International Journal of Advanced Research in Electrical, Electronics and Instrumentation Engineering
ISSN ONLINE(2278-8875) PRINT (2320-3765)
ISSN ONLINE(2278-8875) PRINT (2320-3765)
K.Ramesh1, C.Vasumurthy2 and Prof.D.Venkatesh3
|
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Advanced Research in Electrical, Electronics and Instrumentation Engineering
Clustering is a process of grouping objects based on certain similarity measure. Then groups are known as clusters which can be analyzed and used further for operations like query processing. Clustering algorithms assume certain relationship among objects in the given dataset. The existing clustering algorithms with respect to text mining use single viewpoint similarity measure for partitioned clustering of objects. The main drawback of these algorithms is that the resultant clusters can’t make use of fully informative assessment. In this paper we propose a new measure for finding similarity between objects which is multi-viewpoint based. This approach considers multiple viewpoints while comparing objects for clustering. This measure can have more informative assessment of similarity thus making clusters with highest quality. We also proposed two criterion approaches for achieving highest intra-cluster similarity and lowest inter-cluster similarity. The empirical results reveal that the proposed measure is used in making quality clusters.
Keywords |
| Text mining, single viewpoint, multi-view point, clustering |
INTRODUCTION |
| Data mining is the study of the dataset by extracting trends or patterns from data. There are many techniques in the domain of data mining. Clustering is widely used data mining algorithms that help in grouping similar objects. This has many advantages in real world applications such as search engines. Clustering is of two types. They are known as partitioned clustering and hierarchical clustering. This paper focuses on partitioned clustering. K-means is one of the algorithms that are of type clustering algorithms which is widely used in the industry [1].It still appears in the top ten lists of such algorithms. It also has many flavors though they are functionally similar. The K-means algorithm needs dataset and number of clusters as two required arguments. Credit card fraud detection is one of the areas in which K-means is being used. In this application K-Means make a model from the dataset with three different clusters. When new records are added, they are adapted to this model. Based on the pattern in the data, the new transaction is considered normal or probable fraudulent. Thus in the data mining domain, it is simple and effective clustering algorithm [2]. However, it has drawbacks tool as it is sensitive to cluster size, initialization and with low performance comparatively. In spite of these drawbacks, it is still popular and most widely used as it is simple, scalable and intuitive. Its good quality is that it can be used with algorithms in combination to yield good results. The process of clustering with highest quality is an optimization process. With the optimization in place, highest quality clusters can be formed. Therefore, for good quality clusters, it is important to use similarity measure which is suitable. For instance cosine similarity measure is used by K-means. Original K-means also used ED (Euclidean Distance) [3] and [4]. |
| Data grouping, data partitioning and hierarchical clustering are the three types of clustering methods according to Leo Wanner [5]. Clusters with hierarchy are possible with hierarchical clustering while the partitioning clustering focuses on dividing given objects into some groups. The data grouping approach is meant for making a set of overlapping clusters. By investigating the facts provided above, the proposed work is ascertained. Especially the similarity measure is the motivation behind this work. From the review of literature, it is found that the similarity measure being used in clustering has its impact on the resultant clusters. Therefore we thought of making a new similarity measure which is multi-viewpoint based as single viewpoint based measures do not yield highest quality of clusters. After developing the new similarity measure, we focused on making two clustering criteria to achieve highest intra-cluster similarity and lowest inter-cluster similarity. The rest of the paper is structured into sections such as related work, multi-viewpoint based similarity, algorithms, experimental setup and evaluation, results and conclusion. |
PRIOR WORKS |
| Document clustering is required in the real world applications such as web search engines. It comes under text mining. It is being used for many years. It is meant for grouping documents into various clusters. These clusters are used by various applications in the real world such as search engines. A document is treated as an object a word in the document is referred as a term. A vector is built to represent each document. The total number of terms in the document is represented by m. Some kind of weighting schemes like Term Frequency – Inverse Document Frequency (TF-IDF) is used to represent document vectors. There are many approaches for document clustering. They include probabilistic based methods [8], nonnegative matrix factorization [7] and information theoretic co-clustering [6]. These approaches are not using a particular measure for finding similarity among documents. In this paper, we make use of multi-viewpoint similarity measure for finding similarity. As found it literature, a measure widely used in document clustering is ED (Euclidian Distance). |
 |
MULTI-VIEW POINT BASED SIMILARITY MEASURE |
| Multi-viewpoint based similarity is the approach followed in this paper for clustering documents. It does meant that it uses more than one view point while finding similarity between objects and clustering them into various groups. We calculate the similarity between two documents as: |
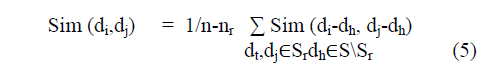 |
| The approach is described here. When di and dj are the two points in cluster Sr, dh is considered the similarity between them which is equal to cosine angle of ED of those points. The assumption used here “dh is not the same cluster as dj and di”. When there is similar distance, the likely chances are that dh is in the same cluster. The multi-viewpoint similarity measure being employed in this paper may rarely provide negative results where there are very few documents. However, it can be ignored provided the documents are more while clustering. |
ALGORITHMS PROPOSED |
| Many algorithms have been proposed to work on multi-viewpoint similarity measure. The procedure for similarity matrix is as shown in Listing 1. |
 |
| Algorithm 2 –Validation Procedure |
| By averaging overall rows, the final validity is calculated. It is as given in line 14. It is known that when validation score is higher, it reflects that the similarity is higher and thus eligible for clustering. Fig. 1 shows the validity scores of multi - viewpoint simialirty and cosine similarity. |
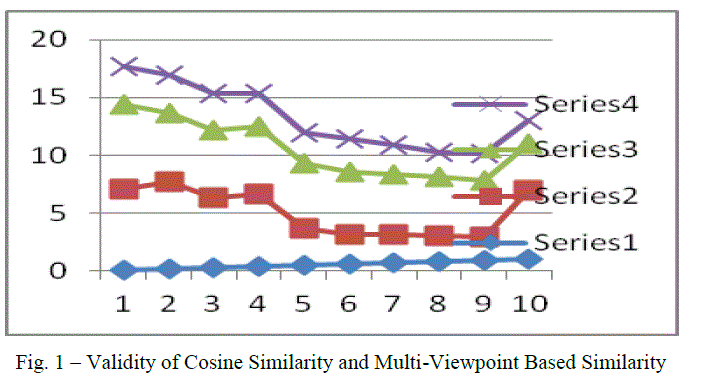 |
| As can be seen in fig. 1, Series 4 is related to klb-MVS, series 3 corresponds to klb-CS, series 2 corresponds to reutors-7 while series 1 corresponds to reutors -7 CS. As shown in fig. 1 performance of MVS is higher when compared to that of CS. |
 |
| Algorithm 3 –Algorithm for incremental clustering |
| Algorithm 3 is shows algorithm with two phases. They are refinement and initialization. Selecting k documents as seeds are known as initialization which making initial positions while the refinement makes much iteration to form best clusters. Each iteration in refinement phase visits n number of documents in random fashion. After that the process of verification is done for each document. If the document is considered similar, it is moved to the cluster. When no documents are there the iterations come to an end. |
PERFORMANCE EVALUATION |
| For performance evaluation for two criterion functions such as Ir, and Iv with respect to multi-viewpoint similarity measure. Bench mark datasets have been used to test the efficiency of our approach. The results are tabulated in table 1. |
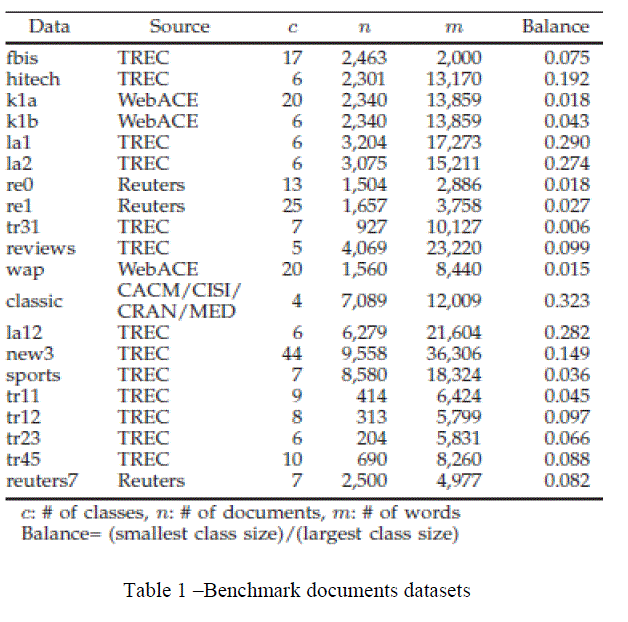 |
EXPERIMENTAL SETUP AND EVALUATION |
| Our algorithm is compared with other algorithms for evaluation. They include M-means, Min Max Cut Algorithm, graph EJ which is nothing but CLUTO’s graph with extended Jacquard, graphCS which is nothing but CLUTO’s graph with Cosine Similarity, SpkMeans which is nothing but Spherical K-Means with Cosine Similarity, MVSC Iv which is nothing but the proposed approach with Iv criterion function and MVSC Ir which is nothing but the proposed approach with Ir criterion. The results are presented in the next section. |
RESULTS |
| The results of experiments are presented in fig. 2 and 3. It shows graphically the results of all clustering algorithms for 20 benchmark datasets. The results are presented into two different graphs. Each graph shows the experimental results of 10 datasets. |
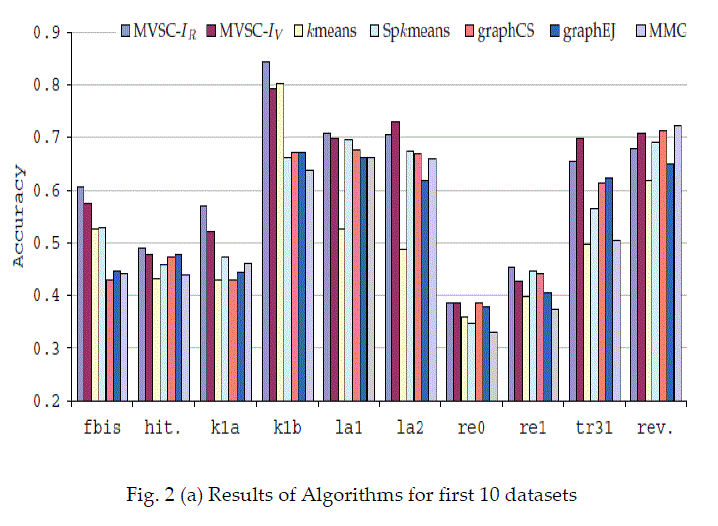 |
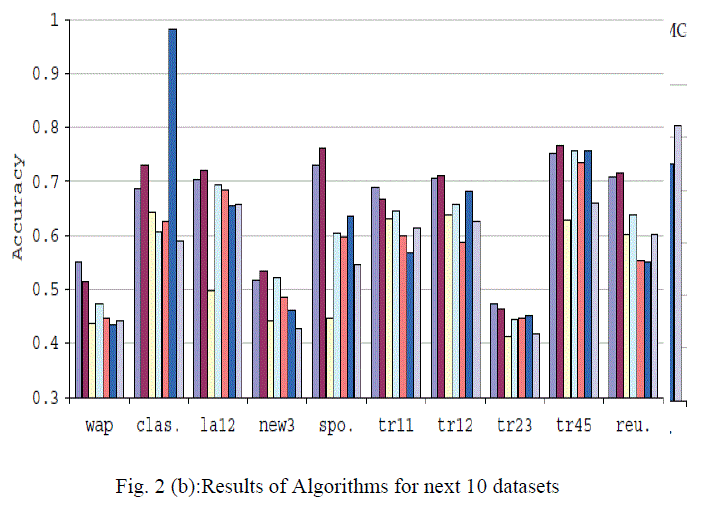 |
| As shown in fig. 2(a) and (b), the proposed approach performs better when compared with other algorithms. GraphEJ performed better only in some cases. Overall performance of MVSC Kr, and MVSC Iv is far better than others. The effect of α is also presented on the performance of MVSC Ir. |
THE EFFECT OF α ON THE PERFORMANCE OF MVSC IR |
| It is understood that the cluster size and balance have their impact on the methods of partitional clustering based on criterion functions. In terms of NMI, FScore, and accuracy the assessment is done and the results are presented in fig. 3. |
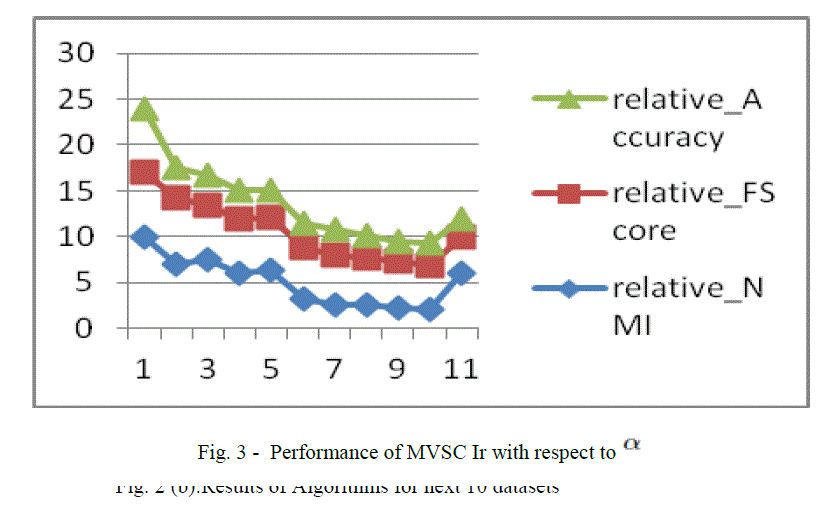 |
| As shown in fig. 3, MVSR Ir’s performance is within 5% with regard to any evaluation metric for best case. |
CONCLUSION |
| This paper presents a novel similarity approach known as multi-viewpoint based similarity measure. The similaritymeasure is capable of providing informative assessment and bestows high quality clusters. The proposed approach achieves highest similarity between objects of same cluster and lowest similarity between the objects of different clusters. Two criterion functions were implemented with MVS. The proposed similarity measure is tested with bench mark datasets. The proposed clustering algorithms in this paper are compared with five other clustering algorithms used for document clustering. The results revealed that the multi-viewpoint based similarity measure outperforms them. |
References |
|