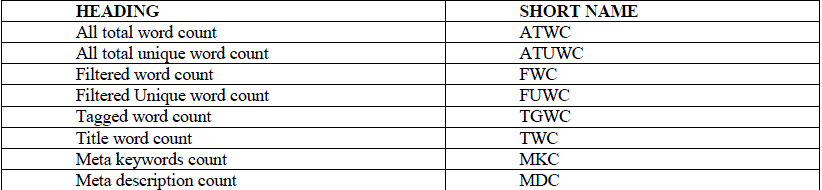 |
| TABLE I SITE META DATA |
| There are more then 100+ E-commerce site taken in consideration in the experiment. It is not possible to show all the 100+ site information. The word collection and the words of only 8 website have been displayed here for understanding. This table contains the word count of the different part of the website in 8 different base. |
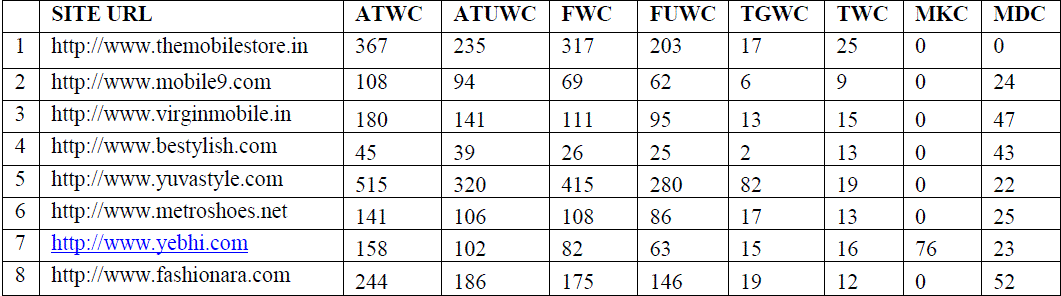 |
| TABLE 2 SITE INFORMATION |
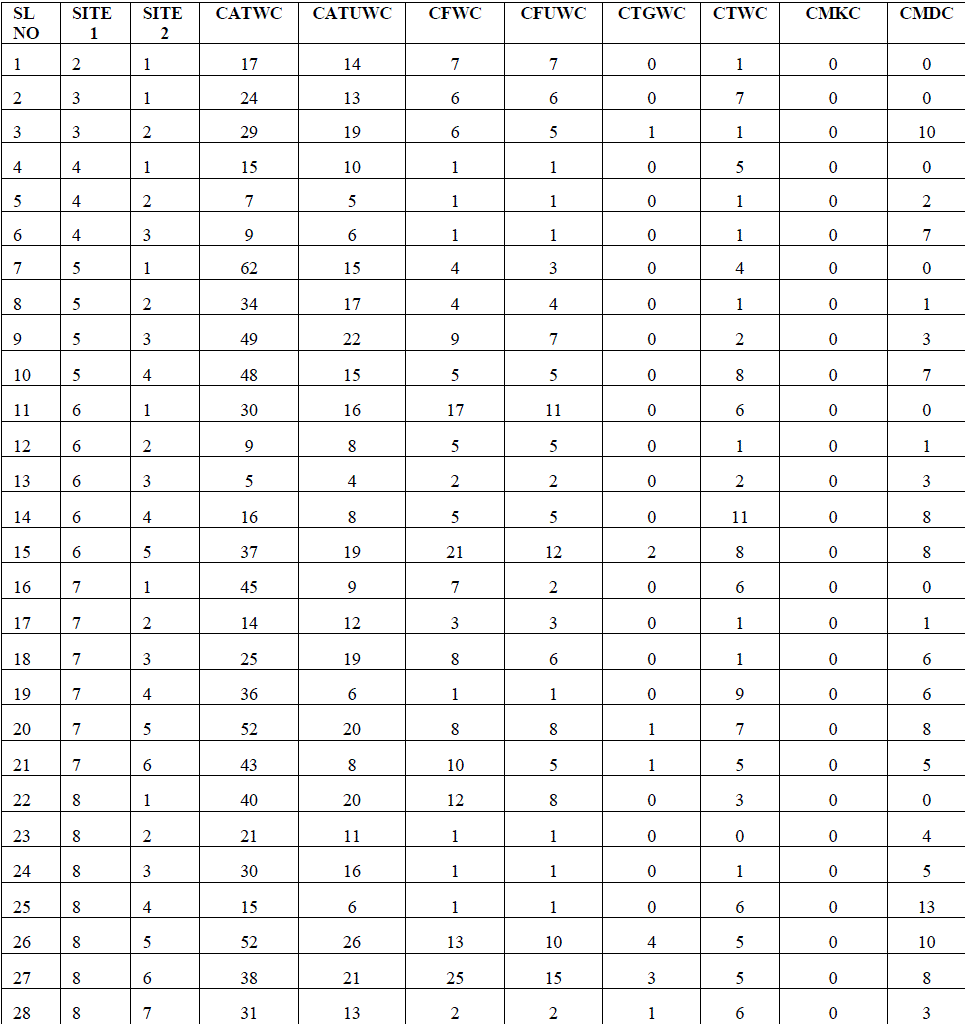
| Here in the Fig.2 contains 8 unique web page word count on 8 basis as described below : |
| All total word count (ATWC): All total word of count of a site is the total words before filtering the stop word but after cleaning the html head, script, style, no script and comment and html tag information from the fetched content. All total unique word count (ATUWC) : These are the total unique word from the all total word because there may exist some duplicate word in the total word collection. After removing the duplicate word from all the word weâÃâ¬ÃŸll get the all total unique word count (ATUWC) Filtered Word Count (FWC): There might be some stop word like a, an, the some, etc... in the word collection so after filtering the stop words from the total word collection we are getting the filtered word count. Filtered Unique word count : After getting the filtered word there might be some duplicated by removing the duplicate words we can get the filtered unique words count. Tagged Word Count : Tagged word is really very interesting collection of words. Those words having high frequencies in the total word that„ll be included in the tagged word count. These are collected from the filtered word. Title Word Count : Every web page has <title></title> tag. This tag contains the title information of the web page. The total word count of the title is the title word count. Meta Keywords Count : In the Head section of web page there is Meta keywords information that helps for identify the web page while searching in search engine. Total Meta keywords are the Meta keyword count. Meta Description count : Meta Description is the short description of the web page that present in side the head section of the web page. The total word present in the description of the Meta is the Meta description count. |
 |
| Fig. 2.Site Information Chart |
| Site word count inofrmation : |
| In the experiment we have taken more then 100 E-commerce website but it is not possible to give all the web site word count and similarity measure information. Here we present 8 unique URL and their word count on the basis of different criteria as given bellow. |
| Similarity Measure Meta Data Table |
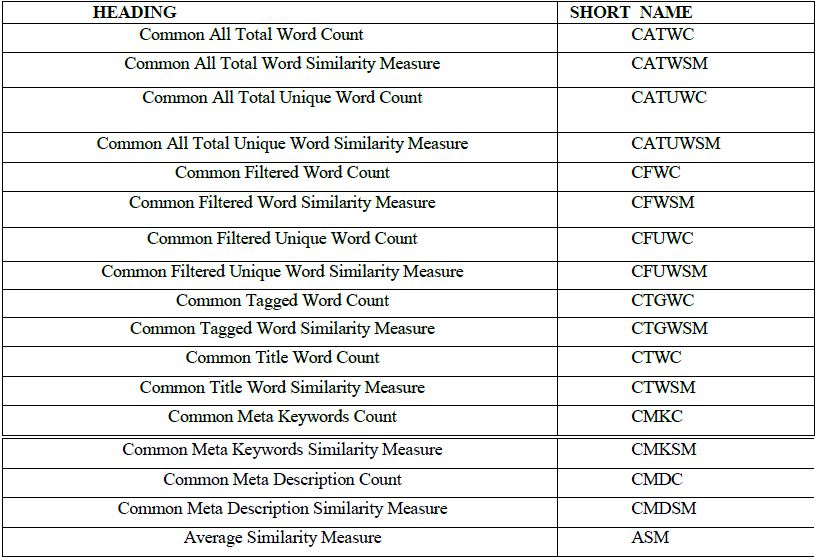 |
| TABLE 3 SIMILARITY MEASURE META DATA |
| In the Table.3 it contains the Meta data for the finding the common word count and similarity measure between sites. As the labels are very large, a short labelled Meta data table has been created. After getting the site information the site is assigned by a token id to identify uniquely. Then by comparing two site we„ll get some common word. After getting the common word we can find the Dice Coefficient Similarity Measure by using the formula, equation-(4) , in SD , where C is the number of common terms between di and dj , A and B are the number of terms of di and dj , respectively. Here we are finding the similarity measure of CATWSM, CATUWSM, CFWSM, CFUWSM, CTGWSM, CTWSM, CMKSM, CMDSM, then get the Average Similarity Measure( ASM ) . |
| Site Comparison Common Word Table |
 |
| TABLE 4 SITE COMPARISION COMMON WORD |
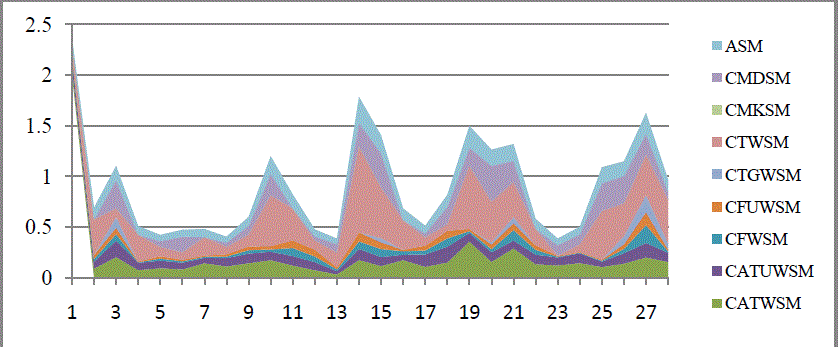
| Fig.3 and Fig.4 describes the Table.4 and Table.5 information respectively. In Table.4 it shows the common word count of all the 8 sites. There 28 records present each record have 8 attribute. Fig.3 showing the graph representation of the Table.4 which clearly understandable. Similarly Table.5 contains the similarity measure graph contains the similarity measure by comparing two sites. |
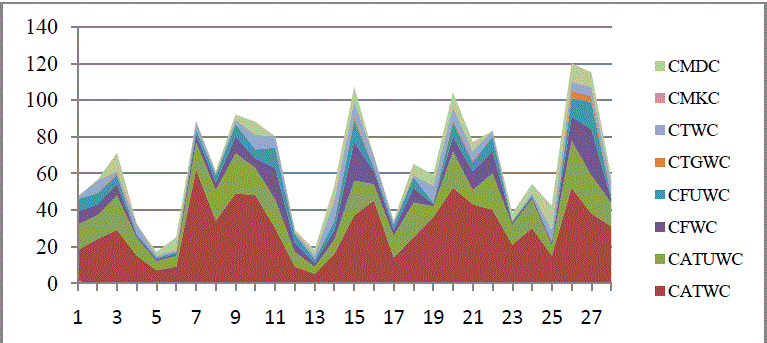 |
| Fig. 3 . Site Comparison Common Word |
 |
| Fig. 4.Site Comparison Similarity Measure |
| Fig.4 show graph for Table.5 contains the graph for similarity measure of all the comparisons between all the 8 site..Finally it calculates the average similarity form the all 8 base in Table.5. in Table 5 the similarity measure has been calculated by taking the common word count from the Table.4. |
| Site Comparison Similarity Measure : |
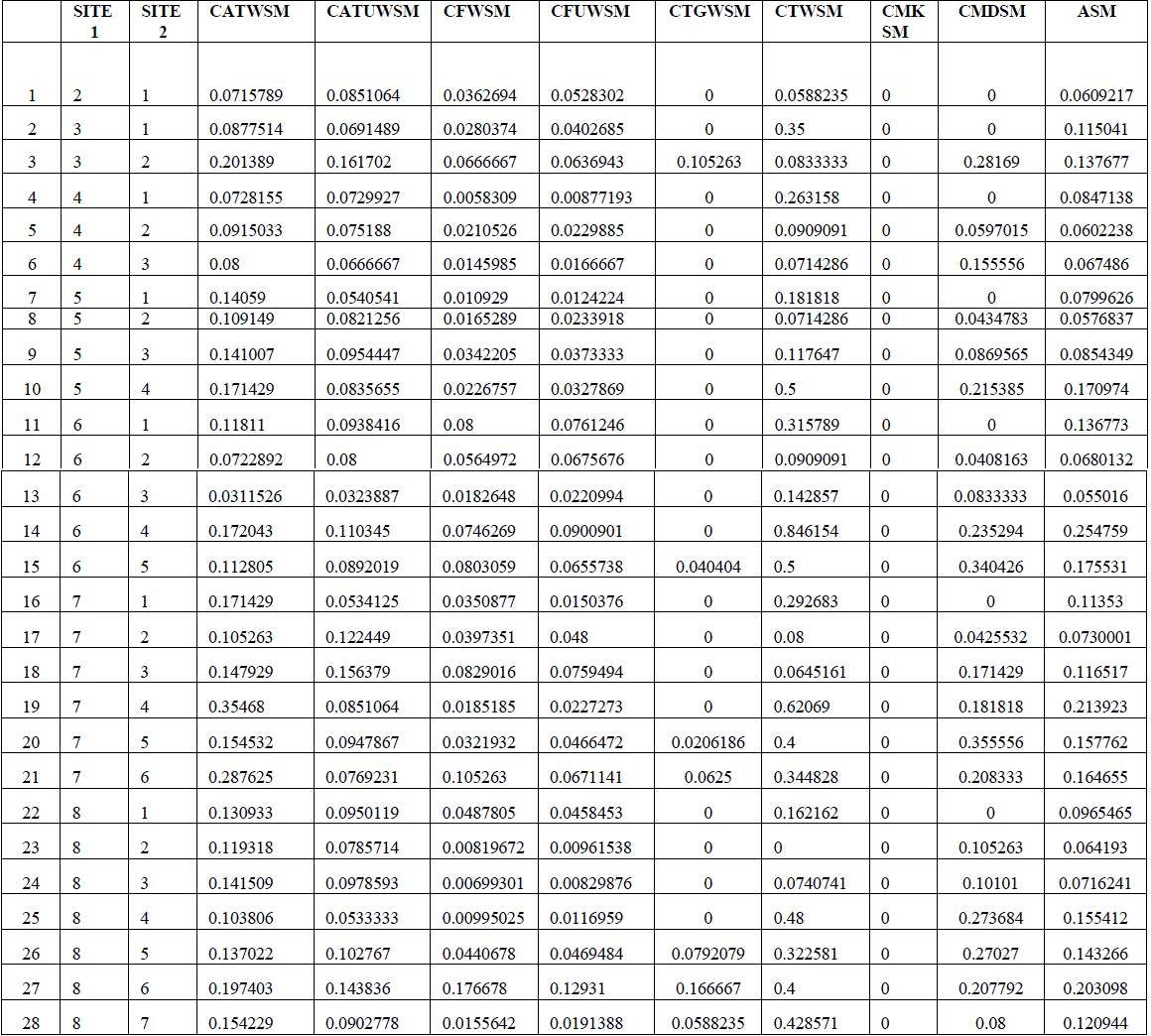 |
| TABLE 5 SITE COMPARISION SIMILARITY MEASURE |
| Steps for Document Clustering Implementation |
| There are various steps as given bellow that helps to create the document cluster : |
| 1. Data Acquisition |
| Fetch Whole Content of The Web Page |
| Fetch Title Of The Web Page |
| Fetch Meta Keywords Of The Web Page |
| Fetch Meta Description Of The Web Page |
| 2. Data Cleaning |
| Remove The Java Script Information From Page Content |
| Remove The Style sheet Information From Page Content |
| Remove The No Script Information From Page Content |
| Remove The Head Information From Page Content |
| Strip Multi-Line Comments Including C data from Page Content |
| Remove The Html Tags From Page Content |
| Remove The Stop Words From Page Content |
| 3. Data Processing |
| Get All Words Of The Web Page |
| Get All Unique Words Of The Web Page |
| Get Filtered Words Of The Web Page |
| Get Filtered Unique Words Of The Web Page |
| Get Tagged Words Of The Web Page |
| Get Title Words Of The Web Page |
| Get Meta Keywords Of The Web Page |
| Get Meta Description Words Of The Web Page |
| 4. Find Word Count |
| Get All Words Count Of The Web Page |
| Get All Unique Words Count Of The Web Page |
| Get Filtered Words Count Of The Web Page |
| Get Unique Filtered Words Count Of The Web Page |
| Get Tagged Words Count Of The Web Page |
| Get Title Words Count Of The Web Page |
| Get Meta Keywords Words Count Of The Web Page |
| Get Meta Description Words Count Of The Web Page |
| Create A Token Assign The Web Page To A Token |
| 5. Finding The Dice Coefficient Similarity Measure |
| Get All Words Similarity Measure Of The Web Page |
| Get All Unique Words Similarity Measure Of The Web Page |
| Get Filtered Words Similarity Measure Of The Web Page |
| Get Unique Filtered Words Similarity Measure of The Web Page |
| Get Title Words Similarity Measure of The Web Page |
| Get Meta Keywords Words Similarity Measure of The Web Page |
| Get Meta Description Words Similarity Measure of The Web Page |
| Get Average Similarity Measure of The Web Page |
| 6. Finding F1 Measure |
| In statistics, the F1 score (also F-score or F-measure) is a measure [22] of a test's accuracy. It considers both the precision p and the recall r of the test to compute the score: p is the number of correct results divided by the number of all returned results and r is the number of correct results divided by the number of results that should have been returned. The F1 score can be interpreted as a weighted average of the precision and recall, where an F1 score reaches its best value at 1 and worst score at 0. |
| Implementing ArteCM Algorithm: |
| In section 3 , The problem study of ArteCM algorithm is described and implementing on it , from the similarity measure information , we get the cluster of documents using the F1 measure score in order to get the proper document cluster. The Document Cluster that is found is presented in the Table. 6. Through the Fig.5 we found the final document cluster. There are three clusters we got after the whole process. The 8 unique web page has been clustered into three cluster ladled as “online Mobile Store”, “Online Fashion Store” and Online “Footwear Store”. In the first cluster there are 3 pages and 2nd cluster contains 4 pages while in the 3rd cluster we got only 1 page. |
 |
| TABLE 6 FINAL DOCUMENT CLUSTER FORMED |
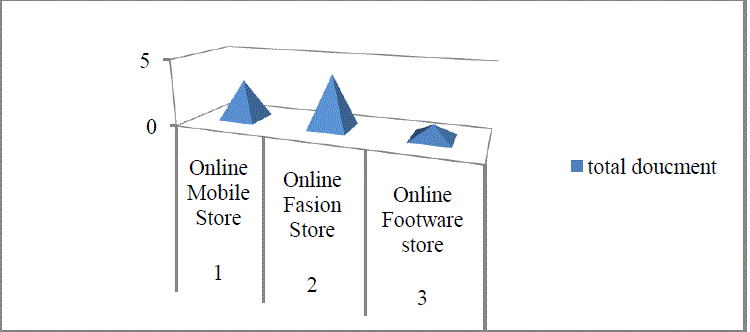 |
| Fig. 5 .Final Cluster formed |
V. CONCLUSION AND FUTURE DIRECTION |
| In this paper we proved how the clustering method is very useful and effective. By adding some more levels in data cleaning we get more pure and the most relevant data, which ultimately helps to find better results. Taking title, Meta keyword and Meta description into account, it is more convenient in checking the similarity and relative document. Creating the tagged word is another advantage of this clustering method. Taking unique word is also a better measure. Web document is very complex and large. The clustering method hence create clusters from large and complex web documents as depicted in this paper. More than 100 E-commerce sites have been taken in implementing the algorithm for this experiment. It shows a good result with less time. There is a number of future scope on this work. Researchers are encouraged to introduce some new similarity measure(s) for broader (large) document clustering. Computational applications typically require relatedness rather than just similarity. As the web document is very complex, it needs to be more clean and pure so that in future, addition of some new data cleaning techniques will provide more accurate and valued results |