INTRODUCTION
|
| WIRELESS sensor networks (WSNs) can be readily deployed in various environments to collect information in an autonomous manner, and thus can support abundant applications such as habitat monitoring [1], moving target tracking [2], and fire detection [3]. WSNs are generally event-based systems, and consist of one or more sinks which is responsible for gathering specific data by sending queries. Usually, sensor nodes are densely deployed and responsible for detecting interesting events and sending related data to sinks. The collaborative signal processing algorithms can be designed in WSN applications to improve the sensing performance. A data fusion technique, which can merge raw data from multiple sources to achieve improved accuracies and more specific infer- ences than could be achieved by use of a single sensor alone [4], has been employed in sensor network systems for target detection [5], [6], localization [7], and classification [8]. Generally, data fusion involves hierarchical transformation between sensory raw data and decision, which constitutes statistical and sequential estimations, or weighted decision problems [4]. Thus, data fusion often requires intensive computing, which may be unaffordable for the nodes in WSN with the limited resources including computing, storage and especially energy, which is usually difficult to be supplemented due to unattended operation in remote or even hostile locations. Hence, it is a key research issue to design energy efficient protocol for WSNs. Most phenomena or events are spatially and temporally correlated, which imply data from adjacent sensors are often redundant and highly correlated. To exploit both spatial and temporal correlations, the data aggregation, which can be regarded as simple data fusion, is introduced by Heidemann et al. [9] to conduct some simple operation on raw data at intermediate nodes, such as MAX, MIN, AVG, SUM, etc., and then only the abstracted data are transmitted to the sink, and thus save energy consumption by avoiding redundant transmissions. Following this para- digm, numerous data aggregation schemes [10], [11], [12], [13], [14], [15], [16], [17], [18], [19], [20], [21], [22], [23], [24], [25], [26] have been proposed to save the limited energy on sensor nodes in WSNs. |
| In WSN community, most investigations on data aggregation schemes focus on designing proper strategies to drive the packets carrying redundant and correlated data converge spatially and temporally, which will provide more chances and more sufficient conditions for actual aggregation operations. Accordingly, the data aggregation schemes can be broadly classified into two categories, i.e., temporal and spatial solutions, respectively. The work in [10], [11], [12], [13], [14], [15], [16], [17], [18], [19] belongs to the former and the investigation in [20], [21], [22], [23] refers to the latter. Otherwise, data aggregation is ordinarily accomplished in data gathering paradigm where the sink usually transmits a query message to sensor nodes (e.g., via flooding) and the sensor nodes, which have data matching the query, send response messages back to the sink. Obviously, the under- lying data collection routing protocol is crucial to drive packets converge spatially. Hence, most of the existing work [10], [11], [12], [13], [14], [15], [16], [17], [18], [19] mainly focus on the development of an efficient routing mechanism for data aggregation. Although the existing data aggregation schemes can effectively make packets more spatially and temporally convergent to improve aggregation efficiency, most of them assume that there are homogeneous sensors and only one application in WSNs, and ignore considering whether the packets really carry redundant and correlated information or not. Actually, nodes are equipped with various sensors (i.e., pressure, temperature, humidity, light intensity, etc.) and different applications can also run in the same WSN simultaneously. It is impossible to conduct simple aggregation operations on the packets from heterogenous sensors even if all packets can be transmitted along the same pre constructed aggregation trees and timing control schemes can also ensure packets have a high probability to meet with each other. Even data fusion can merge multiple heterogenous raw data to produce new data, which is expected to be more informative and synthetic than input raw data, it is meaningless to make data fusion on raw data from different applications. |
| In this work, we introduce the concept of packet attribute, which is used to identify the packets from different applications or heterogenous sensors according to specific requirements, then design an attribute-aware data aggregtion (ADA) scheme, which can make the packets with the same attribute convergent as much as possible to improve the efficiency of data aggregation. The routing protocols employed by most of existing data aggregation schemes are static. They properly support data aggregation in the network with homogeneous sensors and a single application, but cannot conduct effective data aggregation when the data from heterogenous sensors or various applications are forwarded along the same static path. Events always occur randomly in time and space, the information of packet attribute at each node is hardly predicted. It is costly to predetermine the proper routing path for each packet attribute. Therefore, a distributed and dynamic routing protocol is expected to adapt to the frequent variation of packet attribute distribution at each node. |
| Enlightened by the concept of pheromone, which will be left along the path where ants pass and evaporate with time, in ant colony [27], we draw an analogy between pheromone and packet attribute. A packet will leave attribute-dependent pheromone when passing a node to attract the afterward packets with the same attribute, which will make the packets generated by the same applications more spatially convergent. With respect to routing decisions, we borrow the concept of potential in physics and follow the potential-based routing paradigm in the context of traditional networks [28] to develop a dynamic routing algorithm. The packets are driven by a hybrid virtual potential field to move toward the sink, at the same time the packets with identical attribute are attracted by attribute-dependent pheromone to move along the same path, which will provide more chances to conduct data aggregation effectively. In addition, the potential-based routing is scalable and easy to be implemented since only local information are required and can be easily obtained. To further improve the performance of data aggregation scheme, the packets should also be temporally convergent so as to meet with each other at the same node as well as at the same time. Thus, we also design an adaptive packet- driven timing control algorithm to improve temporal convergence. In summary, the main contributions in this work are threefold: |
| • An ADA scheme is proposed to intentionally drive the packets with the same attribute convergent as much as possible in the WSNs with heterogenous sensors or various applications. |
| • Inspired by the concepts of both potential field in physics and pheromone in ant colony, a dynamic routing protocol is elaborately designed to support the ADA scheme. |
| • An adaptive packet-driven timing control algorithm is proposed to provide more chances for data aggregation on nodes. |
| The remainder of the paper is organized as follows: Related work and motivation are introduced in next section. In Section 3, the details of ADA, including the potential- based dynamic routing (PBDR) and the packet-driven timing scheme, are presented. In Section 4.2, the simulations are conducted to evaluate the performance of our ADA mechanism. Finally, the paper is concluded in Section 5. |
RELATED WORK AND MOTIVATION
|
Related Work
|
| As aforementioned, data aggregation can be broadly classified into temporal and spatial solutions. The former makes packets more temporally convergent and the latter makes packets more spatially convergent. Next, the related work in these two aspects will be introduced. |
| As for timing control scheme, TAG [20] proposes a simple SQL-like declarative language for expressing aggre- gation queries over streaming sensor data and identifies the key properties of aggregation functions which affect whether data aggregations can be efficiently processed at some extent. The semantics of the query language partition time into epochs. Nodes transmit packets along a tree rooted at the sink in the corresponding epoch, which is decided by the depth of node; thus, each parent will receive packets from its children in the same epoch. Cascading timeout (CT) [21] is also based on a rooting tree in which nodes need wait some time determined by the depth of nodes before transmitting packets. In these two schemes, the transmission scheduling at a node is fixed once the aggregation tree is constructed, and is hardly adjusted dynamically according to the state of both load and network. Afterward, there are some aggregation schemes with dynamic timing control. Hu et al. [22] proposed a simple centralized feedback timing control algorithm for tree-based aggregation. The sink determines the maximal interval for one data aggregation operation with the knowledge of the information quality in the previous operation. Fan et al. proposed a random waiting timing scheme in which each node aggregates and forwards incoming packets after waiting a randomized interval[19]. A distributed scheme employing a semi-Markov decision process model is developed in [23], and the decisions are made at available transmission epochs combining with the current state of nodes, such as the number of collected samples, and the elapsed time at a node. |
| The second category focuses on designing a proper routing protocol for data aggregation. The sensor nodes are organized into clusters, a chain or a tree. In cluster-based solutions, each cluster has a designated sensor node as the cluster head, which aggregates data from all sensors in the cluster and directly transmits concise digest to the sink. LEACH [10] and HEED [12] are two typical examples. The difference between them is the method of selecting cluster heads. LEACH assumes that all nodes have the same amount of energy capacity in each election round, while HEED aims to form efficient clusters to maximize network lifetime. All cluster-based data aggregation schemes assume that each node in networks can reach the sink directly in one hop, which limits its scalability. In [29], Liu et al. proposed a poller/pollee-based architecture with the objective of minimizing the number of overall pollers while bounding the false alarm rate for the applications capable of monitoring the sensor statuses such as liveness, node density, and residue energy. Wang et al. proposed a distributed multicluster coding protocol [30] to partition the entire network into a set of coding clusters such that the global coding gain is maximized. In cluster-based routing protocols, if the cluster head is far away from nodes, they might expend excessive energy in transmissions. Therefore, the chain-based scheme is introduced to further improve energy efficiency. |
| The key idea behind the chain-based data aggregation is that each sensor only transmits data to its closest neighbor. The chain can be constructed by employing a greedy algorithm or determined by the sink in a centralized mode. All nodes are assumed to have the global knowledge of the whole network when the greedy chain is formed. PEGASIS [11] is a typical chain-based data aggregation protocol, and employs the greedy algorithm to construct the chain. In PEGASIS, the transmission distances among nodes are much shorter than those in LEACH [10]. Hence, PEGASIS can save more energy than LEACH does. However, the global information required by chain-based routing proto- cols results in the relatively high overhead especially for the large-scale network. Based on both LEACH and PEGASIS, a hybrid scheme HIT is proposed in [31], which organizes sensor nodes into clusters, but the multihop indirect transmissions between cluster head and nonhead nodes are allowed. |
| In tree-based routing protocols, data aggregation is performed at intermediate nodes along the tree and a concise representation of data is transmitted to the root node, i.e., sink. One of main tasks for tree-based scheme is to construct an energy efficient data aggregation tree. For example, Steiner minimum tree has been used in design- ing data aggregation protocols in [16]. Since the tree constructed in advance is static, most tree-based schemes can only be suitable for applications in which source nodes are known. Energy-aware distributed heuristic (EADAT) [13] and power-efficient data gathering and aggregation protocol (PEDAP) [14] are two typical examples of tree- based data aggregation schemes. The main advantage of EADAT is that the node with higher residual energy has the higher probability to become nonleaf tree node, and thus the network lifetime can be extended in terms of the number of alive nodes. PEDAP computes a minimum spanning tree using transmission overhead as the link cost, and thus minimizes the total energy consumption in each communication round. However, it is costly to reconstruct the spanning tree for each communication round. In [18], a set of routes is preconstructed and one of them keeps active in round-robin fashion, which can save energy by avoiding reconstructing route and balance energy con- sumption. However, each node needs to maintain the predetermined path to guarantee successful transmissions. When the network topology changes due to energy exhaustion on some nodes, the route needs to be reconstructed and the topology information maintained by each node needs to be updated, which will introduce considerable overhead. In [32], Park et al. combined the shortest path tree with the cluster method and developed a hybrid routing protocol to support data aggregation. A head node in each minimum dominating set performs data aggregation and all head nodes are connected by con- structing a global shortest path tree. |
| Most of existing routing protocols employed by data aggregation schemes are static. They are unsuitable for applications tracking amorphous event, such as mobile target, and so on. Identifying this limitations, Zhang et al. proposed a dynamic convoy tree-based collaboration (DCTC) to reduce the overhead of tree reconstruction in eventbased applications, such as detecting and tracking a mobile target [17]. DCTC assumes that each node knows the distance to events and the node near the center of events acts as the root to construct and maintain the aggregation tree dynamically. How to obtain the information of event location and distance is still an open issue, which also restricts the applicability of DCTC. In addition, most existing data aggregation scheme can properly work in homogeneous environment, i.e., identical sensor data or a single application, but rarely considers the impact of heterogeneity, including heterogenous sensors or different applications in the same WSN. |
Motivation
|
| Assume there are two different applications in a WSN, the data generated by different applications are heterogenous, and cannot be aggregated. Fig. 1 illustrates a small part of the whole network. The solid circles and empty circles denote the source nodes of applications App1 and App2, respectively. The empty circles with plus signs are inter- mediate nodes. |
| Fig. 1a illustrates a typical tree-based routing protocol,which consists of the shortest path tree rooted at the sink with metric such as hop count. Regardless of event locations. |
| and data type, the packets from different applications will move along the predetermined aggregation tree. Objec- tively, this static tree can converge packets in space, which provides chances for nodes to perform aggregation opera- tion. However, the efficiency of data aggregation depends on the degree of matching between the tree structure and the distribution of source nodes. For example, although node B forwards the packets from both App1 and App2, it nearly does nothing for data aggregation because the mismatch between tree structure and source distribution results in few redundant packets passing through node B. On the other hand, node A or node C can aggregate the redundant packets from App2 or App1, respectively, but provide little contribution for App1 or App2, respectively. The static and predetermined routing protocol hardly adapts to dynamic and heterogenous environment, and irregular events. If the dynamic routing would be con- structed according to the network state and the data features as shown in Fig. 1b, for example, node 1 sends packets to node 3 instead of node 2, the packets from App1 could gathered together as much as possible, and thus the aggregation efficiency would be improved drastically. Comparing with the static routing in Fig. 1a, the dynamic routing in Fig. 1b intentionally drive the packets from the same application converge spatially during their transmision procedure, but the static routing can only utilize the spatial correlation in the predetermined forwarding paths. In addition, the limited buffer resources on nodes can be reserved to cache more packets from the same application, and then conduct more effective aggregation at the proper time. Otherwise, the intermediate nodes with little contribution on data aggregation can be excluded in the forwarding path to avoid energy consumption caused by pure forwarding operations, just like node B in Fig. 1a. |
| Obviously, the dynamic routing protocol is the corner stone of ADA suitable for heterogenous data or various application in the same WSN fig(2). The concept of pheromone in ant colony [27] inspire us to design the dynamic routing algorithm for our ADA scheme. In nature, ants leave pheromone, which can emanate an odor and evaporate with time, along the paths that they have passed. The afterward ants will select their paths according to the amount of pheromone on different paths. If the packets in WSNs are treated as the ants in nature by analogy, and then the attribute-dependant pheromone is left on the nodes through which packets with different attribute pass. Subsequently, the node with different pheromone will emanate different odor. The more is the pheromone, the more intense is the odor. The packets just follow the odor to meet with other packets with the same attribute. In this way, the packets can be gathered together by intentional forwarding, which will assist in achieving the goal of our ADA schemefig(2). Applying the principle that ants select the paths to find food based on pheromone, the routing protocols are designed for wired network [33] and wireless ad hoc network [34], respectively. However, to search the proper path between a pair of nodes, the ant routing protocol needs to inject extra packets (i.e., forward “ants” and backward “ants”) into networks to update routing tables and distribute state information of network; moreover, the convergence of routing depends on the number of “ants.” The excessive over head is unaffordable for WSNs with limited energy. Therefore, in this work, we only use the concept of pheromone in ant colony to identify data attribute from different applications or hetergenous sensors, and borrow another concept in physics (i.e., potential field) to construct the dynamic routing for the ADA scheme. In [28] and [35], the steepest gradient search method is used to design a potential-based routing paradigm in the context of traditional networks and mobile ad hoc network, respectively. However, it is expensive to build an exclusive virtual field for each destination in traditional networks where numerous destinations distribute arbitrarily. The huge management overhead degrades their practicality. On the contrary, the potential-based routing algorithm is much proper for the centralized traffic pattern in WSNs with a single (at most several) sink(s), namely destinations. |
| Motivated by the above understanding and enlightened by the two concepts in other discipline, we construct two independent virtual potential fields. One potential field is built using the parameter related to network topology to guarantee packets reaching the sink at last, and the other potential field is constructed using the pheromone left by packets to purposely attract the packets with the same attribute, and then these independent virtual potential fields are combined together to form a hybrid potential field acting on the routing decisions. Since the information for making dynamic routing decisions can be easily gotten by each node, our PBDR scheme not only makes the packets with the same attribute more spatially convergent but also is simple and scalable. In addition, to make packets more temporally convergent, a packet-driven adaptive timing control scheme is proposed to cooperate with the basic dynamic routing, namely our completed ADA scheme includes a PBDR and a packet-driven timing control algorithm. Next, we will introduce their details. |
DESIGNING ADA
|
| In this section, the PBDR protocol will be presented, followed with some analysis of key parameters, then a packet-driven timing scheme which cooperates with the dynamic routing will be developed. For a legible descrip- tion, we first introduce some definitions |
Definition
|
| Depth: The depth of a node is the number of hops that it is away from the sink. |
| Neighbor: The neighbor of node i is all nodes in the radio coverage disk of node i except for i itself, denoted by Ω(i). |
| Attribute: The attribute of data packet is its identification. The heterogenous sensors and nodes involved in different applications may generate data packets with different attributes. The identical sensors on the nodes involved in the same applications will generate the packets with identical attribute. We use different natural numbers to identify different attributes, and extend the packet header to carry this value. |
| PBDR |
| Before starting to describe the concrete routing algorithm, we first show how it works. Intuitively, the depth potential field in the PBDR can be viewed as a bowl. The sink resides at the bottom, and all packets in most of existing tree-based data aggregation schemes flow down along the surface directly just like water does without interacting with each other. However, the packets with correlated information should be gathered together for more efficient data aggregation. To realize this goal, the pheromone potential field is constructed. Packets with different attribute leave different odor at every node that it passed, and the odor will volatilize with the time. Each packet is transmitted to the neighbor in response to the amount of the same odor as that of itself, so that the packets with the same attribute can attract each other and gather together in space. Intuitively, the pheromone potential field forms the valleys in the surface of the bowl. The more intense is the odor, the deeper is the valley. Each packet is transmitted to the deepest valley with the same odor as that of itself, rather than be sent along a fixed path such as the shortest tree. In this way, the packets with the same attribute can intentionally follow the same path and converge as much as possible. |
Potential Field Model
|
| In the bowl model, we can view the whole network as a gravitational field. A packet can be viewed as a drop of water, moving down to the bottom along the bowl surface .The trajectory is determined by the force from the gravitational potential field. A single-valued potential, V (u), is assigned to node u on the bowl surface to form a scalar potential field. Now, consider a packet p at node u, to reach the sink, it will be forwarded to one of the neighbors of u. Let Ω(u) be the neighbor set of node u. To determine the next hop of packet p, following the concept of force given in [28], we define the force acting on packet p at node u based on the potential difference between node u and its neighbors as follows: |
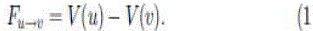 |
| The packet will be forwarded to the neighbor x in the direction of the steepest gradient, namely, the force from nodes u to x, is maximum. |
Depth Potential Field
|
| The depth potential field aims to ensure that packets will be transmitted to the sink. Let D(u) be the depth of node u. The depth potential Vd (u) is defined as Vd (u)= D(u). Hence, the force from node u to one of its neighbors v ∈ Ω(u) in the depth potential field is |
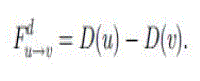 (2) (2) |
| The depth differences between node u and its neighbors v ∈ Ω(u) Can only be one of _1, 0, or 1 since the nodes two hops away from a node cannot become its neighbors. |
Pheromone Potential Field
|
| Pheromone potential field is constructed to gather the packets with the same attribute together. If the packets in WSN are treated as the ants leaving volatile pheromone at each passed node, a path selected by more packets will have more pheromone and can attract more packets with the same attribute. |
| Define ??(??, ??) as the amount of pheromone where i is the ID of node and ?? is the attribute of data packet. ??(??, ??) is initialized to 0. Each packet will leave constant pheromone |
| ?? when passing a node. Naturally, in ant colony, the pheromone will not only increase after ants passing but also continuously evaporate with the time. Here, in order to reduce overhead, only when a packet with attribute reaches node v or after an aggregation operation at node v, ??(??, ??) will be updated as follows: |
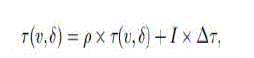 (3) (3) |
| where ????(0,1) reflects pheromone evaporation, and I is an indicative function. When a new packet with attribute reaches node v, I =1, and else I=0. |
| Since the packets will be forwarded to the sink in the steepest gradient direction, the nodes with more intense pheromone should have lower pheromone potential. There- fore, the pheromone potential field force Vp (??, ??) of node u is defined as Vp (u,??)=1- ??(??, ??) Hence, according to (6), the pheromone potential field force from node u to one of its neighbor is v ∈ Ω(u) is |
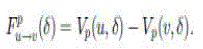 (4) (4) |
Packet-Driven Adaptive Timing Scheme
|
| The packets following the same path cannot ensure to be aggregated. They should meet with each other at the proper time. To increase the possibility that the packets meet with each other, a proper timing scheme is necessary. The timing control algorithm used in CT [21] exploits the relationship between the delay T required by applications and the depth hi of node ??. Node ?? aggregates packets and forwards abstracted data after waiting time Wi =(?? − ????? ×hi), where ????? represents the delay in a single hop. It is a typical solution of fixed timing schemes. The end-to-end delay is always constant T wherever source nodes locate. For example, the source nodes that are at most two hops away from the sink have to wait ?? − 2 × ????? and then forward packets. This will introduce the avoidable delay and degrades the performance. Besides, the waiting time is sometimes so long that some packets possibly overflow buffer. Furthermore, most of timing schemes will start up a timer at every node at the beginning of an application no matter whether the node will participate in applications, |
| To adapt to our dynamic routing protocol and overcome the drawbacks in existing timing schemes, we propose a packet-driven adaptive timing scheme. The node maintains a timer for the packets with the same attribute in its queue. When the timer fires, the corresponding aggregation is performed. When receiving one new packet, the value of timer Tu(t) at node u is initialized or updated dynamically as follows: |
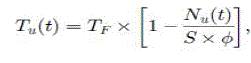 |
| where Nu(t) is the number of packets in the queue of node u, and the parameter ∅(0 < ∅ < 1) is ratio factor and TF is a time constant. Equation (14) indicates that when the queue occupancy ratio reaches to ∅, the timer fires since Tu(t) |
| approaches 0, and the aggregation is conducted immediately. The ratio factor ∅is introduced to accommodate burst arrival of packets in the reserved buffer with room (1 − ∅)?? to avoid excessive packet dropping. Equation (14) also states that the more the packets wait in the queue, the shorter is the interval of the timer. Generally, an event is monitored by some adjacent nodes nearly at the same time. |
| Hence, if some downstream nodes monitor an event, the Up stream node can receive the packets sent by its direct downstream nodes at about ?? + ?????; thus, it is responsive enough to set TF as the delay in a single hop. Naturally, the larger TF is beneficial for data aggregation but will increases the end-to-end delay. Because the value of timer for aggregation operation is updated according to the number of the packets in queue when one packet arrives, the timing control algorithm for our ADA is packet driven and adaptive. |
PERFORMANCE EVALUATION
|
| In this section, we conduct series of simulation experiments to evaluate the performance of the ADA scheme and compare it with some typical data aggregation schemes. |
Performance Metrics
|
| To make a performance evaluation, we introduce two special metrics except for common performance metrics, such as delay and dropping ratio |
| -Average number of transmission per received packet (ANTRP) is defined as the ratio of the total number of transmissions to the total number of packets received by the sink. Without data aggregation, every packet generated at the node whose depth is d can reach the sink after at least d transmissions. An efficient data aggregation mechanism will reduce transmissions by aggregating packets at intermediate nodes. Thus, ANTRP is a proper metric to evaluate the efficiency of data aggregation schemes. |
| Aggregation ratio (AR) is define as the ratio of the total number of packets received by the sink to the difference between the total number of packets generated by applications and the number of dropped packets. If there are only packets with the same attribute and most packets are aggregated near events and then forwarded to the sink, the sink will receive a few packets. Conversely, the fact that more packets are received at the sink indicates that fewer aggregation operations are performed in networks. |
Experimental Setup
|
| We implement the ADA scheme in nes C and use the TOSSIM simulator integrated in Tiny OS to evaluate its performance. Assume that an aggregation function can merge the packets with correlated information into one packet regardless of its actual operators. This assumption can be held for some common aggregation operators, such as MAX, MIN, SUM, AVG, STD, and VAR [36]. The deployment of network and the key parameters in experiments are listed in Table 1. The other particular parameters in different scenarios will be introduced in the related sections. Fig. 3 shows a randomly deployed network with three circular monitoring areas. With regard to the setting of parameters ??, ?? and S, we set S =32, ?? = 0:9, and ?? =0:78. A relatively large indicates that the pheromone evaporates more slowly, which is propitious to make the packets with identical attribute be transmitted along the same path to the sink. Otherwise, in our simulations, three different scenarios where node density and scale vary, respectively, and a mobile event is introduced, are designed to conduct a comprehensive performance evaluation and comparison with the following typical schemes: |
| . SPT: Packets are forwarded to the sink along the shortest path. Aggregation is opportunistic and happens only if two packets with the same attribute encounter at the identical node as well as at the same instant. |
| . CT: The shortest path tree with CT scheme proposed in [21]. |
| . DDS: A special dominating set is constructed first and then a connected dominating set is constructed to connect dominators and the other nodes [37], and the resultant tree can act as the aggregation tree in [38]. |
| . WCDS: A directed tree over the sensor network nodes is constructed to compress the value of a node using the value of its parent proposed in [39]. |
| To the best of our knowledge, little work focus on the data aggregation in WSN with heterogeneous sensor and various applications. Actually, in the homogeneous environment, our ADA scheme should have advantage over the existing data aggregation scheme employing the static routing protocol. To verify this prediction, the above four schemes are chosen to make comparison with the ADA scheme. It is noted that the DDS in [38] only provides an aggregation tree. To make proper comparison, the adaptive timing control scheme presented in this work is combined with the aggregation tree of DDS in simulation experiments |
Results
|
General Results
|
| A WSN with 999 sensor nodes is randomly deployed in a 1000 m ×1000 m rectangular region. The communication range of a node is 18 m and the sink locates at (874 m, 550 m). There are two different applications. The packets are randomly generated with average interval 30 ms. All applications start at 100 s and end at 130 s. Table 2 shows the application parameters. (x, y) is the coordinate of the center of the circle where the event happens and r is the radius of the circle. |
| attribute are more spatially convergent in ADA, we take a series of snapshots of the normalized queue length, and present them in Figs. 4, 5,6, and 7. To identify the packets with different attributes, the values of the normalized queue length of packets from two applications are artificially added by 1 or multiplied by 1, respectively. Apparently, the distribution of packets in space is centralized in ADA so that the normalized queue length is smaller than those in other schemes. This phenomena occurring in the queue indicate that ADA does more efficient aggregation than CT, DDS, and WCDS since ADA always attracts the packets with the same attribute together, the limited buffer on nodes only caches the packets from one applications, which can be inferred from the following fact, namely, in ADA, the packets with the same attribute are transmitted to the sink along relatively constant paths, while in CT, DDS, and WCDS, the distribution of packets in space are decentralized.Both sharing buffer and decentralized paths are not beneficial for data aggregation. |
Node Density
|
| Generally, the density of nodes in WSNs is initially much dense, gradually decrease as some nodes die due to energy exhaustion or other factors. An efficient data aggregation scheme should perform well as long as the WSN is connected and no matter the node density is high or low.To evaluate the performance of ADA with different node density, nodes are deployed in a 100 m _ 100 m square |
| where the sink locates at (90 m, 50 m). The number of sensors changes from 100 to 450. In this way, the average number of neighbors of a node increases, i.e., the node density increases. Three different applications happens in a circle and the packets are randomly generated with average interval 10 ms. All three applications start at 110 s and end at 120 s. Table 3 lists the parameters related to applications. |
| (??, ??) is the coordinate of the center of the circle where the application happens and r is the radius of the circle. The ANTRP with different node density in different schemes is shown in Fig. 7a. We can observe that all the curves decline as the number of nodes increases. It is reasonable since the average number of neighbors of a node increases as nodes become denser, which is helpful to improve spatial convergence degree and then reduce ANTRP. SPT performs the worst since it does nothing to make packets spatially convergent and temporally con- vergent. We can also see that ADA outperforms the other schemes at any node density. |
| Fig. 8b illustrates the AR of different schemes in the same scenario. As the node density increases, all schemes perform better, and both ADA and DDS are prominent. It seems that ADA obtains more gains in Fig. 8b than that in Fig. 8a. The reason is that ADA indeed improves spatial and temporal convergence remarkably and thus the number of the packets received by the sink is rather small. However, with respect to the average number of transmissions per received packet as shown in Fig. 8a, the packets sometimes will be forwarded to the next hop with the same depth or even with a deeper depth to improve spatial convergence degree. Although this detour transmission increases the number of transmissions, it is indeed beneficial for data aggregation. Hence, the advantages of ADA in Fig. 8b is more obvious than that in Fig. 8a. |
Scalability
|
| The scale of WSNs could be very large. For example, a WSN could be deployed on an island for biological investigation or in the forest to detect fire. The scalability of protocols in WSN is very important, at least, the performance should gracefully degrades as the network size increases. To evaluate the scalability of our ADA, we enlarge the WSN into a 1000 m 1000 m rectangular area with 1,000 sensors and the radio range becomes 50 m. The sink locates at (950 m, 500 m). Only one application happens in a circle with radius of 40 m and the center of the circle is (x.y)where y = 500 and 5), namely the different distances between the event and the sink denote WSNs with different scale. The packets are randomly generated with average interval of 100 ms. |
Different scale
|
| The average number of transmissions per received packet and AR with different distance to the sink are presented in Fig. 8. As for ANTPR, the advantage of ADA compared with the other schemes is impressive as shown in Fig. 8a. As for AR, Fig. 8b shows that when the distance from the center of the event to the sink is 100 m, CT performs better than ADA. It is reasonable that when the event is much closer to the sink, there are few chances for ADA to collect packets and aggregate them before they reach the sink. However, in CT, the packets at the upstream nodes will wait the packets forwarded by their downstream nodes and then aggregate them, which results in fewer packets received by the sink. When the distance between the center of the event and the sink becomes longer than 100 m, both ADA and DDS perform better than CT, SPT, and WCDS. Only at several sporadic points, the AR of ADA is larger than that of DDS. |
CONCLUSIONS
|
| The data aggregation is an effective mechanism to save limited energy in WSNs. Heterogenous sensors a n d various applications likely run in the same network. To handle this heterogeneity, in this paper, we introduce the concept of packet attribute to identify different packets generated by heterogenous sensors and different applications, and then propose an attribute-ware data aggregation scheme consisting of PBDR protocol and packet-driven timing control algorithm. Packets are treated as ants, and then the basic mechanism for finding paths based on pheromone in ant colony is borrowed to attract the packets with the same attribute to gather together. Enlightened by the concept of potential in physics, a PBDR protocol is developed. Combining with the adaptive timing control algorithm, the attribute-ware data aggregation scheme can make the packets with the same attribute spatially convergent as much as possible, and therefore improve the efficiency of data aggregation. The simulation experiments validate the effectiveness of our ADA scheme and demonstrate that it also has some properties required by actual applications in WSNs, such as scalable with respect to network size and suitable for tracking mobile events, and so on. In addition, the theoretical analysis provides some guidelines on parameter settings. |
Tables at a glance
|
|
|
| |
Figures at a glance
|
 |
 |
 |
 |
 |
| Figure 1 |
Figure 2 |
Figure 3 |
Figure 4 |
Figure 5 |
 |
 |
 |
 |
| Figure 6 |
Figure 7 |
Figure 8 |
Figure 9 |
|
| |
References
|
- R. Szewczyk, A. Mainwaring, J. Polaster, and D. Culler, “An Analysis of a Large Scale Habitat Monitoring Application,” Proc. ACM Int’l Conf. Embedded Networked Sensor Systems (SenSys), 2004.
- Q. Fang, F. Zhao, and L. Guibas, “Lightweight Sensing and Communication Protocols for Target Enumeration and Aggregation,” Proc. Fourth Int’l ACM Symp. Mobile Ad Hoc Networking and Computing, 2003.
- M. Hefeeda and M. Bagheri, “Forest Fire Modeling and Early Detection Using Wireless Sensor Networks,” Ad Hoc and Sensor Wireless Networks, vol. 7, nos. 3/4, pp. 169-224, Apr. 2009.
- D.L. Hall and J. Llinas, “An Introduction to Multisensor Data Fusion,” Proc. IEEE, vol. 85, no. 1, pp. 6-23, Jan. 1997.
- D. Li, K. Wong, Y.H. Hu, and A. Sayeed, “Detection, Classification and Tracking of Targets in Distributed Sensor Networks,” IEEE Signal Processing Magazine, vol. 19, no. 2, pp. 17-29, Mar. 2002.
- T. Clouqueur, K.K. Saluja, and P. Ramanathan, “Fault Tolerance in Collaborative Sensor Networks for Target Detection,” IEEE Trans. Computer, vol. 53, no. 2, pp. 320-333, Mar. 2004.
- X. Sheng and Y.H. Hu, “Energy Based Acoustic Source Localiza- tion,” Proc. IEEE Int’l Conf. Information Processing in Sensor Networks, pp. 285-300, 2003.
- M. Duarte and Y.H. Hu, “Vehicle Classification in Distributed Sensor Networks,” J. Parallel and Distributed Computing, vol. 64, no. 7, pp. 826-838, 2004.
- J. Heidemann, F. Silva, C. Intanagonwiwat, R. Govindan, D. Estrin, and D. Ganesan, “Building Efficient Wireless Sensor Networks with Low-Level Naming,” Proc. ACM Symp. Operating Systems Principles, pp. 146-159, 2001.
- W.R. Heinzelman, A. Chandrakasan, and H. Balakrishnan, “Application-Specific Protocol Architecture for Wireless Networks,” IEEE Trans. Wireless Comm., vol. 1, no. 4, pp. 660-670, Oct. 2002.
- S. Lindsey, C. Raghavendra, and K.M. Sivalingam, “Data Gathering Algorithms in Sensor Networks Using Energy Metrics,” IEEE Trans. Parallel and Distributed Systems, vol. 13, no. 9, pp. 924-935, Sept. 2002
- O. Younis and S. Fahmy, “HEED: A Hybrid, Energy-Efficient, Distributed Clustering Approach for Ad Hoc Sensor networks,” IEEE Trans. Mobile Computing, vol. 3, no. 4, pp. 366-379, Dec. 2004.
- M. Ding, X. Cheng, and G. Xue, “Aggregation Tree Construction in Sensor Networks,” Proc. IEEE 58th Vehicular Technology Conf., pp. 2168-2172, Oct. 2003.
- H.O. Tan and I. Korpeoglu, “Power Efficient Data Gathering and Aggregation in Wireless Sensor Networks,” SIGMOD Record, vol. 32, no. 4, pp. 66-71, Dec. 2003.
- R. Cristescu, B. Beferull-Lozano, and M. Vetterli, “On Network Correlated Data Gathering,” Proc. IEEE INFOCOM, pp. 2571-2582, Mar. 2004.
- J. Li, A. Deshpande, and S. Khuller, “On Computing Compression Trees for Data Collection in Wireless Sensor Networks,” Proc. IEEE INFOCOM, 2010.
- W. Zhang and G. Cao, “DCTC: Dynamic Convoy Tree-based Collaboration for Target Tracking in Sensor Networks,” Ad Hoc and Sensor Wireless Networks, vol. 3, pp. 1689-1701, Sept. 2004.
- Y.-K. Kim, R. Bista, and J.-W. Chang, “A Designated Path Scheme for Energy-Efficient Data Aggregation in Wireless Sensor Net- works,” Proc. IEEE Int’l Symp. Parallel and Distributed Processing with Applications, pp. 408-415, 2009.
- K. Fan, S. Liu, and P. Sinha, “On the Potential of Structure-Free Data Aggregation in Sensor Networks,” Proc. IEEE INFOCOM, pp. 1-12, Apr. 2006.
- S.R. Madden, M.J. Franklin, J.M. Hellerstein, and W. Hong, “TAG: A Tiny Aggregation Service for Ad-hoc Sensor Networks,” Proc. Symp. Operating Systems Design and Implementation (OSDI), pp. 131-146, Dec. 2002.
- I. Solis and K. Obraczka, “In-Network Aggregation Trade-offs for Data Collection in Wireless Sensor Networks,” Int’l J. Sensor Net works, vol. 1, nos. 3/4, pp. 200-212, 2006.
- F. Hu, X. Cao, and C. May, “Optimized Scheduling for Data Aggregation in Wireless Sensor Networks,” Proc. Int’l Conf. Information Technology: Coding and Computing (ITCC ’05), pp. 156-168, 2005.
- Z. Ye, A. Abouzeid, and J. Ai, “Optimal Policies for Distributed Data Aggregation in Wireless Sensor Networks,” Proc. IEEE INFOCOM, pp. 1676-1684, May 2007.
- X. Xu, X. Li, P. Wan, and S. Tang, “Efficient Scheduling for Periodic Aggregation Queries in Multihop Sensor Networks,” ACM/IEEE Tran s. Networking, vol. 20, no. 3, pp. 690-698, June 2012.
- H. Luo, H. Tao, H.M. Sajal, and K. Das, “Data Fusion with Desired Reliability in Wireless Sensor Networks,” IEEE Trans. Parallel and Distributed Systems, vol. 22, no. 3, pp. 501-513, Mar. 2011.
- H. Tan and I. Korpeoglu, “Power Efficient Data Gathering and Aggregation in Wireless Sensor Networks,” ACM SIGMOD Record, vol. 32, no. 4, pp. 66-71, 2003.
- G. Theraulaz and E. Bonabeau, “A Brief History of Stigmergy,” Artificial Life, vol. 5, no. 2, pp. 97-116, 1999.
- A. Basu, A. Lin, and S. Ramanathan, “Routing Using Potentials: A Dynamic Traffic-Aware Routing Algorithm,” Proc. ACM SIGCOMM, pp. 37-48, 2003.
- C. Liu and G. Cao, “Distributed Monitoring and Aggregation in Wireless Sensor Networks,” Proc. IEEE INFOCOM, 2010.
- W. Pu, D. Rui, and I. Akyildiz, “Collaborative Data Compression Using Clustered Source Coding for Wireless Multimedia Sensor
- B.J. Culpepper, L. Dung, and M. Moh, “Design and Analysis of Hybrid Indirect Transmissions for Data Gathering in Wireless Micro Sensor Networks,” ACM SIGMOBILE Mobile Computing and Comm. Rev., vol. 8, pp. 61-83, 2010.
- S.J. Park and R. Sivakumar, “Energy Efficient Correlated Data Aggregation for Wireless Sensor Networks,” Int’l J. Distributed Sensor Networks, vol. 4, no. 1, pp. 13-17, 2008.
- G.D. Caro and M. Dorigo, “AntNet: Distributed Stigmergetic Control for Communication Networks,” J. Artificial Intelligence Research, vol. 9, no. 1, pp. 317-365, 1998.
- F. Ducatelle, G.D. Caro, and L. Gambardella, “Ant Agents for Hybrid Multipath Routing in Mobile Ad Hoc networks,” Proc. Second Ann. Conf. Wireless Demand Network Systems and Services (WONS), 2005.
- D.Y. Kwon, J. hwa Chung, T. Suh, W. gyu Lee, and K. Hury, “ Potential Based Routing Protocol for Mobile Ad Hoc Networks,”
- S. Yoon and C. Shahabi, “The Clustered AGgregation (CAG) Technique Leveraging Spatial and Temporal Correlations in Wireless Sensor Networks,” ACM Trans. Sensor Networks, vol. 3, no. 1, pp. 1-39, Mar. 2007.
- X. Xu, X.-Y. Li, X. Mao, S. Tang, and S. Wang, “A Delay-Efficient Algorithm for Data Aggregation in Multihop Wireless Sensor Networks,” IEEE Trans. Parallel Distributed Systems, vol. 22, no. 1, pp. 163-175, Jan. 2011.
- P.J. Wan, K. Alzoubi, and O. Frieder, “Distributed Construction of Connected Dominating Set in Wireless Ad Hoc Networks,” Mobile Networks and Applications, vol. 9, pp. 141-149, 2004.
- J. Li, A. Deshpande, and S. Khuller, “On Computing Compression Trees for Data Collection in Wireless Sensor Networks,” Proc. IEEE INFOCOM, pp. 2115-2123, 2010.
|