International Journal of Innovative Research in Science, Engineering and Technology
ISSN ONLINE(2319-8753)PRINT(2347-6710)
ISSN ONLINE(2319-8753)PRINT(2347-6710)
B.Subbulakshmi1, A. Periya Nayaki2, Dr. C. Deisy3
|
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Innovative Research in Science, Engineering and Technology
Frequent Pattern Mining plays an important role in the field of data mining community today. The concept of frequent pattern mining can be extended to dynamic databases and data streams. A data stream represents a massive input data that arrives at high speed and is unbounded. There are various data processing models in data streams. The challenge in frequent pattern mining is the presence of null transactions. Null transaction is a transaction that does not contain any itemset being examined. Most of the existing streaming algorithms did not consider the overhead of null transactions. Hence, they fail to discover the frequent patterns faster and occupy lot of memory space to represent frequent items. To overcome this issue, a new algorithm called Screening of Null Transactions-Frequent Pattern Mining over Data Streams (SNT-FPMoDS) has been proposed which extracts frequent patterns using landmark and sliding window models. Experimental results using real datasets on different models show that our proposed algorithm saves lot of computation time and memory.
Keywords |
| Data Stream, Landmark Window Model, Sliding Window Model |
INTRODUCTION |
| Data Mining is used to discover the patterns from huge databases. In the knowledge discovery process, frequent pattern mining [3] is one of the fundamental and interesting problems [10] to find the frequent patterns within the dataset. The problem of frequent pattern mining is not limited to static databases and also extended to dynamic databases [9] and data streams. |
| data stream is a massive input data that arrives at high speed and is unbounded. Examples of data stream include telecommunication, sensors, stock market analysis, web click streams data, etc. In data streams, concept change is one of the important phenomena because data is not static here. So, whenever a significant change occurs, it may require more memory and processing power and it may produce inaccurate results. |
| There are three data processing models [7] namely Landmark Model, Damped Model or Time Fading Model, Sliding Window Model. Landmark Model extracts the frequent patterns over the entire history of data streams. |
| Time Fading Model or Damped Model brings the frequent patterns with respect to time or based on the weight assigned to each transaction. Sliding Window Model processes only the recent transactions and gives the recent frequent patterns in the result. One of the three models should be chosen for stream mining process based upon the application selected. |
| In addition to that, a single item in a transaction does not give any association for pattern mining. This transaction is known as null transaction. The performance degrades due to the presence of null transactions in a dataset. |
| Main Contribution of this paper is depicted as follows. The major work is to mine the frequent patterns over data streams using different models. A new algorithm called SNT-FPMoDS (Screening of Null Transactions-Frequent Pattern Mining over Data Streams) has been proposed and it was implemented using Landmark and Sliding Window models. Screening of null transactions contributes towards the reduction in number of frequent patterns, memory storage and executing time. |
RELATED WORKS |
| In 2002 [2], Manku and Motwani proposed an algorithm called lossy counting for frequent items mining and then extended it for frequent itemset mining. In this work, all frequent itemsets are outputted with an error bound and there are no false negatives in their result. In 2004, Chris Gianella et al. [5] proposed a new algorithm using tilted time window model to mine the complete set of frequent patterns over data streams. In 2004, Li and Lee [4] proposed an algorithm called DSM-FI for approximate mining of frequent itemsets over an entire history of data streams. Here, lots of tree traversals are required to collect the frequency information. In 2006, Leung et al. [8] proposed an algorithm called DSTree, prefix tree based data structure is used to maintain recent frequent patterns. Here, Sliding window model is used to mine the complete set of recent frequent patterns. Each node of prefix tree contains the transaction information. In 2008, Mozafari et al. [11] proposed an algorithm for mining frequent patterns using sliding window model. In 2009, Tanbeer et al [12] proposed an algorithm CPS-tree, a prefix based data structure is used to maintain the recent and exact information. Insertion and Restructuring phases are repeatedly executed while data stream processing. In 2009, Li et al. [13] proposed the efficient sliding window techniques called MFI-TransSW and MFI-TimeSW for frequent pattern mining over data streams. In 2010, Calders et al. [14] proposed an approximate algorithm for mining top-k frequent items with max-frequency. In 2011, Binesh Nair et al. [15] proposed an algorithm called CFIM-P, to mine the closed frequent patterns over static data with the elimination of null transactions. |
PRELIMINARIES AND DEFINITIONS |
| Let S be a stream of transactions and I= {i1, i2,…, im} be the set of items. For an itemset Y, which is a subset of I, a transaction T in S which contains an itemset Y if Y ⊆ T. The Support of Y is defined as the fraction of received transactions that contains the itemset Y. If the support (Y) is greater than or equal to the user given minimum support threshold value, then the item is said to be frequent. |
| Definition 1: (Landmark Window Model) |
| Landmark window model is a data processing model in data stream which maintains the history information from the landmark starting point (tsp) to the current point (tcp). If transaction tm is valid, |
| tsp ≤tm ≤tcp |
| Definition 2: (Sliding Window Model) |
| Sliding Window Model is one of the data processing model in data streams which process and maintains only the recent transactional data, |
| tn-|w|+1 ≤tm ≤ti |
| Where tn-|w|+1 and ti are the window’s identifier and ith received transaction. |
| Problem Statement: Given the data stream s, size of window and minimum support threshold, the problem is to find the all frequent itemsets using Landmark and Sliding Window model by eliminating the null transactions. |
PROPOSED METHOD |
| The method proposed here is based on Eclat algorithm which is used for mining all frequent itemsets operating on the vertical layout of database [6]. A new algorithm has been proposed with elimination of null transactions for mining all frequent patterns over data streams using landmark window and sliding window models. The modules identified are Elimination of Null Transactions, Window Initialization, Pane Insertion and Frequent Patterns Maintenance. First three modules are common in both of these models. Maintenance of frequent patterns is done differently by each of the models. |
| Elimination of Null Transactions: Null Transaction is a transaction which contains a single item in a dataset. This transaction does not give any information for association. An attempt has been made to eliminate the null transactions [15] in order to reduce the processing time for finding k-frequent itemsets. It saves lot of memory when the patterns are maintained in the tree. |
| Window Initialization: The window initialization phase is activated while the number of transactions generated so far in a transaction data stream is equal to the window size (ws). |
| Pane Insertion: Adding a single transaction or a batch of transaction to an existing window is called as pane insertion. Due to efficiency issues, addition or deletion of transactions from window is in batch wise. The number of transactions are added to a window is equal to the pane size (ps). |
| These three phases are common for mining frequent patterns with elimination of null transactions over data streams using landmark (SNT-FPMoDSLW) and sliding window (SNT-FPMoDSSW) models but differ in frequent patterns maintenance phase. This phase is briefly explained along with algorithm for different models in following subsections. |
| A. SNT-FPMoDSLW – Proposed Method of Landmark window model: |
| In this section, the concept of our proposed method SNT-FPMoDSLW (Screening of Null Transactions- Frequent Pattern Mining over Data Streams using Landmark Window Model) is briefly explained. This model is used for users who are interested in historical data from a landmark time. The modules of the algorithm are as follows: |
| 1. Elimination of Null Transactions |
| 2. Window Initialization |
| 3. Pane Insertion |
| 4. Maintenance of Frequent Pattern Tree for Landmark Window (FPT-LW). |
| Window is initialized after eliminating the null transactions and frequent patterns are mined using Eclat algorithm [1]. This algorithm is operating on the vertical layout of database [16, 19]. This layout contains the tidlists of items in the database. The support of all single items is directly extracted from the vertical layout of dataset in a single scan. If the support value is greater than or equal to the user defined minimum support threshold then those single items are considered as frequent items. Then, we do the intersection operation over tidlists of frequent single items to obtain the support value for candidate 2-itemsets. The process is repeated until all the frequent patterns are extracted from the initial window. When a pane or batch of transactions is inserted to the window, the frequent patterns are extracted in the same way from pane and the results are updated. |
| i) Maintenance of Frequent Pattern Tree for Landmark Window (FPT-LW) |
| A new data structure namely FPT-LW has been proposed to maintain the frequent patterns during data stream processing. The extracted frequent patterns from the initial window are inserted into FPT-LW tree. After every pane insertion, frequent patterns are updated to this tree. |
 |
 |
| In this section, the Screening of Null Transactions- Frequent Pattern Mining over Data Streams using Sliding Window (SNT-FPMoDSSW) algorithm is explained briefly. Sliding window model finds the frequent patterns over data streams by considering only the recent set of transactions. When the window slides, the old invalid transactions are deleted and new valid transactions are inserted into the window. The frequent patterns are updated in the tree because of this deletion. There are two types of sliding window: i) Transaction-Sensitive Sliding Window ii) Time-Sensitive Sliding Window. The mining process used in this paper is based on transaction-sensitive sliding window model which maintains the fixed size of transactions in a window. The sliding window model is appropriate for those users who are interested to know only the recent information. |
| The modules of this algorithm are as follows: |
| 1. Elimination of Null Transactions |
| 2. Window Initialization |
| 3. Pane Insertion |
| 4. Maintenance of Frequent Pattern Tree for Sliding Window (FPT-SW) |
| The concept of first three modules is same as that of landmark window model except the frequent patterns maintenance phase. |
| i) Maintenance of Frequent Pattern Tree for Sliding Window (FPT-SW) |
| A new data structure called FPT-SW is used to store the frequent patterns mined using sliding window model. Initially, the extracted frequent patterns from the initial window are stored in FPT-SW tree. Then after every pane insertion, window sliding phase is activated. During this window sliding phase, old information is deleted from the FPT-SW tree and new patterns are inserted into the tree. In Fig. 5, the procedure for updating the frequent patterns after pane insertion is given. |
 |
 |
|
| the customers was changed over a time. We executed experiments on these datasets for mining frequent patterns by setting up the following parameters: Window Size (ws), Pane Size (ps), and Minimum Support (σ). The parameter which is used for mining frequent pattern is σ (minimum support). The pattern which is greater than or equal to σ is considered as a frequent pattern. In this paper, the performance of the proposed algorithm SNT-FPMoDS is compared with FPMoDS on landmark and sliding window models. |
| B. Experimental Results- Performance for SNTFPMoDSLW & SNT-FPMoDSSW |
| In this section, the performance evaluation of proposed algorithms SNT-FPMoDSLW and SNTFPMoDSSW is presented. First, we compared the number of frequent patterns produced by proposed and existing algorithms for the landmark model (FPMoDSLW & SNTFPMoDSLW) under varying minimum support thresholds using BMS WebView-1 and BMS WebView-2 datasets and the results are shown in Fig. 9. In the second experiment, we compared the running time of two algorithms for landmark model and it is shown in Fig. 10. |
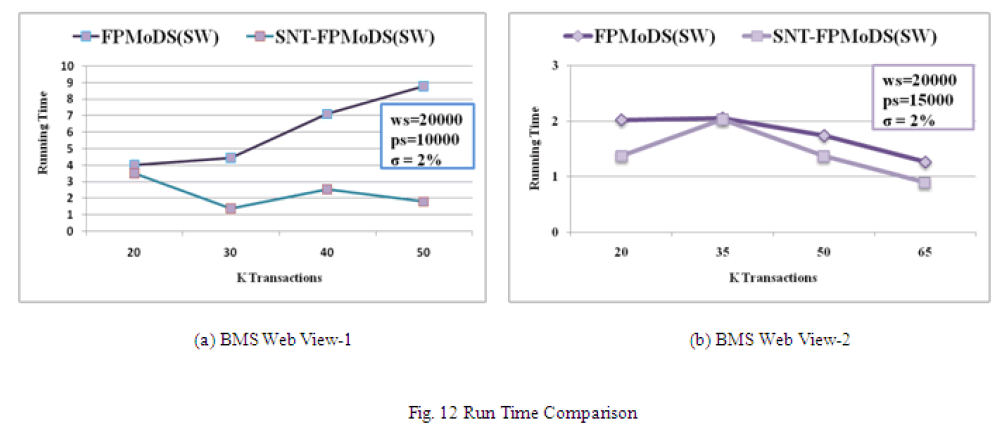
| Fig. 11 shows the comparison of number of frequent patterns and memory storage for the sliding window model with different window size and pane size. It is observed from the figure that screening of null transactions gives better result than the existing algorithm. We also compared the execution time of the proposed algorithm with the existing algorithm in Fig. 12 for the sliding window model. |
| Depending upon the type of the application, the landmark or sliding window model can be used to mine frequent patterns by eliminating all null transactions earlier. |
 |
 |
CONCLUSION |
| In this paper, we proposed new methods namely SNTFPMoDS (SNT-FPMoDSLW & SNT-FPMoDSSW) to efficiently mine the frequent patterns from data streams using landmark and sliding window models. The selection of algorithm and the data processing model is based upon the application requirements. Landmark model is best suited for applications where users are interested in mining patterns over a period of time whereas sliding window model is used to analyze frequent patterns genera-ted from the recent information. However, the presence of null transactions in a stream of transactions degrades the performance of pattern discovery process. The proposed work has attempted to resolve this issue by eliminating those null transactions in a data stream. The SNT-FPMoDS algorithm is experimentally evaluated on real-life datasets with different window size and minimum support thresholds on both models. From the experimental results, it is observed that the SNT-FPMoDS algorithm mines the complete set of frequent patterns than the FPMoDS with less memory usage and runtime for both landmark window and sliding window models. |
References |
|