Keywords
|
| Face recognition, Multiple Sample per Person (MSPP), Bilateral Filter, Block Segmentation, Locality Repulsion Projections (LRP), Histograms, GMM Classification |
INTRODUCTION
|
| “A facial recognition system is a real-time operation for automatically identifying or verifying a person from a digital image or a video frame from a digital camera.” Basically, facial recognition technology attempts to identify people’s faces by comparing facial features in photographs. The recognition is a very complex task for the face recognition without a concrete explanation. We can recognize thousands of faces learned throughout our lives and identify familiar faces at first sight even after several years of separation. For this reason, the Face Recognition is an active field of research which has different applications. There are several reasons for the recent increased interest in face recognition, including rising public concern for security, the need for identity verification in the digital world and the need for face analysis and modelling techniques in multimedia data management and computer entertainment. Face verification is a task of active research with many applications from the 80’s. It is perhaps the biometric method easier to understand and non-invasive systems because for us the face is the most direct way to identify people and because the data acquisition methods consist basically on to take a picture. |
Structure of Face recognition System
|
| The main purpose of proposed algorithm is to replace multiple samples per person instead of using single sample per person. The algorithm used in proposed system is not just related to replacement the samples the person for face recognition but also to remove the noise in preprocessing and in classification phase. It consists two phases namely training phase and testing phase. |
RELATED WORK
|
| In [2] paper presents a novel subspace method called sequential row–column independent component analysis (RCICA) for face recognition. Unlike the traditional ICA, in which the face image is transformed into a vector before calculating the independent components (ICs), RC-ICA consists of two sequential stages an image row-ICA followed by a column-ICA. There is no image-to-vector transformation in both the stages and the ICs are computed directly in the sub space spanned by the row or column vectors. RC- ICA can reduce the face recognition error caused by the dilemma in traditional ICA. In [3] linear representation based face recognition (FR), it is expected that a discriminative dictionary can be learned from the training samples so that the query sample can be better represented for classification. On the other hand, dimensionality reduction is also an important issue for FR. It can not only reduce significantly the storage space of face images, but also enhance the discrimination of face feature. Existing methods mostly perform dimensionality reduction and dictionary learning separately, which may not fully exploit the discriminative information in the training samples. In this paper, we propose to learn jointly the projection matrix for dimensionality reduction and the discriminative dictionary for face representation. The joint learning makes the learned projection and dictionary better fit with each other so that a more effective face classification can be obtained. The proposed algorithm is evaluated on benchmark face databases in comparison with existing linear representation based methods, and the results show that the joint learning improves the FR rate, particularly when the number of training samples per class is small. In [4] Local directional pattern descriptor and two-dimensional principal analysis algorithms to achieve enhanced recognition accuracy. This paper aimed to improve face recognition accuracy under illumination-variant environments by using the LDP image and 2D-PCA algorithm. The LDP image is derived from the edge response values in different eight directions Next, the LDP image is directly inputted in 2D-PCA algorithm and nearest neighbor classifier is applied to recognize unknown user. In [5] Robust face recognition (FR) is an active topic in computer vision and biometrics, while face occlusion is one of the most challenging problems for robust FR. Recently, the representation (or coding) based FR schemes with sparse coding coefficients and coding residual have demonstrated good robustness to face occlusion; however, the high complexity of l1-minimization makes them less useful in practical applications. In this paper we propose a novel coding residual map learning scheme for fast and robust FR based on the fact that occluded pixels usually have higher coding residuals when representing an occluded face image over the nonoccluded training samples. |
EXISTING AND PROPOSED SYSTEM
|
EXISTING SYSTEM
|
| Theoretically, demixing by the two matrices will not make the output face features completely independent. We have to find a better transformation than RC-ICA, which can preserve the advantages of RC-ICA while make the face features be more independent. This will be our future research work.The SRC classifier shows very competitive performance, but its performance will drop much when the training samples per class are insufficient. It is also claimed in [6] that dimensionality reduction is no longer critical in the SRC scheme and random projection can achieve similar results to PCA and LDA when the dimensionality is high enough. Nonetheless, if a lower dimensionality is required, PCA and LDA will have clear advantage over random projection when the dimensionality is large enough, JDDLDR could also outperform LDA+CRC/SRC. With setting the significance level as 10%, we get H=1 in all cases, validating that JDDLDR significantly outperforms all the other methods in all cases. |
PROPOSED SYSTEM
|
Capture
|
| This stage is simple because it only needs a video input device to take the face image to be processed. Due to this is not necessary to have a camera with special features, currently cell phones have a camera with high resolution which would serve or a conventional camera would be more than enough because the image can be pre-processed prior to extract the image features. Obviously, if the camera has a better resolution can be obtained clearer images for processing. |
Pre-processing
|
| In this stage basically apply some kind of cutting, filtering, or some method of image processing such as noise removal, segmentation, histogram equalization or histogram specification, among others. This is to get a better image for processing by eliminating information that is not useful in the case of cutting or improving the quality of the image as equalization. The pre-processing of the image is very important because with this is intended to improve the quality of the images making the system more robust for different scenarios such as lighting changes, possibly noise caused by background, among others. |
Feature extraction
|
| The feature extraction stage is one of the most important stages in the recognition systems because at this stage are extracted facial features in correct shape and size to give a good representation of the characteristic information of the person, that will serve to have a good training of the classification models. Today exists great diversity of feature extraction algorithms, the following are listed some of them: |
| • Fisherfaces (Alvarado et al., 2006). |
| • Eigenfaces(Alvarado et al., 2006). |
| • DiscreteWalsh Transform (Yoshida et al., 2003). |
| • Gabor Filters (Olivares et al., 2007). |
| • DiscreteWavelet Transform (Bai-Ling et al., 2004). |
Classifiers
|
| The goal of a classifier is to assign a name to a set of data for a particular object or entity. It defines a set of training as a set of elements, each being formed by a sequence of data for a specific object. A classifier is an algorithm to define a model for each class (object specific), so that the class to which it belongs an element can be calculated from the data values that define the object. Therefore, more practical goal for a classifier is to assign of most accurate form to new elements not previously studied a class. Usually also considered a test set that allows measure the accuracy of the model. The class of each set of test is known and is used to validate the model. Currently there are different ways of learning for classifiers among which are the supervised and unsupervised. |
Classifiers Types
|
| Different types of classifiers that can be used for a recognition system in order to choose one of these classifiers depends on the application will be used, it is very important to take in mind the selection of the classifier because this will depend the results of the system. The following describes some of the different types of classifiers exist. |
| Nearest Neighbor. In the nearest-neighbor classification a local decision rule is constructed using the k data points nearest the estimation point. The k-nearest-neighbors decision rule classifies an object based on the class of the k data points nearest to the estimation point x0. The output is given by the class with the most representative within the k nearest neighbors. Nearness is most commonly measured using the Euclidean distance metric in x-space (Davies E. R., 1997; Vladimir & Filip, 1998). |
| Bayes’ decision. Bayesian decision theory is a fundamental statistical approach to the problem of pattern recognition. This approach is based on quantifying the tradeoffs between various classification decisions using probability and the costs that accompany such decisions. It makes the assumption that the decision problem is posed in probabilistic terms, and that all of the relevant probability values are known (Duda et al., 2001). |
| Neural Networks. Artificial neural networks are an attempt at modeling the information processing capabilities of nervous systems. Some parameters modify the capabilities of the network and it is our task to find the best combination for the solution of a given problem. The adjustment of the parameters will be done through a learning algorithm, i.e.,not through explicit programming but through an automatic adaptive method (Rojas R.,1996). |
| Gaussian Mixture Model. A Gaussian Mixture Model (GMM) is a parametric probability density function represented as a weighted sum of Gaussian component densities. GMMs are commonly used as a parametric model of the probability distribution of continuous measurements or features in a biometric system, such as vocal-tract related spectral features in a speaker recognition system. GMM parameters are estimated from training data using the iterative Expectation-Maximization (EM) algorithm or Maximum A Posteriori MAP) estimation from a well-trained prior model (Reynolds D. A., 2008). |
| Support Vector Machine. The Support Vector Machine (SVM) is a universal constructive learning procedure based on the statistical learning theory. The term “universal” means that the SVM can be used to learn a variety of representations, such as neural net (with the usual sigmoid activation), radial basis function, splines, and polynomial estimators. In more general sense the SVM provides a new form of parameterization of functions, and hence it can be applied outside predictive learning as well (Vladimir & Filip, 1998). |
| In This chapter presents only two classifiers, the Gaussian Mixture Model (GMM) and Support Vector Machine (SVM) as it classifiers are two of the most frequently used on different pattern recognition systems, and then a detailed explanation and evaluation of the operation of these classifier is required. |
GAUSSIAN MIXTURE MODEL
|
| Gaussian Mixture Models can be used to represent probability density functions complex, from the marginalization of joint distribution between observed variables and hidden variables. Gaussian mixture model is based on the fact that a significant number of probability distributions can be approximated by a weighted sum of Gaussian functions as shown in Fig. 2. Use of this classifier has excelled in the speaker’s recognition with very good results (Reynolds & Rose, 1995; Reynolds D. A., 2008). |
| Gaussian Mixture model mainly used for Classification in our proposed method to recognize the multi model image features and it is used to find out the mean and covariance factor |
| To carry out the development of Gaussian Mixture Model must consider 3 very important operations: |
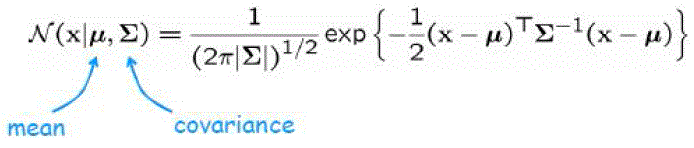 |
| Data set |
| D={X n} n=1 , . . . , N |
| Assume observed data points generated independently |
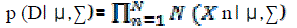 |
| Viewed as the function of the parameters, this is known as the likelihood function |
| Maximum Likelihood Function |
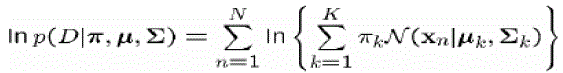 |
EVALUATION RESULTS
|
| Here are some results with both classifiers, GMM and SVM combined with some feature extraction methods mentioned above, like Gabor, Wavelet and Eigen phases. The results shown were performed using the database “The AR Face Database”(Martinez, 1998) is used, which has a total of 9, 360 face images of 120 people (65 men and 55 women) that includes face images with several different illuminations, facial expression and partial occluded face images with sunglasses and scarf. Two different training set are used, the first one consists on images without occlusion, in which only illumination and expressions variations are included. On the other hand the second image set consists of images with and without occlusions, as well as illumination and expressions variations. Here the occlusions are a result of using sunglasses and scarf. These images sets and the remaining images of the AR face database are used for testing. Tables 1 and 2 shows the recognition performance using the GMM as a classifier. The recognition performance obtained using the Gabor filters-based, the wavelet transform-based and Eigen-phases features extraction methods are shown form comparison. Table 1 shows that when the training set 1 is used for training, with a GMM as classifier, the identification performance decrease in comparison with the performance obtained using the training set 2. This is because the training set 1 consists only of images without occlusion and then system cannot identify several images with occlusion due to the lack of information about the occlusion effects. However when the training set 2 is used the performance of all of them increase, because the identification system already have information about the occlusion effects. |
CONCLUSION AND FUTURE WORK
|
| `The Experimental results showed that the proposed algorithm performs better with the face recognition using multi model image features and produce effective classification result with the help of GMM Classifier. The proposed algorithm provides efficient noise removal result in first module. Different kinds of databases used for matching the segmented image as well as classified result image in testing phase. The performance of the proposed algorithm can be compared with other Face recognition algorithms. SVM uses a supervised training algorithm and then it requires less training patterns to estimate a good model of the person under analysis.GMM is uses a non-supervised training algorithm, it requires a larger number of training patterns to achieve a good estimation of the person under analysis and then its convergence is slower that those of SVM, however the GMM estimated the model of each person independently of that of the other persons in the database. It is a very important feature when large number of persons must be identified and the number of persons grows with the time because, using the GMM, when a new person is added, only the model of the new person must be added, remaining unchanged the previously estimated ones. Thus the GMM is suitable for applications when large databases must be handed and they change with the time, as in real time face recognition operations. |
Tables at a glance
|
 |
|
| Table 1 |
Table 2 |
|
Figures at a glance
|
 |
 |
 |
 |
| Figure 1 |
Figure 2 |
Figure 3 |
Figure 4 |
|
References
|
- Dong-Ju Kim., Sang-Heon Lee and Myoung-KyuSohn.,” Face Recognition via Local Directional Pattern”, International Journal of Security and ItsApplications Vol. 7, No. 2, March, 2013.
- Z.Z. Feng, M. Yang, L. Zhang, Y. Liu, and D. Zhang, Joint Discriminative Dimensionality Reduction and Dictionary Learning for FaceRecognition, Pattern Recognition, 46(8):2134-2143, 2013.
- QuanxueGao., LeiZhang., DavidZhang., “Sequential row–column independent component analysis for face recognition “, Neuro computing 72 (2009) 1152– 1159.
- M. Yang, L. Zhang, X. Feng, D. Zhang,” Fisher discrimination dictionary learning for sparse representation, in: Proceedings of the ICCV, 2011.
- L. Zhang, M. Yang, Z. Feng, D. Zhang, On the dimensionality reduction for sparse representation based face recognition, in: Proceeding of theICPR, 2010.
- S. Gao, I. Tsang, L. Chia, Kernel sparse representation for image classification and face recognition. In ECCV 2010.
- J. H. Wang, J. You, Q. Li, and Y. Xu. Orthogonal discriminant vector for face recognition across pose.Pattern Recognition, 45(12): 4069-4079, 2012.
|