Keywords
|
| Text Mining, Extraction; Classification, Stemming; Stopword Removal; |
INTRODUCTION
|
| Data mining is the process of exploration and analysis, by automatic or semiautomatic means, of large quantities of data in order to discover meaningful patterns and rules. The goal of this advanced analysis process is to extract information from a data set and transform it into an understandable structure for further use. Data mining consists of three basic steps Extract the information, load the information & display the information (out-put). |
| Text mining is the technique that helps users to find useful information from a large amount of digital text documents on the Web or databases. It is therefore crucial that a good text mining model should retrieve the information that meets user’s needs within a relatively efficient time frame. |
| A first step toward any Web-based text mining effort would be to collect a significant number of Web mentions of a subject. Thus, the challenge becomes not only to find all the subject occurrences, but also to filter out just those that have the desired meaning. |
TEXT MINING AND INFORMATION EXTRACTION
|
| ?Text mining? is used to describe the application of data mining techniques to automated discovery of useful or interesting knowledge from unstructured data. |
| Unstructured data exists in two main categories: bitmap objects and textual objects. Bitmap objects are non-language based (e.g. image, audio, or video files) whereas textual objects are ?based on written or printed language? and predominantly include text documents.. Text mining is the discovery of previously unknown information or concepts from text files by automatically extracting information from several written resources using computer software [An evaluation of unstructured Text Mining software]. |
| Text mining on Web adoptive technique include classification, clustering, associate rule and sequence analysis etc.. Among them, classification is a kind of data analysis form, which can be used to gather and describe important data setIn Web text mining, the text extraction and the characteristic express of its extraction contents are the foundation of mining work, the text classification is the most important and basic mining method. |
A. Extraction
|
| In extraction process, required information is extracted by checking maximum text density from the text contents from a web page. By this process, noise from the web page is removed. Extraction is followed by pre-processing of the text content. Pre-processing of the text contents include stemming and stop word removal. |
B. Classification
|
| In classification process, required information classified on the basis of classifier to which belong to documents. |
GLOBAL INFORMATION
|
| Unlike the Term Count Model, Salton's Vector Space Model [1] incorporates local and global information. |
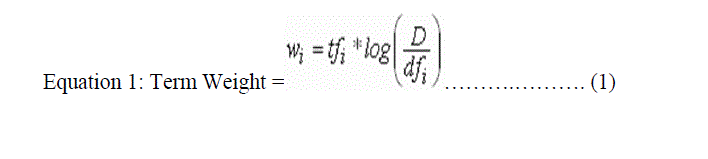 |
| where |
| tfi = term frequency (term counts) or number of times a term i occurs in a document. This accounts for local information. |
| ? dfi = document frequency or number of documents containing term i |
| ? D = number of documents in a database. |
| The dfi /D ratio is the probability of selecting a document containing a queried term from a collection of documents. This can be viewed as a global probability over the entire collection. Thus, the log(D/dfi) term is the inverse document frequency, IDFi and accounts for global information. The following figure illustrates the relationship between local and global frequencies in an ideal database collection consisting of five documents D1, D2, D3, D4, and D5. Only three documents contain the term "CAR". Querying the system for this term gives an IDF value of log(5/3) = 0.2218. |
| Those of us specialized in applied fractal geometry recognize the self-similar nature of this figure up to some scales. Note that collections consist of documents, documents consist of passages and passages consist of sentences. Thus, for a term i in a document j we can talk in terms of collection frequencies (Cf), term frequencies (tf), passage frequencies (Pf) and sentence frequencies (Sf). |
 |
| Equation 2(b) is implicit in Equation 1. Models that attempt to associate term weights with frequency values must take into consideration the scaling nature of relevancy. Certainly, the so-called "keyword density" ratio promoted by many search engine optimizers (SEOs) is not in this category. |
A. Vector Space Example
|
| To understand Equation 1, let use a trivial example. To simplify, let assume we deal with a basic term vector model in which we |
| 1. do not take into account WHERE the terms occur in documents. |
| 2. use all terms, including very common terms and stop words. |
| 3. do not reduce terms to root terms (stemming). |
| 4. use raw frequencies for terms and queries (unnormalized data). |
| I'm presenting the following example, courtesy of Professors David Grossman and OphirFrieder, from the Illinois Institute of Technology [2]. This is one of the best examples on term vector calculations available online. |
| ? By the way, Dr. Grossman and Dr. Frieder are the authors of the authority book Information Retrieval: Algorithms and Heuristics. Originally published in 1997, a new edition is available now through Amazon.com [3]. This is a must-read literature for graduate students, search engineers and search engine marketers. The book focuses on the real thing behind IR systems and search algorithms. |
| Suppose we query an IR system for the query "gold silver truck". The database collection consists of three documents (D = 3) with the following content |
| D1: "Shipment of gold damaged in a fire" |
| D2: "Delivery of silver arrived in a silver truck" |
| D3: "Shipment of gold arrived in a truck" |
| Retrieval results are summarized in the following Table 1. |
| The tabular data is based on Dr. Grossman's example. I have added the last four columns to illustrate all term weight calculations. Let's analyse the raw data, column by column. |
| 1. Columns 1 - 5: First, we construct an index of terms from the documents and determine the term counts tfi for the query and each document Dj. |
| 2. Columns 6 - 8: Second, we compute the document frequency di for each document. Since IDFi = log(D/dfi) and D = 3, this calculation is straightforward. |
| 3. Columns 9 - 12: Third, we take the tf*IDF products and compute the term weights. These columns can be viewed as a sparse matrix in which most entries are zero. |
| Now we treat weights as coordinates in the vector space, effectively representing documents and the query as vectors. To find out which document vector is closer to the query vector, we resource to the similarity analysis introduced in Part 2. |
B. Similarity Analysis
|
| First for each document and query, we compute all vector lengths (zero terms ignored). |
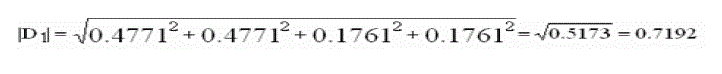 |
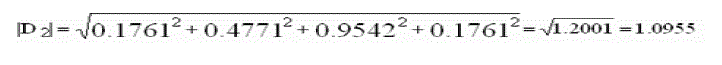 |
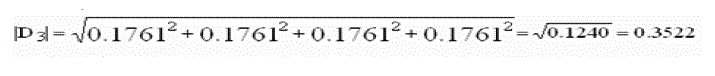 |
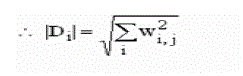 |
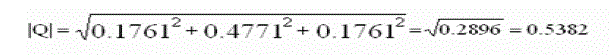 |
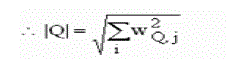 |
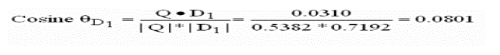 |
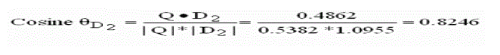 |
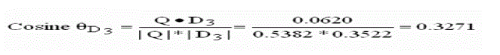 |
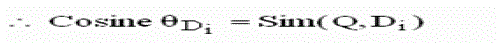 |
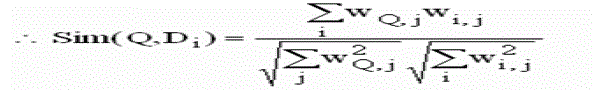 |
| Finally we sort and rank the documents in descending order according to the similarity values |
| Rank 1: Doc 2 = 0.8246 |
| Rank 2: Doc 3 = 0.3271 |
| Rank 3: Doc 1= 0.0801 |
C. Observations
|
| This example illustrates several facts. First, that very frequent terms such as "a", "in", and "of" tend to receive a low weight -a value of zero in this case. Thus, the model correctly predicts that very common terms, occurring in many documents in a collection are not good discriminators of relevancy. Note that this reasoning is based on global information; ie., the IDF term. Precisely, this is why this model is better than the term count model discussed in Part 2. Third, that instead of calculating individual vector lengths and dot products we can save computational time by applying directly the similarity function. |
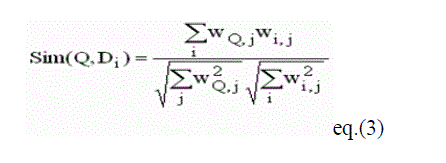 |
CONCLUSION AND FUTURE WORK
|
| By using computer, statistics, artificial intelligence we can try to present data in systematic way and that can be used for various purposes. In simple words data mining means discovering the undiscovered for effective decision making. The goal of this advanced analysis process is to extract information from a data set and transform it into an understandable structure for further use. Data mining consists of three basic steps Extract the information, load the information & display the information (out-put). |
Tables at a glance
|
 |
| Table 1 |
|
Figures at a glance
|
 |
 |
| Figure 1 |
Figure 2 |
|
References
|
- Shiqun Yin Gang Wang YuhuiQiuWeiqunZhang.Research and Implement of Classification Algorithm on Web TextMining.IEEE2007.
- Shiqun Yin Yuhui Qiu1,ChengwenZhong . Web InformationExtraction and Classification Method .IEEE 2007
- Shiqun Yin YuhuiQiuJikeGe, XiaohongLan.ResearchandRealization of Extraction Algorithm on Web Text Mining.IEEE2007.
- JaideepSrivastava, PrasannaDesikan, Vipin Kumar ?Web Mining— Concepts, Applications, and Research.
- Ms. Sarika Y. Pabalkar?Web Text Mining for news by Classification? IJARCCE Vol. 1, Issue 6, August 2012.
|