International Journal of Innovative Research in Science, Engineering and Technology
ISSN ONLINE(2319-8753)PRINT(2347-6710)
ISSN ONLINE(2319-8753)PRINT(2347-6710)
Kiruthika.T1, Brindha.P2
|
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Innovative Research in Science, Engineering and Technology
One broadly used method for representing membership of a set of items is the simple space-efficient randomized data structure known as Bloom filters. Generally the regular Bloom filter suffers in terms of power consumption and FPR (False Positive Rate). To overcome this we proposed two methods. The pipelined Bloom filter architecture for k-stages has been proposed to attain the significant power saving. The second method is the parallel Bloom filter that reduces the FPR. Further a novel Bhsequence scheme is introduced in this pooled pipelined and parallel Bloom filter architecture to reduce the FPR. Through this method around 10%-20% of the power saving can be achieved. Bloom filters are used in network security applications such as web caches, resource routing, network monitoring.
Keywords |
| False Positive Rate (FPR), Multi-dimension Dynamic Bloom Filter (MDBF), Parallel Bloom Filter (PBF), Counting Bloom Filter (CBF). |
INTRODUCTION |
| Now a day, there is an adequate amount of software programs are installed to guard the computer systems. By using NIDS method the malicious contents [1] such as internet worms and viruses were identified in network packets. Network intrusion detection system (NIDS) [11] scans the header of the internet packets to seem for the presence of the predefined IP address.Generally in VLSI signal processing, several outputs are computed in parallel in a clock period for parallel processing. In pipelining, it processes a single module in a clock period. There are two main advantages of using pooled architecture: high speed and low power. A Bloom filter is an inventive randomized data structure for giving information to representing a set in order to corroborate approximate membership queries. It was discovered by Burton Bloom in 1970’s [2] for large-scale network applications such as shared web caches, query routing, network monitoring, resource routing and traffic management. Bloom filters are extensively used in networking applications During deep packet inspection [12], this checks the payload of the packets against a set of known virus. The bloom filter may offer better performance, if the false positive [10] does not cause major troubles. Anywhere a list or set is used, and space is a concern, a bloom filter should be considered. While use a bloom filter, consider the potential effects of false positives. Generally Dynamic bloom filters are introduced to represent dynamic sets, as well as static sets.DBF can regulate the false positive probability at a low level. Standard and dynamic bloom filters just mainly focus on the representation of single attributes instead of representing [3] multi attribute. One of the new technique Multi-dimension dynamic bloom filter (MDBF) is introduced to represent the multi attribute items. By the use of RBF (Retouched Bloom filter) the overall error rate is maintained low [7] It is expressed as a group of false positive rate and false negative rate. In RBF, the error rate [8] is made equivalent to the false positive rate of the consequent bloom filters. In order to reduce the power consumption of bloom filters, the pipelining technique is engaged. The embracing new type of bloom filter is termed as “Pipelined Bloom Filter”. Bloom filters indicate the set of ‘n’ patterns in a m-bit array vector. Before programming, the elements in this array are set to ‘0’and each signature is hashed k times by the autonomous hash functions. Each hash function locates homogeneously to a random number and that indicates a bit location in the m-bit long lookup vector, which is set to ‘1’. In query stage, bloom filters computes k many hash values for an input string ‘y’ by utilizing the same hash functions, used in programming operation. If all the hashes locate to the bit location that are set to ‘1’ (match), then the query string is in the set [5]. If any of the hashes locates to the bit location that is set to ‘0’ (mismatch), then the query string is definitely not in the set. A bloom filter not at all produce false negatives, if it decides input is a nonmember, but it may produce false positives. The false positive probability f is estimated by, |
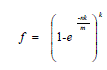 |
| Where, n is the number of patterns programmed into the bloom filter, k is the number of hash functions used to realize the bloom filter and m is the length of the lookup vector.The choice of m>n, to diminish the false positive probability. For a fixed value of m/n, k must be large to minimize the false positive probability. The number of hash functions that minimizes the FPR is, |
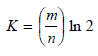 |
| The power consumption of the regular bloom filter is a summation of the power consumption of the each of the hash functions, P H i , P L, P AND . |
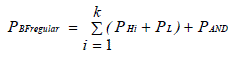 |
| Here, PAND is ignored. Since it is minimal compared to the power used by the hash functions and also presume that the lookup power over a m-bit vector is in the order of steady for each index designed by any of the hash functions. As hash functions with the identical number of input bits will be implemented with the similar number of components and will consume approximately the same amount of power. So we can write the power consumption of a regular bloom filter as follows, |
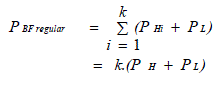 |
| However there is a critical challenge, to the representation and queries for items that are having multidimensional attributes.So we proposed one of the new technique MDDBFs (Multi dimension dynamic bloom filters) to represent items with multiple attributes. The probability of false positives may increase, if the MDDBF approach [4] lacks a way to verify the dependency of multiple attributes of items. Nevertheless, the MDDBF approach lacks a way to confirm the dependency of multiple properties of an item, which may increase the probability of false positives. Through by the parallel bloom filter with a hash table, this supports the representation of items with multiple attributes. By using parallel-pipelined bloom filter design [6], multiple strings can be queried and that can reduce power consumption along with improving the throughput. In pipelined design, query string is estimated at one of the pipeline stages, remaining stages are in ‘idle’. This technique delivers a greater amount of reduction in power consumption. But it suffers computation latency. By using multiple hash functions, multiple query strings are concurrently evaluated in parallel pipelined bloom filter design. |
PIPELINED BLOOM FILTER |
| Basically, a pipeline bloom filter consists of several groups of hash functions that are utilized in different stages. While the number of hash functions required to diminish the false positive probability of a bloom filter is large, it is superior, in terms of power, to implement these hash functions in a pipelined style. We call this new type of bloom filters pipelined bloom filter [7]. Here hash functions are arranged in pipelined manner, to reduce the power consumption. Essentially it consists of two groups of hash functions. |
| 1. First stage, forever computes the hash values. |
| 2. The second stages merely compute the hash values, if there is any match between the input and the patterns. |
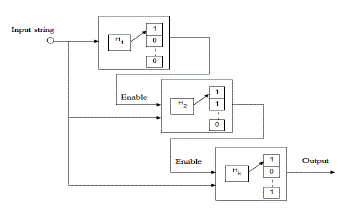 |
| The merits of using pipelined bloom filter techniques is that, if the first stage identifies a match, there is no need to use the second stage to decide whether input string is a part of the signature set. This is possible only because the Bloom Filter is free from False negative rate. The shortcoming with this is power consumption. |
| Fully pipelined bloom filter design is the remedy for this power consumption problem. The building of fully pipelined bloom filter is displayed in Fig 1. This architecture has the same number of hash functions as the regular bloom filter. Therefore the false positive probability is also same. In the inquiry stage, the initial hash functionh1, is fed by a new inquiry sequence every cycle. An inquiry string has progressed to the next stage only when the prior hash function produces a match. Now every hash module consists of hash function and a m/k bit lookup array. The inquiry string progress to the next stage, if previous hash functions fail to match the signature. When the inquiry string proceeds to the next stages, the design increases the latency. |
| Analysis |
| Each hash function coefficients are randomly selected in the range of 1 to m. The probability that the bit is unset, after all the signatures are programmed by using k-many independent hash functions are α. |
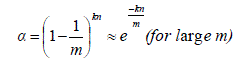 |
| Here (1-1/m) is the probability that the bit is unset behind a single hash value computation with a single signature. The probability that any one of the bit is set is, |
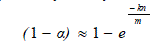 |
| In order for the first stage to generate a match, the bits indexed by all r of the free hit and miss hash functions should be set. So, ‘P’ is the match possibility of the initial stage that is indicated as, |
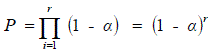 |
| By means of a probability of (1-p) the initial stage of the hash functions in the pipelined bloom filter will cause a mismatch. Or else, the initial stage produces a match, then the next stage is used to evaluate the input with the signature required.Therefore the power consumption of a pipelined bloom filter is given by, |
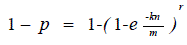 |
PARALLEL BLOOM FILTER |
| An intuitive approach to representing multiattribute items can concatenate various attributes into a single-attribute array to be stored in a standard bloom filter (SBF). Nevertheless, such approach may offer delay inquiry replies to users if multiple attributes have dissimilar formats. In fact, it takes a extended time to get the hashed result for a single but long attribute array.However, standard form in an SBF is fundamentally a compressed representation, limiting its rich inquiry services. In real-world applications, many inquiry requests cannot provide exact and absolute descriptions of queried items, which bound the usage of SBFs for queries of partial attributes. In this paper we present an approach to the space well-organized representation of multiattribute items. The future approach utilize data structures to carry out rapid but exact membership queries and achieve space savings. So we describe data structures in three phases: |
| 1. A Parallel Bloom filter (PBF) structures, |
| 2. PBF with a Hash Table (PBF-HT) and |
| 3. PBF with a Bloom filter (PBF-BF). |
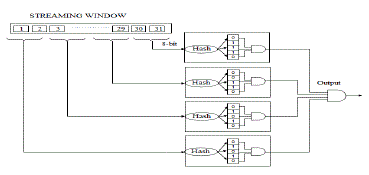
| Fig 2.Shows the Architecture of Parallel bloom filter.This structure takes each 8-bit value from streaming window for each individual hash module and produce the corresponding output. Finally that outputs are ANDed and get the final single output. False positive rate is highly minimized while using this parallel bloom filter method, but hardware is slightly increases. |
COMBINED PIPELINED AND PARALLEL BLOOM FILTER |
| Combined Pipelined and parallel bloom filter is designed to satisfy the High speed and Low power requirements. A general bloom filter consists of multiple hash functions and a lookup array. The lookup array which is m-bit wide and to estimate a query string operation, specific k bits in the lookup array are inspected [9].If all bits locate to 1, the query string is member of the set. There is a possible that a non-member query string may be evaluated as a member of the signatures, which is false positive rate (FPR).If number of hash functions increases, the FPR(False positive rate) is reduced. It introduces significant amount of power consumption. By using combined parallel and pipelined bloom filter design[6], multiple query strings to be filtered in parallel and can reduce power consumption along with improving the throughout. |
 |
| In pipelined design, query string is estimated in one of the pipelined stages, remaining stages are in ‘idle’. This technique having greater amount of reduction in power consumption.By using multiple hash functions, multiple query strings are concurrently evaluated in parallel pipelined bloom filter design and compared to regular bloom filter greater development in throughput. |
Bh-SEQUENCE METHOD |
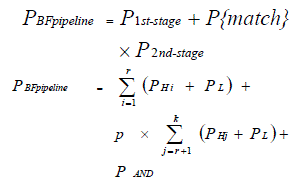 |
| False Positive Rate of Bh-sequence method |
| We now present the false positive rate of Bh Bloom. As generally assumed in the reference [7] we assume that the hash functions plot items to random numbers equally spread over their given range. Theorem: The false positive rate of Bh Bloom is given by, |
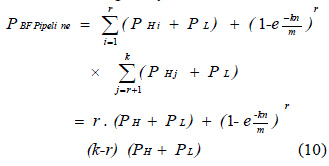 |
EXPERIMENTAL RESULTS |
 |
 |
 |
| Fig .5Power saving ratio of pipelined and parallel bloom filter |
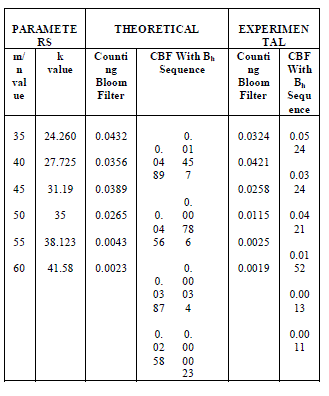
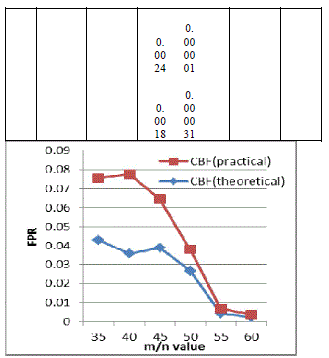
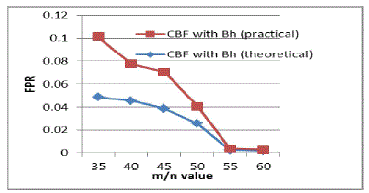
| From table 1, shows the false positive rate of counting Bloom filter and CBF with Bh-sequence are depending on m/n and k values. The choice of m should be greater than n, to diminish the false positive probability. For a fixed value of m/n, k must be larger to minimize the false positive probability. For example, substituting m/n=35 in (2) equation, the corresponding k=24.260 is calculated. Substituting k value into (1) equation, the corresponding false positive probability is estimated for counting Bloom filter. From this analysis, bloom filter with Bh-sequence will produce a less false positive probability compared with normal counting bloom filter. From this analysis, by using these methods false positive probability is highly reduced. From table 2 the PSR of pipelined BF is higher than the parallel BF. |
CONCLUSION |
| In this paper, we proposed a pipelined Bloom filter method to achieve greater power saving.To attain the accurate signature detection multi hash functions have to be included. The number of hash functions required to minimize the false positive probability of a bloom filter is large, thus power consumption is more. To reduce this, the hash functions are implemented in a pipelined manner, in which hash functions are made as stages and detection of signature is based on the previous stage output.Through this method 10%-20% of the power saving can be achieved.The use of parallel Bloom filter that diminish the FPR.Compared with traditional bloom filter, the use of Pipelined bloom filter with Bh-sequence method there is a small reduction in FPR. But for parallel Bloom filter with Bh-sequence method significant reduction in FPR. The Power saving ratio of pipelined bloom filter is high compared with parallel bloom filter. |
ACKNOWLEDGEMENT |
| The authors acknowledge the contributions of the students, faculty of Velalar College of Engineering and Technology for helping in the design of test circuitry, and for tool support. The authors also thank the anonymous reviewers for their thoughtful comments that helped to improve this paper. The authors would like to thank the anonymous reviewers for their constructive critique from which this paper greatly benefited. |
References |
|