International Journal of Advanced Research in Electrical, Electronics and Instrumentation Engineering
ISSN ONLINE(2278-8875) PRINT (2320-3765)
ISSN ONLINE(2278-8875) PRINT (2320-3765)
Abhilash surendran1 and Lekshmi M.S2
|
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Advanced Research in Electrical, Electronics and Instrumentation Engineering
The process of Single channel speech separation is done to efficiently separate the required speech signals from a mixture. In this research paper we used WPST (Wavelet Packet Based Sub-band Transform) to offer a multi resolution property of wavelet transform to increase the efficiency by reducing the number of coefficients required in each sub-band vector to replace the previously used SPWT (Sub-band perceptually weighted transformation).The new approach improves the separation quality and it results lowest error bound in terms of objective measurements such as Perceptual Evaluation of Speech Quality (PESQ)),segmented SNR in comparison with SPWT based features.
Keywords |
| Single channel speech separation (SCSS), Wavelet Packet Based Sub-band Transform (WPST), Vector quantization (VQ), Objective measurements. |
INTRODUCTION |
| The single channel speech separation (SCSS) one of challenging scenarios in the case of audio processing and telecommunication field. The separation of audio signal is essential in the case of automatic speech recognition process (ASR). There are many kinds of noises that may interfere the speech signal such as speech babble, background noise, colored noise and white noise, among which the competing speech is the main interference to the speech signal of interest and the removal of such noise is most challenging process due to the high correlation between the temporal structures of target speech and the speakers which mask it. Which results poor separation quality. |
| In the common life of a human the interference due to the competing speech is a normal one and the humans have the ability to recognize and separate out the required speech. But while doing the same task by a machine, like computer it becomes very difficult task. Recently many researches are going on for the separation of two speech signals received from one communication channel which is called as single channel speech separation (SCSS). |
| There are many kind of applications for this single channel speech separation and it can be used as a pre-processing stage for certain systems such as Speech coding, hearing aids and automatic speaker recognition systems. It improves the robustness of all the above processes because it effectively separates out the required signals |
| The single channel speech separation processes are generally of two main classifications that are source driven and model driven. In the source driven methods the required speech signals of interest are extracted from the mixed signal without a prior knowledge about the underlying speakers. The computational auditory scene analysis (CASA) is the most known source driven approaches used now a days. It performs speech separation by extracting psychoacoustic cues from the given mixed signals. It has dis-advantages such as it is highly affected by the poor accuracy of the multi-pitch tracking algorithm estimates of the speech signals obtained from the mixed signal. And the outputs have poor perceptual quality due to crosstalk problem |
| The next type of SCSS technique is model driven in which the speech separation is carried out with the help of pre-defined speaker models in the form of codebooks. In this paper the model driven technique is followed which contains mainly three processes such as 1) Feature selection, 2) Modelling, and 3). Estimation. Accordingly based on the feature selection, Model and estimation many types of model-based single channel speech separation techniques have been proposed. The model based separation scenarios completely depends on prior knowledge about the underlying speakers called speaker models. The techniques such as Vector quantization (VQ), Gaussian Mixture model (GMM), Hidden Markov model (HMM) used to get the restrictive constraints for preparing speaker models.In this paper the new transform called WPST (Wavelet Packet Based Sub-band Transform) is detailed that was utilized for VQ-based SCSS which have larger separation quality and good separation performance even at low SSR’s. It have multi resolution property and can be associated with the perceptual model of human ear |
RELATED WORKS |
| In the single channel speech separation (SCSS) process as discussed before many types of transformations are used in order to obtain the feature vectors of underlying speakers in a mixed form of speech, in previous works the authors followed to use the code vectors obtained from the Short term Fourier Transform (STFT). And vector quantization designs to cope up with poor signal quality. Later the Sub-band perceptually weighted transformation (SPWT) [1] is used to improve the separation efficiency. |
| In order to obtain the new feature parameters, the each STFT magnitude spectrum code vectors are normalized to its maximum value then the logarithm of normalized vectors have been taken. This reduced the dynamic range of code vectors hence improved the quality. And a signal distortion (SD) measurement is taken as a performance index. Since the SPWT depends on STFT parameters it assumes the signal to be stationary for a fixed frame period and this provides only a fixed time frequency resolution. And the SPWT does not considers the critical bands of human ear because in order to consider the critical bands it requires high frequency resolution, resulting low time resolution. Which will result long time for code book preparation. Hence it requires a new transform which supports multi resolution, which matches perceptual model of human ear. As a solution we can make use of wavelets to solve this problem. |
WAVELET PACKET BASED SPEECH SEPARATION |
| The wavelet is nothing but an oscillation like wave which has an amplitude starts at zero and increases and then decreases back to zero. The wavelets can be molded to have specific properties that make them useful for speech processing. Wavelet Transformis of various types Continuous and discrete wavelet transforms and wavelet packet transform,out of these we make use of the last one called WPT (wavelet packet transform), where the discrete-time (sampled) signal is passed through more filtersthan the discrete wavelet transform The advantage of this method is to get more desirable sub-bands and minimal effective representations of the signal.The wavelet packet transform (WPT) generalizes the wavelet transform and provides a more flexible tool for the time-scale analysis of the data. |
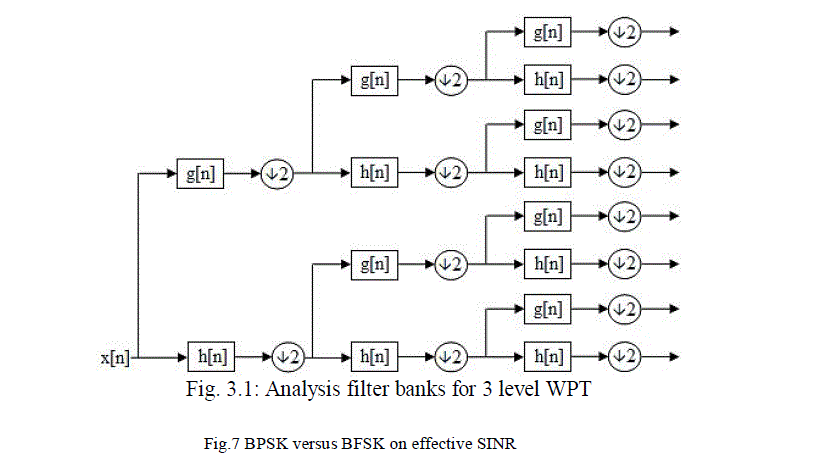 |
| In wavelet packet analysis a split on detail coefficients lead to change in basis set and these basis sets are called wavelet packets. In the previous figure, there are 8 leaves. Coefficients from these leaves are associated with 8 different functions (basis). The functions associated with first two (from bottom) are scaling and wavelet functions as in the case of normal W T. All others are basis functions derived from wavelet function. The main advantage of Wavelet Packet Transform is the availability of different basis functions other than scaling and wavelet functions. So taking proper set of basis the signal can be analyzed with minimum number of coefficients (taking best basis), or with proper sub-bands having required band widths. Wavelet packet decomposition has been recognized as a powerful tool for audio processing applications partly, because the wavelet packet decomposition can be designed to closely approximate the critical bands. The wavelet packet transform has an excellent property that it can be used for analyzing a signal in different time-frequency resolutions. It enables the signal to be analyzed in various sub-bands available, out of which the proper sub-bands can be chosen for our particular needs. This analysis based on sub-bands is now commonly used for audio signal processing and generating perceptual model of audio signals. |
| The human ear analyses an audio signals in various sub-bands called the critical bands. The critical bands have various sub-bands within the frequency of audibility limit (20 Hz to 20 KHz). And this variable time frequency analysis requires less number of coefficients compared to previous SPWT features. |
| A. Wavelet packet based sub-band transformation (WPST) |
| Considering the critical bands of human ear and the advantages of using the wavelet packets in sub-band analysis of audio signals, a Wavelet packet tree structure is proposed in order that it closely matches those critical bands, here the high frequency components are analyzed using a narrow window and the low frequency components are analyzed using a wider window. Hence the transform vectors from the proposed WPT tree structure can give a good performance in the case of model based SCSS.. This new vector obtained from wavelet transformation can be called as Wavelet packet based sub-band transformation (WPST). Since out of various wavelets available the Daubechies Wavelet Type 4 (Db4) is used here since its sub-bands closely matches the critical bands. And the Db4 wavelets are commonly used for audio signal analysis. |
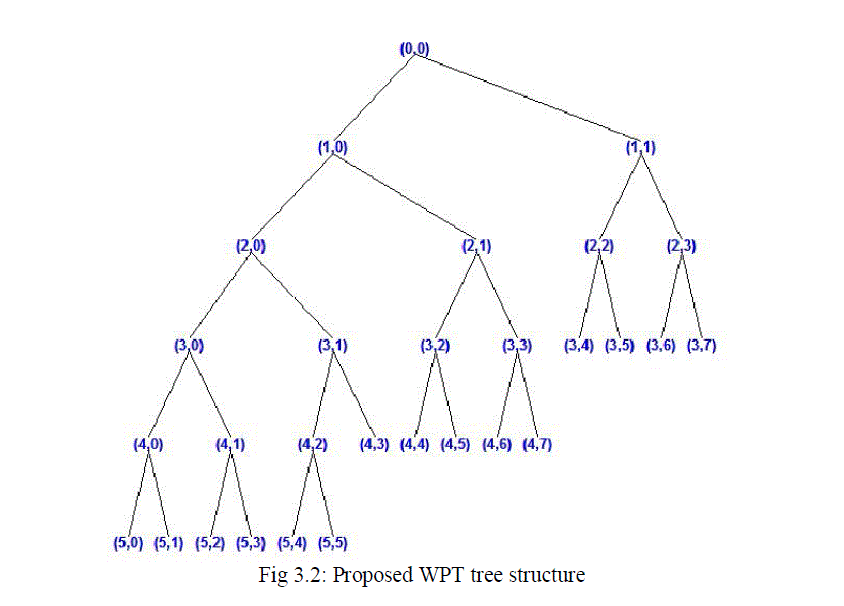 |
| In order to obtain the new feature parameters, first the Db4 wavelet packet tree is taken such that its sub-bands closely matches the critical bands of human ear. Then each sub-band coefficients are concatenated to obtain a single vector (Sj). |
| Then these sub-band coefficients are normalized by dividing the energy in each sub-band. This results a parameter ranging [0, 1]. This normalized format results better classification accuracy. |
| B. WPST based separation scenario |
| In this technique the wavelet packet transform is used to get the sub-bands which are very closer to the critical bands of human ear. In order to obtain the new feature vector 15 sub-band vectors are chosen from the wavelet tree that are (5,0),(5,1)…..(5,5),(4,0),(4,1)…..(4,5),(3,0),(3,1)…..(3,5). And all these vectors are concatenated to obtain the single vector Sj. |
| The main idea behind is to create a code-book for the required speaker to be separated from the monaural speech signal Similar to the initial stage of separation in SPWT based work [1] here also the initial stage is code book creation. In order to create the code books the 10 sentences for each speaker from the TIMIT database were taken. Since the signals have a frequency 16 KHz, it is down sampled to 8 KHz. The code book contains WPST vectors obtained from the wavelet tree structure. Before creating the code books the vectors are normalized. However the usage of wavelet transform avoids the problems due to non-stationarity of the signal. So here a frame of 128ms is used to prepare WPST vectors this enables us to use the characteristics of speech extending beyond 32 ms .The frame size of 128 ms gives a vector of size 1024.The proposed WPT tree structure is applied to these frames and hence WPST vectors are obtained by concatenating the sub-bands of tree and normalizing it. |
| In-order to prepare the code-book LBG algorithm used in [1] SPWT is used. The codebook size is chosen to be as 1024. The performance of codebooks are evaluated by applying the test speech to the codebook of specific speaker. First the WPST is taken for the test speech and after that vector quantization is applied using the codebook of the speaker. For the separation process speech mixture is required, the mixed speech is formed by applying an acoustic transfer function to the individual speech signals and adding them in time domain (S1(n),S2(n)...). In the separation or extraction process the S1(n) is separated by comparing the WPST vectors of S1 with the WPST vectors of mixed signals. And taking closely matching vectors from code book of speaker 1. To find the close matches the Euclidian distance function is used. Instead of using 256 coefficients (32 ms window), selecting wider window (for eg.128 ms) is followed here. For the sub-bands below 750 HZ the band width chosen is 100 Hz, for sub-bands from 750 Hz to 2000 Hz a bandwidth of 200 Hz is used, and so on 15 sub-bands are used for the analysis. For each 128 ms duration we get 128 coefficients much smaller compared to 1024 length used in previous SPWT based method. |
RESULTS |
| The measurement of speech quality is done for obtaining the evaluation of performance of WPST based system. For that an objective measurement is carried out. It is generally calculated between the original speech signal and the distorted speech signal using some mathematical analysis. It is very simple process that it does not require any human listeners and less time consuming. The commonly used objective measurements are segmented SNR, Weighted spectral slope distance measures (WSS), Perceptual Evaluation of Speech Quality (PESQ). Where the SNR is calculated in short frames and averaged hence it is called as segmented SNR |
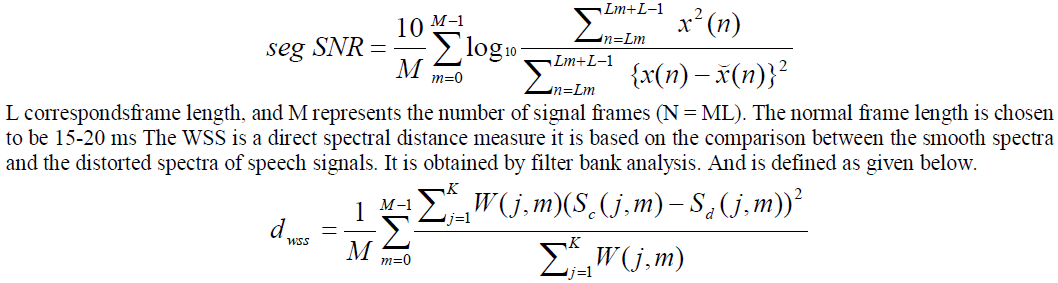 |
| Here the K is number of bands, M is the total frames, and Sc (j, m) and Sd (j, m) are spectral slopes of the jth band in the mth frame for respectively clean and distorted speech. The PESQ measure is the international standard for calculating the Mean Opinion Score (MOS). It is an officially standardized method used by ITU (International Telecommunication Union) it gives a score ranging from -0.5 to 4.5.The another objective measurement is Overall Quality it is obtained by linearly combining the PESQ, LLR, WSS measures |
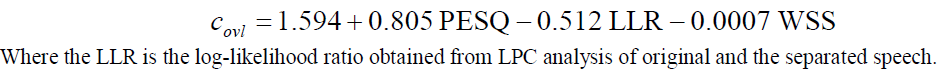 |
 |
 |
 |
 |
 |
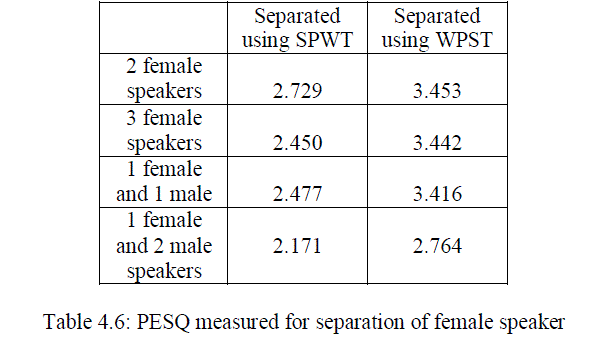 |
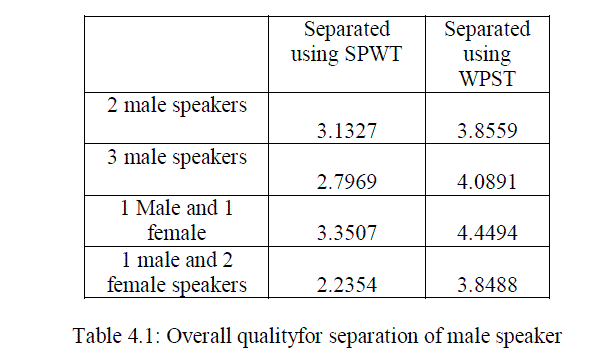
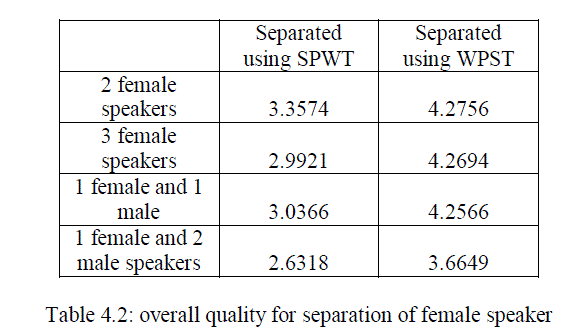
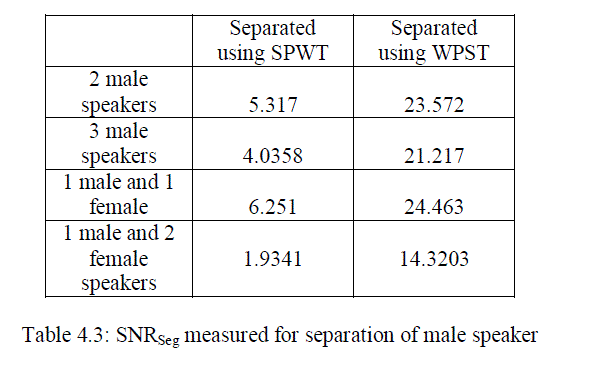
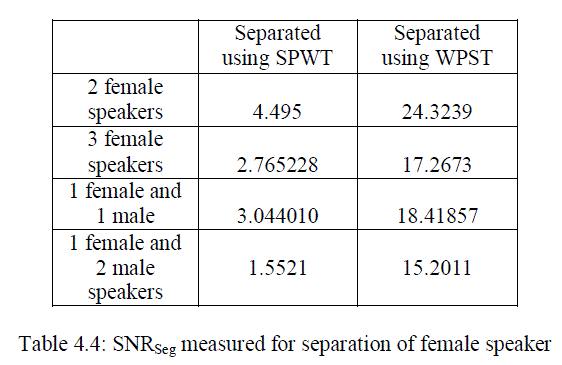
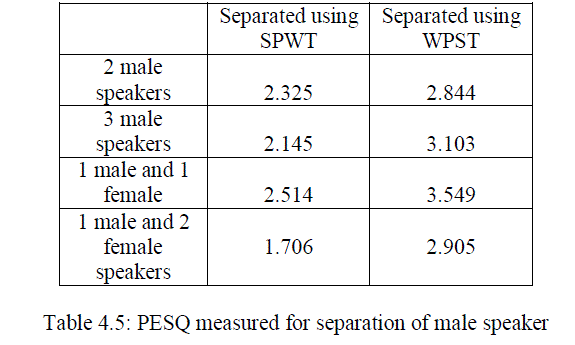
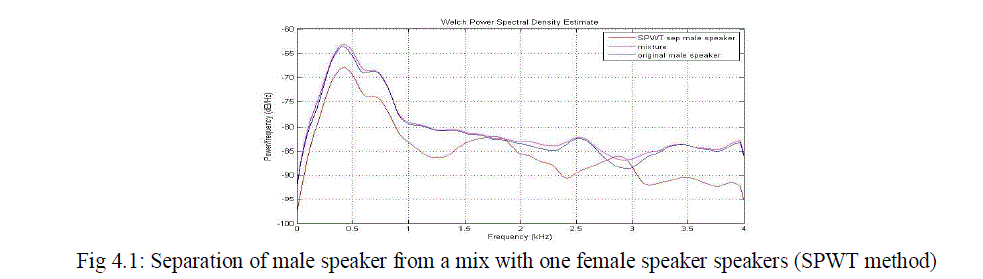
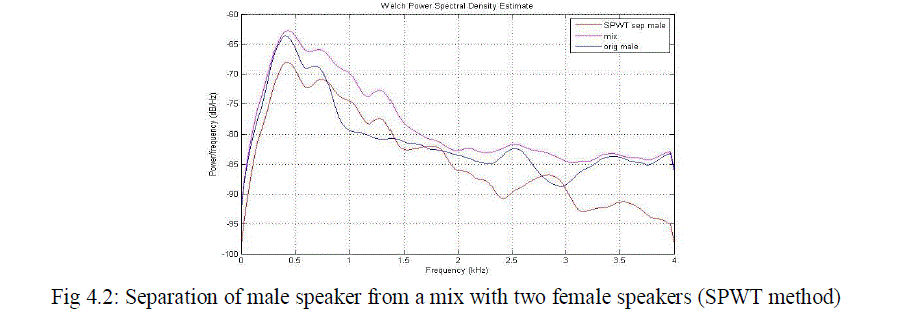
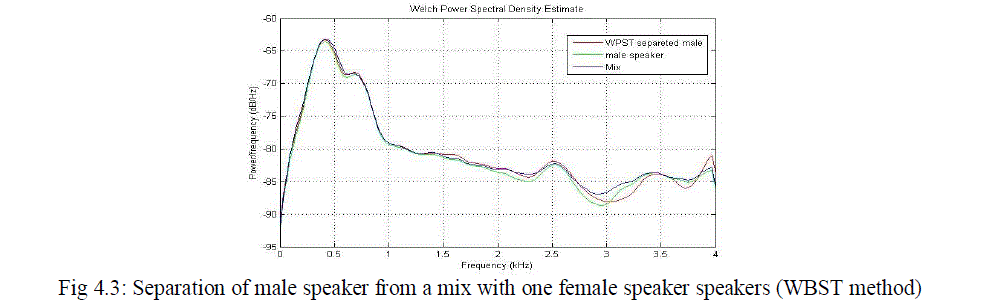
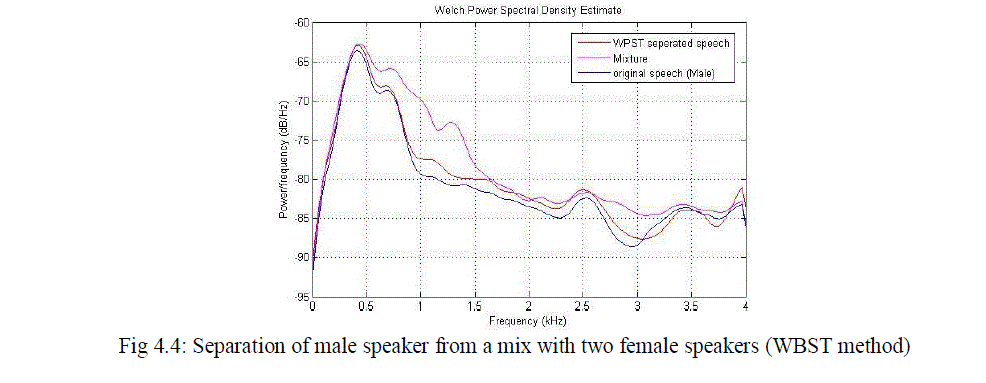
| From the results observed from various measurements given above in the table clearly we can identify that the WPST based method is more advantageous than the previously used SPWT based method. The proposed system improves the overall performance and PESQ values. There is a large improvement in the case of segmented SNR. The power spectral density plots of various combinations of speakers in the mixture is given below. From the PSD plot also we can clearly identify the improvement of quality while using the new feature parameter. |
 |
 |
 |
 |
CONCLUSION |
| The separation of speech signal from a single microphone recorded mixture is a challenging scenario in this paper a VQ based approach for single channel speech separation is presented. In the previous works a SPWT (based on STFT features) transformation is used to obtain the feature vector for separation. Due to the limited resolution of this features, it is found difficult to approximate this with the perceptual model of human ear, so we gone for a new transformation supporting multi resolution analysis called Wavelet packet based sub-band transformation (WPST). And this new feature vectors improved the quality of SCSS system. |
References |
|