International Journal of Innovative Research in Computer and Communication Engineering
ISSN ONLINE(2320-9801) PRINT (2320-9798)
ISSN ONLINE(2320-9801) PRINT (2320-9798)
Boshra F. Zopon AL_Bayaty1, Dr. Shashank Joshi2
|
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Innovative Research in Computer and Communication Engineering
Word sense disambiguation is solved with the help of various data mining approaches like Naïve Bayes Approach, Decision List, decision tree, and SVM (Support Vector machine). These approaches help to find out correct meaning of word by referring WordNet 2.1. Experiment performed is discussed in this paper along with the comparison of SVM algorithm with various approaches. In this study Decision List achieved the best result among all other approaches.
Keywords |
||||||||||||
| Support Vector Machine, Naive Bayes, Decision List, Decision Tree, Supervised learning approaches, Senseval-3, WSD, WordNet. | ||||||||||||
INTRODUCTION |
||||||||||||
| Natural language processing is study of word and their meaning role from meaningful language. Most for every system this word acts as an input. While inferring means out of it, if system misinterprets it entire system will get affected. That’s why WSD is extremely important to infer correctly meaning of word as per the perception of user or machine who has inserted it. | ||||||||||||
| Word sense disambiguation is a task to identify correct meaning of word by using some algorithm with the help of some or other approach [1]. To accomplish this process system is trained to identify correct results meaning of word according to the multiple words like Map. Map is a geographical representation of particular place or it is an association between two terms (Mapping). So problem statement is to identify the meaning of given word as per the requirement of user [2]. | ||||||||||||
BACK GROUND AND RELATED WORK |
||||||||||||
| Many researchers have contributed to this field of disambiguation. There are various approaches to accomplish this task of disambiguation. | ||||||||||||
| • Support vector machine is to generate a hyperplan to separate hyperspace by separating them as per the category or group. Distance between closest edges of plan is known as support vector [3]. | ||||||||||||
| • Naive Bayes approach is a way to calculate posterior probability by using conditional probability. Naïve part of the classifier is to extract features dependency. It is assumed that there is no dependency among the features extracted[4]: | ||||||||||||
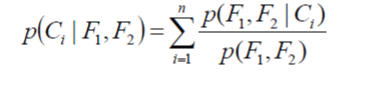 |
||||||||||||
| Where: | ||||||||||||
| F1, F2 are features | ||||||||||||
| C is category. | ||||||||||||
| • Decision tree deals with information gained during the experiment. In decision tree processing is from top to bottom that is from root to leaf. So if a length or tree is higher probability of data storage or information gain is comparatively higher. This also calculates the error rate in terms of entropy. Maximum is entropy minimum will be the accuracy and vice versa[5]. | ||||||||||||
| • Decision list works on condition like (If-else) structure. If condition is satisfied visit the node deal with data otherwise leave it. Repeat the process till desired data or conditions are not meet[6]. | ||||||||||||
| These approaches and their comparison is discussed in this paper based on the experiment which is performed to meet the goal of word sense disambiguation using effective approach for empirical retrieval of information. | ||||||||||||
Motivation |
||||||||||||
| To address the challenge discussed earlier resinous efforts are needed because every approach facer some or other drawback. The figure below represent support vector machine approach implemented in this paper: | ||||||||||||
| Where x and y are various categories on which the data instances are separated. So the motivation to conduct this experiment is to increase the overall accuracy, address word sense disambiguation by considering some classifier, which will train the database and identify meaning of word correctly out of total list of meanings which are provided. This task is carried out by referring the context to resolve disambiguation. | ||||||||||||
EXPERIMENTAL SETUP |
||||||||||||
Data |
||||||||||||
| Experiment is conducted by using a WordNet repository, 10 nouns and 5 verbs[7]. To know the accuracy of sense context is designed by following senseval norms. This representation is made by using XML representation. With the help of algorithm and context mentioned in a database meaning of word is calculated. To accomplish this task semistructured and unstructured representation is used, because of the latency; that is the required to store and retrieve the data to and from database[8]. | ||||||||||||
Implementation Supervised Machine Learning Techniques |
||||||||||||
| To identify meaning of word two types of techniques used, Supervised, unsupervised techniques. If a data is identified on the best is of frequency of occurrence then it is unsupervised approach; But all the time we cannot completely relay on unsupervised approach, because meaning could very as per the context used and perception. Supervised technique, because system is trained with some defined context to predict meaning based on the surrounding word. Their predictions are maide with suitable data mining algorithm like, Naïve Bayes, Decision tree algorithm, Decision List algorithm, and Support vector machine. These algorithms are munitions and empirically implemented in this paper, and the comparative analysis based on the accuracy of that algorithms to predict the meaning. | ||||||||||||
Naïve Bayes |
||||||||||||
| Naïve Bayes approach works on conditional probability. In some approaches it gives better result while in other approaches it does not deliver appropriate results. | ||||||||||||
| There are few scores where Naïve bayes provide better result and these top 3 results according to the accuracy are: {Name: 1000, worlds: 1000, Day: 1000}. | ||||||||||||
| In some cases performance of Naïve Bayes algorithm is not satisfactory lowest three such cases are: {Worship: 414, Trust: 167, Help: 414} | ||||||||||||
| Overall accuracy of Naïve Bayes algorithm is (58.32 %) which need to be improved to find but desired word correctly [9]. | ||||||||||||
Decision Tree |
||||||||||||
| Decision tree is based on storage of result or meaning at node. As far as WSD is concerned for data set that we are referring overall accuracy of decision tree is not satisfactory. | ||||||||||||
| Overall accuracy is (45.14%). | ||||||||||||
| Though overall accuracy of decision tree is not up to the mark but for few cases it gives better results, such top 2 cases are: {Name: 1000, Worlds:1000}. On this contrary, there are some result its where performance is not satisfactory such lowest three cases are: {Trust: 167, Day: 109, Help: 125}[10]. | ||||||||||||
Decision List |
||||||||||||
| Among the approaches discussed, so for decision list provides more accurate result by forming if else ladder. The efficiency and accuracy would be noted by few cases where results are better are mentioned below: {Praise: 1000, Name: 1000, Worlds: 1000, Lord: 1000, Recompense: 1000, Day: 1000}. | ||||||||||||
| Though overall accuracy is better in case of decision list there are some cases where the performance is not according to the expectation is not satisfactory are as below: | ||||||||||||
| {Trust: 167, Help: 125, Favored: 250, Path: 333}[11]. | ||||||||||||
Support Vector Machine |
||||||||||||
| Support vector machine is a technique to separate a data in a hyperspace with the help of hyperplane. This separation is done creating hyperplane by maximizing the distance between the data instances which are located at the edge. If we observer working of SVM carefully it is observed that it is practically difficult to sprat data instances clearly, so this gap is known as slack. This slack is to be maximized to separate data instances and categorize them under one heading. Support vector machine is an idea example of binary classifier but when it comes to word sense disambiguation performance or the results are not up to the mark. | ||||||||||||
| Such top 4 “four cases” where results are at pick are mentioned below: | ||||||||||||
| {Name: 1000, Worlds: 1000, Guide: 1000, Day: 1000}. | ||||||||||||
| In some cases performance of Support vector machine algorithm is not satisfactory lowest three such cases are: {Worship: 414, Lord: 431, Trust, 167, Path: 318, Favored: 250 Help: 125}[12]. | ||||||||||||
THE RESULTS |
||||||||||||
| Disambiguation is performed in this paper via a four supervised approaches, using WordNet and Senseval-3. Table (1), shows the results of four approaches, Naïve Bayes, Decision tree,, Decision List, and Support vector machine, which’s has been given based on their score and accuracy.ich shows a comparative of those different approaches has been given based on their score and accuracy. | ||||||||||||
CONCLUSION |
||||||||||||
| We have presented a comparative study for four supervised learning machine algorithms, using WordNet, and Senseval-3, table (2), below shows the final results and accuracy for each approach. In conclusion, Decision List algorithm, obtained high accuracy. | ||||||||||||
ACKNOWLEDGMENT |
||||||||||||
| I’m grateful to my research guide respected Dr. Shashank Joshi (Professor at Bharati Vidyapeeth University, College of Engineering) for his support and cooperation all the time. | ||||||||||||
Tables at a glance |
||||||||||||
|
||||||||||||
Figures at a glance |
||||||||||||
|
||||||||||||
References |
||||||||||||
|





