International Journal of Innovative Research in Science, Engineering and Technology
ISSN ONLINE(2319-8753)PRINT(2347-6710)
ISSN ONLINE(2319-8753)PRINT(2347-6710)
Rajesh.S1 and Kanniga Devi.R2
|
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Innovative Research in Science, Engineering and Technology
Cloud Computing is a style of Computing where service is provided across the internet using different models. Fault tolerance is a major concern to guarantee availability and reliability of critical services as well as application execution. In this project work, we propose a model to analyze how system tolerates the faults and make decision on the basics of reliability of the processing nodes, i.e. Virtual machines. If a virtual machine manages to produce a correct result within the time limit, its reliability increases, and if it fails to produce the result within time or correct result, its reliability decreases. If the node continues to fail, it is removed, and a new node is added. There is also a minimum reliability level. If any processing node does not achieve that level, the system will perform backward recovery or safety measures. The proposed technique is based on the execution of design diverse variants on multiple virtual machines, and assigning reliability to the results produced by variants. The virtual machine instances can be of same type or of different types. The system provides both the forward and backward recovery mechanism, but main focus is on forward recovery
Keywords |
| cloud computing, virtual machine, fault tolerance, reliability |
INTRODUCTION |
| Cloud computing share the resources like physical services, storage, and networking. The cloud offers many services through cloud service providers. The most popular cloud service providers are Google, Amazon, windows Azure etc...Each service provider provides different services based on the demand of the users. For example Amazon provide IaaS service Google Provides all services like SaaS, PaaS and IaaS. The cloud computing is based on the distributed concepts and it is reliable to all users. This paper deals with the research field of fault tolerance in cloud. In a cloud environment there are many unknown nodes called Virtual machines (VM). Virtual machine (VM) is an operating system (OS) or program that can be installed and run virtually. In other words, VM is a processing machine in the server. In cloud computing, the user data is replicated in many VM’s. |
| The user request is passed onto all the available VM’s. If the particular VM fails then it will not respond and, all the other active VMs respond to the request. The fault tolerance measure available should identify the one reliable VM among all the VM’s and respond to the client request. This paper is used to identify the reliable VM. |
FAULT TOLEANCE AS A RESEARCH ISSUE |
| Fault tolerance is a major problem to guarantee availability and reliability of critical services as well as application execution. Fault tolerance serve as an effective means to address reliability concerns. Fault tolerance means that system should continue to operate under fault presence. |
| Cloud is vulnerable to a large number of system failures and the traditional fault tolerance approaches are less effective since cloud system’s architectural details are not widely available to the users because of the abstraction layers and business model of cloud computing. Fault tolerance that uses the Virtualization Technology (VT) can increase the reliability of applications, but VM migration and consolidations are difficult to achieve. |
| There are various faults which can occur in cloud computing .Based on fault tolerance policies various fault tolerance techniques[1] can be used that can either be task level or workflow level . |
| REACTIVE FAULT TOLERANCE: Reactive [1] fault tolerance policies reduce the effect of Failures on application execution when the failure effectively occurs. There are various techniques which are based on these policies like Checkpoint/Restart, Replay and Retry and so on. |
| PROACTIVE FAULT TOLERANCE: The principle of proactive [1] fault tolerance policies is to avoid recovery from faults, errors and failures by predicting them and proactively replace the suspected components by other working components. Some of the techniques which are based on these policies are Preemptive Migration, Software Rejuvenation etc. |
RELATED WORK |
| A lot of work has been done in the area of fault tolerance for standard cloud infrastructure. But there is lot of research room available in fault tolerance of virtual machine (VM) based cloud infrastructure. Cloud infrastructure has introduced some new issues related to Fault tolerance. These characteristics are different from the existing traditional techniques. |
| Huang et.al., [2] present Algorithm-Based Fault Tolerance (ABFT) method. ABFT uses matrix or vector level checksum in row and column to detect a faulty processor in multiple processor systems. The method can be used to detect and correct errors in matrix operations such as addition, multiplication, scalar product, and LU-decomposition performed in multiple processor systems which may have one failed processor. In their work, they focus on the problem of achieving a certain reliability with the minimum cost in potentially faulty clouds. |
| Wenbing Zhao et.al., [12] propose a FT middleware which implement a synchronized server replication strategy, where a failed server is repaired with a consistent state. |
| Alain Tchana et.al., [13] suggest a fault tolerance method collaborating cloud provider and cloud customer. Their integrated approach makes fault tolerance available in all levels of the cloud. However, they are not making use of VM checkpoint solutions to achieve optimum fault tolerance. |
| Z. Dai et.al., [3] suggest transparent check pointing at the user’s level provided by Distributed Multithreaded Check Pointing. By considering economic and dependability factors check points with various parameters are fixed. If these parameters are not satisfied, the thread is restarted. |
| X. Kong et.al., [5] presents a model for virtual infrastructure performance and fault tolerance. But it is not well suited for the fault tolerance of real time cloud applications. For the non-cloud applications, a baseline model for distributed RTS is, distributed recovery block proposed by K. H. Kim which is very basic in nature. |
| J. Coenen et.al., [6] propose model, âÃâ¬Ãâ¢A formal approach for the fault tolerance of distributed real time system (RTS)âÃâ¬Ãâ Traditionally, one of the backbones of software reliability is avoiding the faults. Since cloud architecture is very complex and built on data center comprising thousands of interconnected servers with capability of hosting a large number of applications and distributed globally, fault prevention techniques in developing stage is very tedious. Fault avoidance techniques or fault removal techniques such as testing to detect and remove fault, therefore, won’t be enough in the case of cloud computing. |
| S. Malik et.al., [18] propose model âÃâ¬Ãâ¢Time stamped fault tolerance of distributed RTSâÃâ¬Ãâ. This model incorporated the concept of time stamping with the outputs. All of these models were defined for the real time systems based on standard computing architecture. |
| Slawinska et.al., [14] proposes that in order to overcome VM failure, a Virtual Machine hook can be set to âÃâ¬Ãâ¢resubmitâÃâ¬Ãâ the failed VM. VM Crash is recovered by âÃâ¬Ãâ¢one VM restartâÃâ¬Ãâ functionality. Windows Azure offers Fault Tolerance management with the replicas of each VM and this solution is limited to the applications developed in the Windows Azure platform. VM failure of Amazon EC2 is take care by Simple Queue Service (SQS) and Amazon Machine Image (AMI). Service requests are queued up till they are executed properly, or deleted by the user with the help of SQS. In EC2 we can publish many Amazon Machine Images (AMI), on the failure of an AMI, we can easily replace it with the help of an API invocation. |
| H.Chen et.al., [15] proposes that the function of fault tolerance is to preserve the delivery of expected services despite the presence of fault-caused errors within the system itself. Errors are detected and corrected, and permanent faults are located and removed while the system continues to deliver acceptable service. This goal is accomplished by the use of error detection algorithms, fault diagnosis, recovery algorithms and spare resources. |
| Antonina Litvinova et.al., [7] use active replication techniques for web services, and propose a technique to gain byzantine fault tolerance using virtualization technology. Techniques to build efficient and fault tolerant applications for Amazon’s EC2 are provided in. Another approach using fault tolerance middleware which follows a leader/follower replication approach to tolerate crash faults has been proposed in. However, all these techniques have the limitations and either tolerate only a specific kind of fault or provide a single method to resilience. |
PROPOSED WORK |
| Our proposed model is based upon improving reliability assessment of virtual machines in cloud environment and fault tolerance of applications running on those VM’s. This fault tolerance has to be done on the basis of the reliability of virtual machines. The proposed method use two different set of nodes. One is the set of VM and other is adjudication node such as the main node (server). The Virtual machine uses acceptance test for its logical validity. The adjudicator node contains the time checker, reliability assessor and decision mechanism algorithms to find the reliable VM. The reliable VM is identified to process the client request. The client can accept the data from the VM in compressed form. A virtual machine is selected for computation on basis of maximum and minimum reliability. The node with maximum reliability is selected as the system event output. To provide the fault tolerance the data can be stored on multiple cloud using virtualization techniques. |
 |
| ACCEPTANCE TEST (AT): Acceptance Test (AT) module checks whether the fault will occur or not. Here the fault is a failure of VM or Host. The acceptance test can respond both success and failure case of the VM. If the VM has failed that VM is not considered. Even when the data within a VM gets corrupted it will not affect VM function so this VM considered by the TC. If result is success then it passes result to TC module. If the result is failure then it does not pass the result to TC module. To indicate the failure of result, AT sends a verify exception signal to TC. |
| TIME CHECKER (TC): Time checker is evaluated in milliseconds. The time is given as a lower bound time limit and the upper bound time limit. In our process the response time limit for each VM is given milliseconds. It must be monitored for every milliseconds. The VM can respond within the specified time limit, and that VM is taken as reliable then passed to RA (Reliability Assessor) module .TC module raises the signal of overtime which produce the result in deadline time. If all the nodes fail then TC module performs the recovery. |
| RELIABILITY ASSESSOR (RA): The RA module assesses the reliability for each virtual machine. The reliability is identified based on the main core module of the proposed system. As the proposed system tolerates the faults and makes the decision on the basis of the reliability of the processing nodes (i.e. virtual machine), the reliability of the virtual machine is improved, which changes after every computing cycle. In the beginning the reliability of each virtual machine is 100%. If a processing node manages to produce a correct result within the time limit, its reliability increases using a reliability Factor (RF), and if the processing node fails to produce the correct result or result within the time limit, its reliability decreases using adaptability factor n. The reliability assessment algorithm is more convergent towards failure conditions. In RA, the VM which responds above the time limit, is considered as failure VM. |
 |
| DECISION MECHANISM (DM): Identify the Reliable virtual machine based on Resource availability and previous history. |
| Resource Availability: Memory is considered as resource. The memory availability for each VM is considered separately. We apply the memory availability algorithm to find the lowest memory utilization VM and take that VM as reliable. |
| Previous History: It is a repository area to hold the checkpoints. At the end of each computing cycle DM makes checkpoint in it. In case of all node failure, backward recovery is performed with the help of checkpoints maintained in this Previous History. In our experiment we have done the communication induced checkpoint (CIC). The CIC perform the check pointing at the end of every cycle to maintain a global state. This scheme provides an automatic forward recovery. If a node fail to produce output or produce output after time overrun the system will not fail. It will continue to operate with remaining nodes. This mechanism will produce output until all the nodes fail. |
 |
| high. So this node tends to more node failures by failing to produce the results in time. The values of variables (RF, minReliability, maxReliability, SRL) depend on the applications. |
EXPERIMENTAL SETUP |
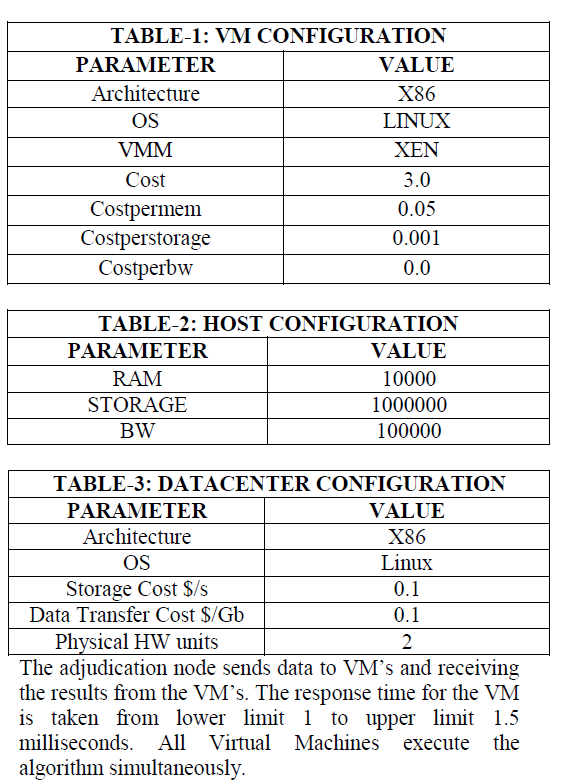
| We simulated our experiment using CloudSim. CloudSim [30] is a Cloud computing modeling and simulation tool that was developed in the University of Melbourne, Australia. It aims to provide Cloud computing re-searchers with a comprehensive experimental tool to conduct new research approaches. It supports the modeling and simulation of large scale Cloud computing environments, including power management, performance, data centers, computing nodes, resource provisioning, and virtual machine provisioning. We take 12 Virtual Machine in this experiment. The virtual machines are configured as follows: |
 |
RESULT |
| A metric analysis is given for the reliability assessment impact analysis. Here we have analyzed the reliability improved for Virtual Machine. We have assumed that the value of reliability factor (RF) is 2% (i.e. 0.02). Initially, the reliability is 1. Comparison is made between host and virtual Machine. This comparison is done for 15 Cloudlets 12 Virtual Machine and 12 Host. |
 |
CONCLUSION & FUTURE WORK |
| The proposed model is a good option to be used as a fault tolerance mechanism for real time computing on cloud infrastructure. It has all the advantages of forward recovery mechanism. It has a dynamic behavior of reliability configuration. The scheme is highly fault tolerant. The reason behind improve the reliability is that the scheme can take advantage of dynamic scalability of cloud infrastructure. This system takes the full advantage of using diverse software. In this experiment, we have used three virtual machines. It utilizes all of three virtual machines in parallel. This scheme has incorporated the concept of fault tolerance on the basis of VM algorithm reliability. Decision mechanism shows convergence towards the result of the algorithm which has highest reliability. Probability of failure is very less in our devised scheme. This scheme works for forward recovery until all the nodes fail to produce the result. The system change the reliability by providing the backward recovery at two levels. First backward recovery point is Time Checker. Here if all the nodes fail to produce the result, it performs backward recovery. Second backward recovery point is Decision mechanism. It performs the backward recovery if the node with best reliability could not achieve the System Reliability Level (SRL). There is another big advantage of this scheme. It does not suffer from domino effect as check pointing is made in the end when all the nodes have produced the result. The reliable VM identification technique used in this process is very efficient to improve the QOS of cloud. In future some enhancements to this model has to he done so that our system could be more fault-tolerant. |
References |
|