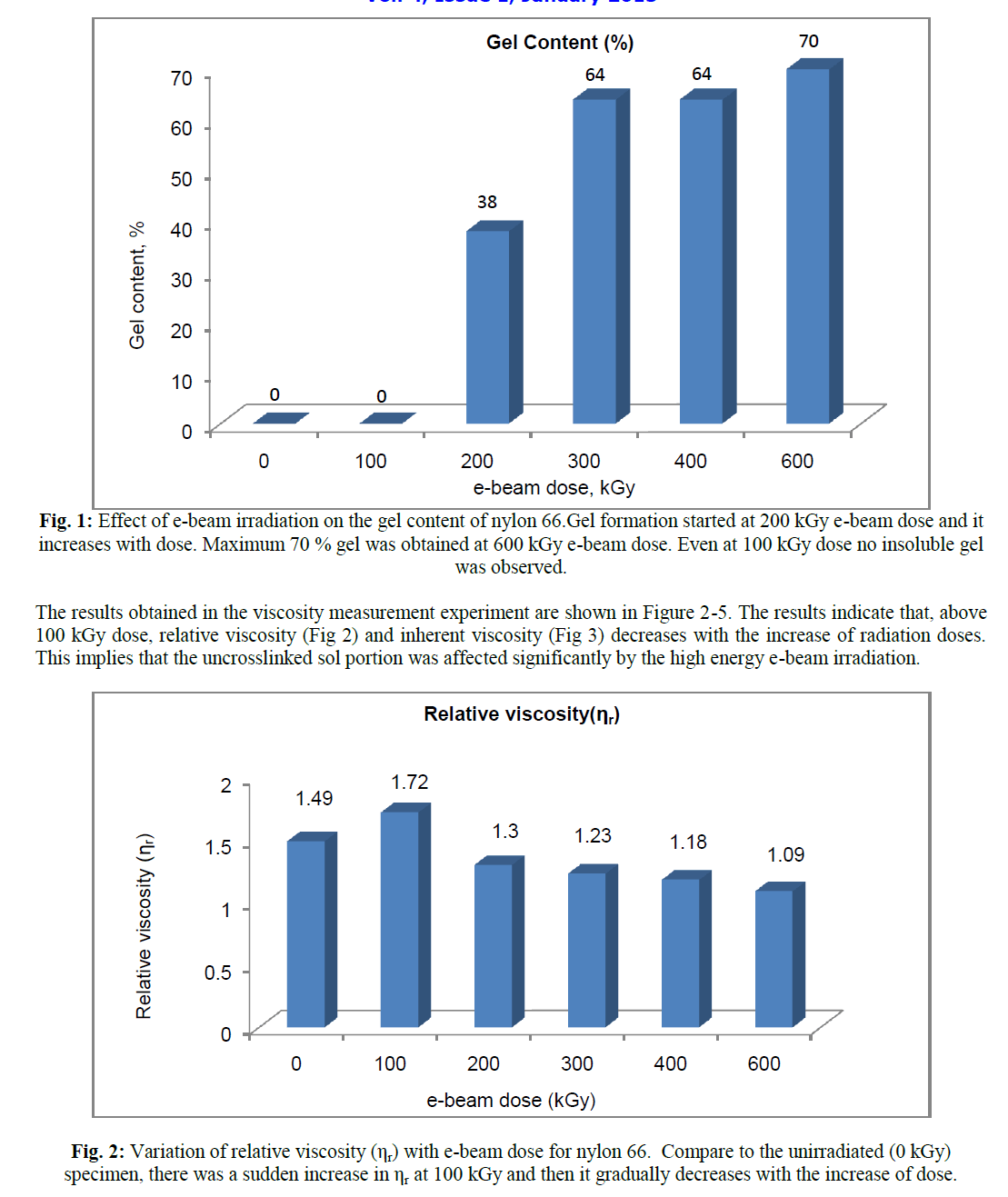
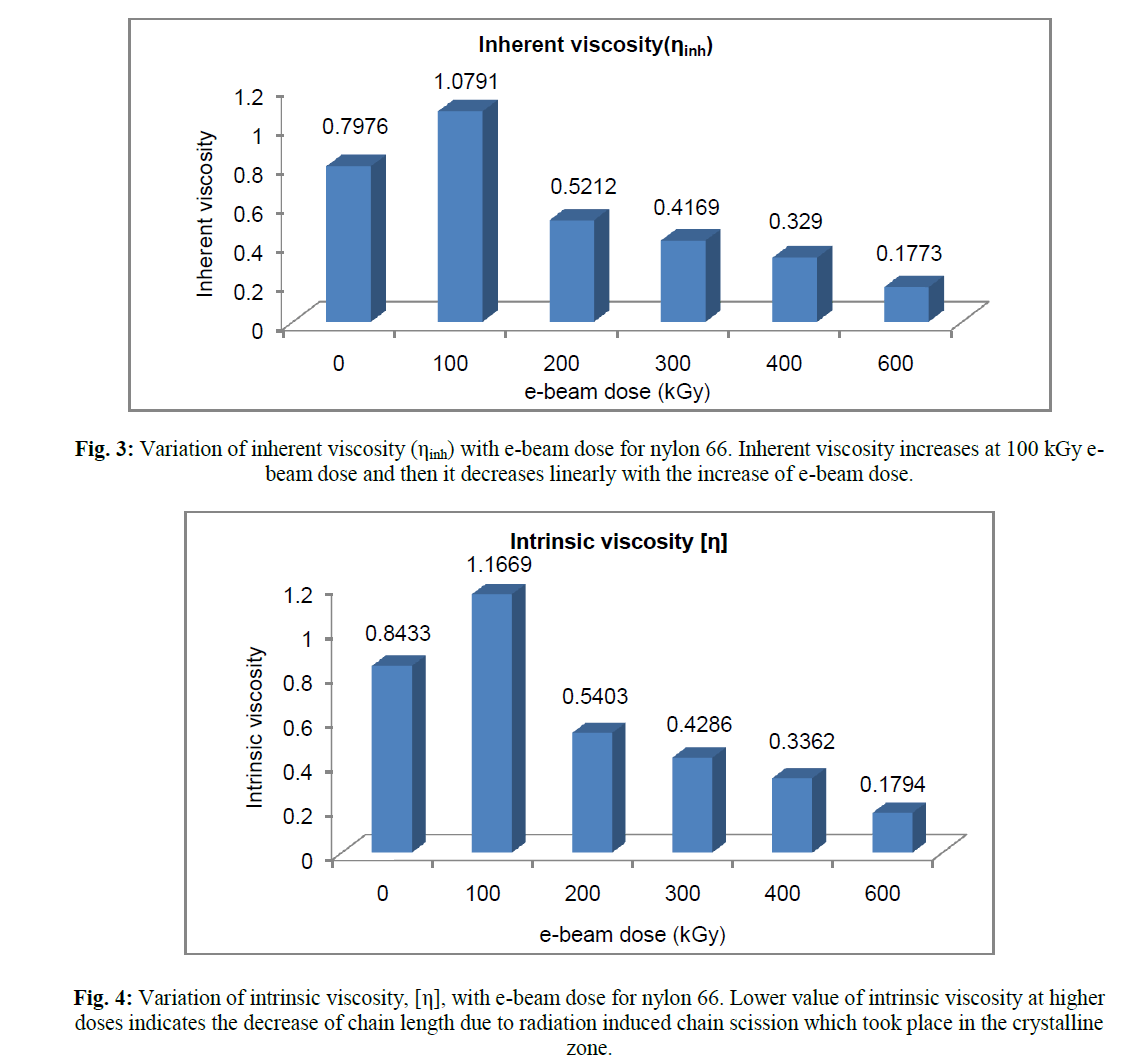
International Journal of Innovative Research in Science, Engineering and Technology
ISSN ONLINE(2319-8753)PRINT(2347-6710)
ISSN ONLINE(2319-8753)PRINT(2347-6710)
S.Muthamizharasi1, J.Selvakumar2, M.Rajaram3
|
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Innovative Research in Science, Engineering and Technology
During software evolution and maintenance, requirement traceability links become outdated because developers could not dedicate effort to updating them. So far, recovering these traceability links later is intimidated and costly task for developers. Earlier methods used information retrieval for recovering traceability links between free-text requirements and source code. However the accuracy is limited in such methods. To deal with this, the proposed system uses Relink, an automatic link recovery algorithm. The proposed approach is based on automatically learned feature criteria from explicit links. In addition the missing links can be found which affects defect prediction performance. We also assessed the impact of recovered links on software maintainability measurement, and established the result of ReLink affords considerably better accuracy than those of conventional heuristics.
Keywords |
| Traceability, Link, Relink, Histrace, Trumo, DynWing |
INTRODUCTION |
| Requirements traceability has obtained much consideration over the past decade in the scientific literature. It is defined as “the ability to illustrate and go after the life of a requirement, in both a forward and backward direction”. Traceability links among the requirements of a system and its source code aids in reducing system comprehension attempt. Until now, during maintaining and evolving the Software, the developers can add, remove, or modify features. Requirement traceability links turn into obsolete because developers cannot devote effort to updating them. However recovering these traceability links later is a daunting task for developers and also they frequently evolve requirements and source code in a different way. In fact, they usually do not update requirementtraceability links with source code. Requirements and source code subsequently different from each other, which decreases the textual similarity. |
| Trustrace is defined as a traceability-recovery approach between the requirements and source code, which is mainly used to improve the accuracy of Traceability. To dynamically discard or rerank the traceability links reported by an IR technique it uses heterogeneous sources of information. Trustrace consists of three parts: |
| ïÃâ÷ Histrace |
| ïÃâ÷ Trumo |
| ïÃâ÷ DynWing |
| Histrace |
| To create links between requirements and source code Histrace mines software repositories by using information from the repositories. It stores all the recovered links between requirements and software repositories in sets.e.g., Histracecommits and Histracebugs are considered as experts whose opinions will be used to discard or rerank baseline traceability links. |
| Trumo |
| Trumo merges the requirement traceability links attained from an IR technique and discards or reranks them using an expert’s opinions and a trust model motivated by web-trust models. It compares the similarity of the recovered links with the result provided by the experts and with the number of times the link appears in each expert’s set. This is not fixed to any definite IRbased traceability-recovery approach and thus it can use any expert’s view to correct the ranking of recovered links. |
| DynWing |
| DynWing calculates and allocates weights to the experts in the trust model dynamically. Thus, dynamicweighting techniques are promoted to assign weights for each link. DynWing initializes each expert’s similarity value for each link and assigns weights depends on to these values. |
| To discover possibilities of recovering the missing links automatically, a qualitative study has been conducted to recognize characteristics of explicit links based on the bug IDs in change logs. The links between bugs and changes has been found and demonstrated certain features. For instance, the bug-fixing time is relatively close to the change logs, change-commit time and the bug reports share textual similarity, and the developers accountable for a bug are usually the committers of the bug-fixing change. According to these findings, we propose a ReLink, an automatic link recovery algorithm. Relink automatically learns the criteria of features from explicit links, and applies the learned criteria which checks whether the features of an unknown link assure the criteria. The valid link can be obtained when the unknown link satisfies all the feature criteria. |
II. RELATED WORK |
| The literature used many methods, techniques, and tools to recover the traceability links semiautomatically or automatically. |
| Requirements traceability has obtained much notice over the past decade in the scientific literature. To recover traceability links between high-level documents various researchers used information retrieval (IR) techniques, e.g., [1], [2], [3]. |
| S.A. Sherba and K.M. Anderson in [4] presented a new approach to traceability based on practices from information integration and open hypermedia. Information integration and Open hypermedia offers generic techniques for establishing, viewing and maintaining connections between artifacts of software. This approach permits the automated creation, viewing and maintenance of traceability relationships in tools in which software professionals are get to know using on a daily basis. Though, due to the heterogeneous nature of this artifact, creating, viewing and maintaining these relationships is intensely difficult. |
| Maider et al.in [5] presented an approach to hold automated traceability maintenance by recognizing development behavior. Development behavior is officially specified and changed to definite model elements triggered a LinkUpdateManager. LinkUpdateManager is accountable for updating traceability links that are shared to the changed elements. Though, the authors did not declare how traceability links are in fact created and updated. |
| Lucia et al.in [6] presented an approach supporting developers to keep source code identifiers and comments reliable with high-level artifacts. This approach calculates textual similarity between related high-level artifacts and source code. The textual similarity supports developers to develop their source code list. |
| Maletic and Collard in [7] presented TQL, an XMLbased traceability query language. TQL helps the queries among multiple artifacts and traceability link types. TQL has primitives to permit complex query construction and execution support. In this the following question arised that how does a change impact the requirements? How does a change to the requirements impact the safety of the system? |
| Gethers in [8] exploited the empirical finding and presented an integrated approach to combine orthogonal IR techniques. Thus this has been statistically shown to create dissimilar results. The presented approach merges the following IR-based methods: probabilistic Jensen and Shannon (JS) model, and Relational Topic Modeling (RTM) and Vector Space Model (VSM), which has not been used in the framework of traceability link recovery prior. However this returns that the satisfaction measurement of user requirements give less result.. |
III. EXISTING SYSTEM |
| In existing system Histrace creates links between the set of requirements and source code using the software repositories. It considers the requirements textual descriptions, CVS/SVN commit messages, classes and bug reports as separate documents. |
| These sources of information were used to produce two experts, which we call Histracecommits and Histracebugs, which use CVS/SVN commit messages and bug reports respectively. Histrace must link CVS/SVN commit messages to bug reports before being able to exploit bug reports for traceability. |
| In this Histrace uses regular expressions that are a simple text matching approach except with reasonable results, to link CVS/SVN commit messages to bug reports. |
| As a result, Histrace takes that developers allocated to each bug which has a unique ID that is a sequence of digits recognizable through regular expressions. The same ID must be preferred to by developers in the CVS/SVN commit messages. |
| To link CVS/SVN commit messages to bug reports, Histrace performs the following steps: |
| 1) All CVS/SVN commit messages are extracted along with commit status and committed files. |
| 2) All the bug reports are being extracted, along with textual descriptions and time/date and |
| 3) Each CVS/SVN commit message and bug reports are linked by using regular expressions, e.g. |
| ((B)[UG]{0,2}\S*[ID]{0,3}|ID|FIX|PR|#)[\S#=]*[?(0— 9]{4,6})]? |
| Which is the regular expression refrained to the numbering and naming conventions used by the developers. This expression to be updated which matches with other numbering and naming conventions. |
| At last Histrace takes out false-positive links by imposing the following constraint |
| Fix(e[ds])?|bugs?|problems?|defects?patch”. |
| The above regular-expression constraint keeps only a CVS/SVN commit when it contains a keyword. Thus it returns the bug reports linked to CVS/SVN commit messages. |
IV. PROPOSED SYSTEM |
| In proposed CVS/SVN commit message and bug reports are linked using the ReLink method, this method recovers the link between bug and changes. |
| A.Features of Links |
| The proposed method finds the features of links between bugs and changes. The following features identify and recover the missing links. |
| Time Interval: This is the interval between the time (tf) when a bug was fixed as given by its bug report and the time (tc) when the corresponding bug fix was committed at the code repository.This feature is useful because it fix the bugs after its creation and before closure. |
| Bug Owner and Change Committer |
| For linked bugs and changes, there exists a mapping between the bug owner and the change committer. |
| Committer: the person who is responsible for fixing the bug .The mapping between these two persons could be identified through mining of software repositories. |
Text Similarity |
| This is the textual similarity between bug reports and change logs. For the concept of linked bugs and changes, the natural language descriptions in the bug report are frequently analogous to those in the change logs, as they may points to the same issue and share similar keywords. |
B.Link feature mining |
| The Interval between the Bug-fixing time and the Change-Commit Time: Even though the interval between commit time and bug-fixing time is a useful feature for mining links, identifying the length of such an interval is a difficult task. It is observed from evaluation that developers do not often change the status of bugs to “Fixed” in the bug tracking system abruptly after they have committed the changes of bug-fixing. The changecommit time and the bug-fixing time could be far apart. Further investigations found that most bug comments are close to bug-fixing activities, while developers frequently post comments to the bug tracking system to report a bug fix and inform the bug reporter. Consequently, the bugfixing time according to the time of comments in bug reports were also to be determined. |
Mapping between Change Committers and Bug Owners |
| To identify the mappings between bug owners and change committers, the comments in bug reports were examined. These empirical studies found that developers frequently discuss bug-related issues and declare bug fixes through the bug tracking system. As a result, it is likely that one of the commenters is the bug owner who is liable for bug fixing. |
| The Similarity between Bug Reports and Change Logs |
| In this project, bug reports and change logs are treated as texts and their similarities are compared. It is anticipated that for linked bugs and changes, change logs reveal certain similarity. In order to compute the similarity between bug reports and change logs, text features are need to be extracted. |
| To select the delegate terms in the text, the following steps to be used to reduce dimensions for long bug reports and change logs. |
 |
 |
V. EXPERIMENTAL RESULT |
| The proposed system can be evaluated based on traceability links such as baseline requirements, JSM and VSM. The qualitative analyses of the proposed system results and discuss observations from the empirical evaluation of Trustrace. |
Data Set Quality Analysis |
| The empirical evaluation of proposed system supports the Trustrace combined with IR techniques is effective in increasing the precision and recall values of some baseline requirements traceability links. This uses both JSM and VSM to recover traceability links and compare their results in isolation with those of Trustrace. The proposed system performs better than existing approach in terms of precision, recall and f-measure. |
| The following comparison table1 provide the estimated values for the existing and proposed approach. |
 |
| The above graph in figure 1 shows precision rate in which the proposed system performs higher than existing in the traceable links of Baseline IR, JSM and VSM respectively. |
 |
| The above graph in figure 2 shows recall rate in which the proposed system performs higher than existing in the traceable links of Baseline IR, JSM and VSM respectively. |
 |
| The above graph in figure 3 shows f-measure rate in which the proposed system performs higher than existing in the traceable links of Baseline IR, JSM and VSM respectively. |
VI. CONCLUSION |
| In this paper, a traceability-recovery approach between requirements and source code is supported on three conjectures: Histrace, Trumo, and DynWing. The proposed Relink recovers the link between bug and changes in Histrace which creates links between the set of requirements and source code using the software repositories .The features of links are identified and mined in the above discussion. Finally missing link can be learned by using Relink method followed by determining the Threshold and mapping criteria’s. Experimental result for various traceability links has been demonstrated .In that proposed system outperforms better than existing system. |
References |
|