Keywords
|
| Search Engine, Link based search, PageRank and Weighted PageRank. |
INTRODUCTION
|
| WWW is a vast resource of hyperlinked and heterogeneous information including text, image, audio, video and metadata. From early 1990’s WWW has seen an explosive growth. It is estimated that WWW has expanded by about 2000% since its evolution and is doubling in size every six to ten months [1]. With huge increase in availability of information through WWW, it has become difficult to access desired information on Internet; therefore many users use Information retrieval tools like Search Engines to search desired information on the Internet A Search Engine is an information retrieval system which helps users finds information on WWW by making the web pages related to their query available. With a search engine, users have to type in “keywords” relating to the information that they need. The search engine would then return a set of results that match best with the keywords entered. A Web Search Engine can therefore be defined as a software program that takes input from the user, searches its database and returns a set of results. It is important to note that the search engine does not search the internet; rather it searches its database, which is populated with data from the internet by its crawler(s). Web search engines work by storing information about many web pages, which they retrieve from the WWW itself. These pages are retrieved by a Web crawler which follows every link it sees. Exclusions can be made by the use of robots.txt. The contents of each page are then analyzed to determine how it should be indexed. Data about web pages are stored in an index database for use in later queries. The typical architecture of a search engine is shown in Fig[1]. |
| The major components of search engine are Crawler, Indexer and Query processor. A crawler traverses the web by following hyperlinks and storing downloaded pages in a large database. It starts with seed URL and collects documents by recursively fetching links and storing the extracted URL’s into a local repository. The Indexer processes and indexes the pages collected by the crawler. It extracts keywords from each page and records the URL where each word has occurred. |
| The query engine is responsible for receiving and filling search requests from user. When a user fires a query, query engine receives it and after matching the query keywords with the index, returns the URL’s of the pages to the user. |
| In general Query Engine may return several hundreds or thousands of URL that match the keywords for a given query. But often users look at top ten results that can be seen without scrolling. Users seldom look at results coming after first search result page, which means that results which are not among top ten are nearly invisible for general user. Therefore to provide better search result, page ranking mechanisms are used by most search engines for putting the important pages on top leaving the less important pages in the bottom of result list. Some of the common page ranking algorithms are PageRank Algorithm [2, 3], Weighted PageRank Algorithm [4] and Hyperlinked Induced Topic search Algorithm [5]. |
| The aim of the paper is to analyse the two popular web page ranking algorithms- Weighted PageRank algorithm and PageRank algorithm and to provide a comparative study of both and to highlight their relative strengths and limitations. |
PAGE RANKING ALGORITHMS
|
| To present the documents in an ordered manner, Page Ranking methods are applied, which can arrange the documents in order of their relevance, importance and content score. Search engines use two different kinds of ranking factors: querydependent factors and query Independent Factors .Query-dependent are all ranking factors that are specific to a given query, while query-independent factors are attached to the documents, regardless of a given query. Query-dependent factors used by search engines are measures such as word documents frequency, the position of the query terms within the document or the inverted document frequency, which are all measures that are used in traditional Information Retrieval. Some of the query independent factors are Link popularity, Click popularity and uptodateness etc. Ranking algorithms based on link popularity, falls under Link based ranking algorithm category. |
LINK BASED PAGE RANKING ALGORITHMS
|
| Link based Page ranking algorithms are based on link structure of the web document. They view the web as a directed graph where the web pages form the nodes and the hyperlinks between the web pages form the directed edges between these nodes [6]. Two important Link Based Page algorithms are given below : |
| PageRank[2] |
| Weighted PageRank [5]. |
| A. PageRank |
| Brin and Page [2] developed a ranking algorithm at Stanford University named PageRank after Larry Page. Page Rank algorithm uses link structure to determine the importance of web page. This algorithm is based on random surfer model. The random surfer model assumes that a user randomly keeps on clicking the links on a page and if she/he get bored of a page then switches to another page randomly. Thus, a user under this model shows no bias towards any page or link. PageRank(PR) is the probability of a page being visited by such user under this model |
| Page Rank algorithm assumes that if a page has a link to another page then it votes for that page. Therefore, each inlink to a page raises its importance. PageRank is a recursive algorithm in which the PageRank of a page depends upon the PageRank of the pages linking to it. Thus, not only the number of inlinks of a page influences its ranking but also the page ranks of the pages linking to it. A page confers importance to the pages it references to by evenly distributing its PageRank value among all it’s outlinks. |
| The PageRank of page P is given as, follows: |
 |
| Where |
| N0...Nn are the pages that point to page P. |
| O(Ni) is defined as the number of links going out of page P. |
| The parameter d is a Damping factor which can be set between 0 and 1. |
| Damping factor, d is the probability of user’s following the direct links and 1- d denotes the rank distribution from non – directly linked web pages. It is usually set to 0.85. So it is easy to infer that every page distributes 85% of its original PageRank evenly among all pages to which it points. As is evident from the above equations, even if a page doesn’t have any inlinks it still has a minimum PR value of 1-d. |
| Following is a simplified example of the PR algorithm. Consider web graph shown in fig3. |
| Page, P being referenced by pages Q and R .Q, R has 2,3 outlinks. Then pageRank value of the page P is given as: |
| PR(P)=1-d + d(PR(Q)/2 + PR(R)/3) |
Iterative Method of Page Rank
|
| In iterative calculation, each page is assigned a starting page rank value of 1. These rank values are iteratively substituted in page rank equations to find the final values. In general, much iteration could be followed to normalize the page ranks. |
| The PageRank algorithm can be iteratively applied as: |
| 1) Initially let Page rank of all web pages is one |
| 2) Calculate page ranks of all pages by using above formula. |
| 3) Repeat step 2 until values of two consecutive iterations match. |
| 1) Advantages |
| • Less Time consuming:- As pageRank is a query independent algorithm i.e. it precomputes the rank score so it takes very less time |
| • Feasibility:-This algorithm is more feasible as it computes rank score at indexing time not at query time. |
| • Importance: - It returns important pages as Rank is calculated on the basis of the popularity of a page |
| • Less susceptibility to localized links: - For calculating rank value of a page, it consider the entire web graph, rather than a small subset, it is less susceptible to localized link spam. |
| 2) Disadvantages: |
| • The main disadvantage is that it favours older pages, because a new page, even a very good one, will not have many links unless it is part of an existing web site. |
| • Relevancy of the resultant pages to the user query is very less as it does not consider the content of web page. |
| • Dangling link: This occurs when a page contains a link such that the hypertext points to a page with no outgoing links. Such a link is known as Dangling Link |
| • Rank Sinks: The Rank sinks problem occurs when in a network pages get in infinite link cycles. |
| • Dead Ends: Dead Ends are simply pages with no outgoing links. |
| • Spider Traps: Another problem in PageRank is Spider Traps. A group of pages is a spider trap if there are no links from within the group to outside the group. |
| • Circular References: If you have circle references in your website, then it will reduce your front page’s PageRank. |
| A. Weighted PageRank |
| Wenpu Xing and Ali Ghorbani [5] projected a Weighted PageRank (WPR) algorithm which is a modification to the PageRank algorithm. This algorithm assigns a larger rank values to the more important pages rather than dividing the rank value of a page evenly among its outgoing linked pages. Each outgoing link gets a value proportional to its importance. The importance is assigned in terms of weight values to the incoming and outgoing links and are denoted as Win(u,v) and Wout(u,v) respectively |
| Win(u,v)is the weight of link (u, v) calculated based on the number of incoming links of page v and the number of incoming links of all orientations pages of page u. |
 |
| Where Iv and Ip are the number of incoming links of page v and page p respectively. R (u) denotes the allusion page list of page u. |
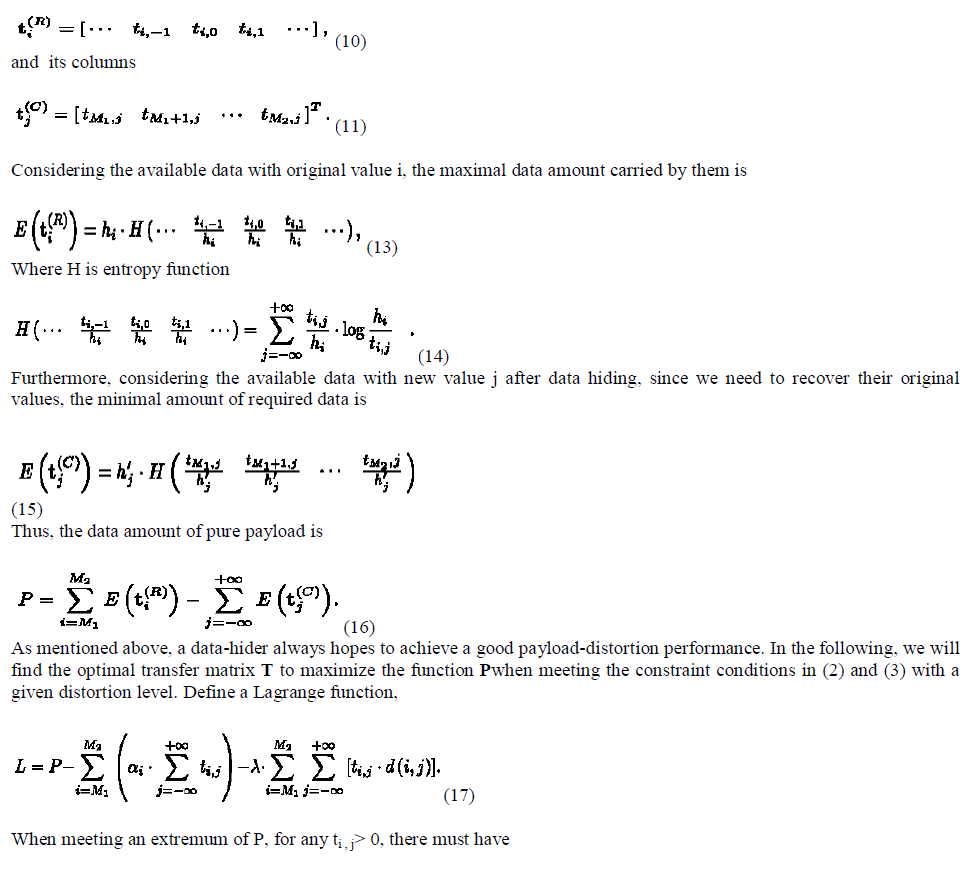 |
| Wout(u,v) is the weight of link (u,v) calculated based on the number of outgoing links of page v and the number of outgoing links of all orientations pages of page u. |
| The weights of incoming as well as outgoing links can be calculated as: |
 |
 |
| The formula as proposed by Wenpu et al for the WPR which is a modification of the PageRank formula is given as |
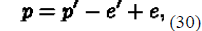 |
| 1) Advantages: |
| • Quality: Quality of the pages returned by this algorithm is high as compared to pageRank algorithm |
| • Efficiency: It is more efficient than pageRank because rank value of a page is divided among it’s outlink pages according to importance of that page. |
| 2) Disadvantages: |
| • Less Relevant: As this algorithm considers only link structure not the content of the page, it returns less relevant pages to the user query. |
EXPERIMENTS
|
| The WPR and pageRank algorithms were implemented and their results are being compared. Fig 5 illustrates different components involved in the implementation and evaluation of these algorithms. The simulation studies carried out in this work consist of following activities: |
| 1. Finding a web site: Finding a web site with rich hyperlinks is necessary because the standard PageRank and the WPR algorithms rely on the web structure. Insert these pages into database. |
| 2. Extracting URL : This module will extract links within the given page i.e outlinks of a web page. Then these outlink details are also added in the database. |
| 3. Finding Inlinks: From these extracted outlinks, inlinks can be found and stored in database. |
| 4. Applying algorithms: The Standard PageRank and the WPR algorithms are applied to the pages stored in the database. |
| 5. Evaluating the results: The algorithms are evaluated by comparing their results. |
EVALUATION
|
| A website that contains many web pages is considered. These web pages can be represented as a web graph as shown below in fig 6. |
| In this graph, nodes(A,B,…,J) are representing web pages pageA , pageB,……., pageJ and links between the web pages are represented by edges . Rank Score of web pages according to pageRank algorithm, rank_value and rank score of web pages by weighted pageRank algorithm , wrank_value are shown below in the fig 7. |
| As both of these algorithms work iteratively. The rank_value and wrank_value of web pages in various iterations is shown in below table I. |
Effect of damping factor
|
| The probability for the random surfer not stopping to click on links is given by the damping factor d, which depends on probability therefore, is set between 0 and 1. The higher d is, the more likely will the random surfer keep clicking links. Since the surfer jumps to another page at random after he stopped clicking links, the probability therefore is implemented as a constant (1-d) into the algorithm. Effect of this constant value is shown in table II. |
CONCLUSION & FUTURE WORK
|
| The usual search engines usually result in a large number of pages in response to user’s queries, while the user always wants to get the best in a short span of time so he/she does not bother to navigate through all the pages to get the required ones. The page ranking algorithms play a major role in making the user search navigation easier in the results of a search engine. The PageRank and Weighted Page Rank algorithm give importance to links rather than the content of the pages. According to PageRank algorithm, rank score of a web page is divided evenly over the pages to which it links whereas Weighted PageRank algorithm assigns larger rank values to more important (popular) pages. The PageRank and WPR return the important pages on the top of the result list. Some of the future work in these algorithms includes the following: |
| They can be combined with some content based ranking algorithm to improve relevancy of the web pages. |
| • The concept of no. of visits of a link can also be used in calculating weight of page in case of weighted pageRank algorithm. |
Tables at a glance
|
|
|
| |
Figures at a glance
|
 |
 |
 |
| Figure 1 |
Figure 2 |
Figure 3 |
|
 |
 |
 |
| Figure 4 |
Figure 5 |
Figure 6 |
|
References
|
- N. Duhan, A. K. Sharma and Bhatia K. K.,’ Page Ranking Algorithms: A Survey’, Proceedings of the IEEE International Conference on AdvanceComputing, 2009, 978-1-4244-1888-6.
- S. Brin, and Page L., ‘The Anatomy of a Large Scale Hypertextual Web Search Engine’, Computer Network and ISDN Systems, Vol. 30, Issue 1-7,pp. 107-117, 1998.
- Larry Page, and Sergey Brin, Rajeev Motwani, Terry Winograd, ‘The PageRank Citation Ranking: Bring Order to the ‘ , Technical report in StanfordU, 1998.
- EtizioniO.,’The World Wide Web: Quagmire or Gold Mine, Communications of the ACM, 39(11)’, pp. 65-68(1996).
- Wenpu Xing and Ghorbani Ali, ‘Weighted PageRank Algorithm’, Proceedings of the Second Annual Conference on Communication Networks andServices Research (CNSR ’04), IEEE, 2004.
- G.Kumar; N. Duhan; A.K. Sharma, ‘Page Ranking Based on Number of Visits of Links of Web Page ‘, International Conference on Computer &Communication Technology (ICCCT), 2011.
- R. Kosala.; H.Blockeel ,’Web Mining Research: A survey’, In ACM SIGKDD Explorations, 2(1), PP. 1–15.
- Mercy Paul Selvan ,A .Chandra Sekar and A.PriyaDharshin , ‘Survey on Web Page Ranking Algorithms’ ,International [Journal of ComputerApplications (0975 – 8887) Volume 41– No.19, March 2012.
- J. Kleinberg, ’Authoritative Sources in a Hyper-Linked Environment’ , Journal of the ACM 46(5), pp. 604-632,1999.
|