Keywords
|
| Keyword Search System, Query, Fuzzy Search, Index Structures, Type-Ahead Search, Top-k algorithm, XML Data |
INTRODUCTION
|
| A traditional methods require to use query languages XPath and XQuery to retrieve relevant answers from XML data. These methods are good but very hard to nonexpert users. These query languages are difficult to comprehend for nondatabase users., XQuery is complicated to understand fluently. Second, these languages need the queries to be pose beside the underlying, sometimes complex and database schemas. |
| To overcome the limitation , keyword search is derived as an another means for querying XML data, This is easy and today’s recognizable to most Internet users as it just requires the input of keywords for querying XML data . Recently keyword search is a used search archetype for querying document systems and the World Wide Web[24],[23]. It is looks for words the answers wherever in the data. It is most necessary paradigm for searching information on internet. One of the advantage of keyword search is its simplicity-users do not have to learn complex query language and can issue query without knowing about structure of xml data. The very needful requirement for the keyword search is to sort the results of query so that the most relevant results retrieved. The keyword search method provides simple and user friendly query interface to retrieve xml data on internet. Xml is developed to transport and store data in structured way. It does not doing anything, it is created to structure, store, and transport information.xml document contains text with some tags which is organized in hierarchy with open and close tag xml models . |
| To reduce the limitation of html search engine example Google that returns whole text document but the xml captures additional semantics such as in a full text articles, references and subsections are explicitly captured using xml tags. For querying xml data keyword search is effective ,proposed and alternative method available. In today’s approach to query over xml data it requires query languages which are very hard to comprehend for non database users. It can only understand by professionals and expert user. Recently database community has been studying challenges interrelated to keyword search over xml document in xml data [1],[17],[19]. so the today’s XML data search approaches are not user friendly. |
| To solve this above problem many systems introduced various features. The method is Auto complete. This is doing the prediction the words the user had typed in. The more websites support these advantage example Google, yahoo etc.. The one of the greatest limitation of this method is it treats multiple key words as single key word and don’t allow them to appear in other places when searching. To add this problem new method is developed complete search in textual documents this allows multiple keywords to appear in different places but it doesn’t tolerant minor mistakes in query. Fuzzy type ahead search which allows minor mistakes in query [1],[26] . The type ahead search is a user interface interaction method to progressively search for filter through text data. When the user types text, one or possible matches for text are found and immediately present to users. The fuzzy type ahead search in xml data returns the approximate results. The best similar prefixes are matched and returned. This purpose edit distance method is used. Edit distance method is defined as number of operations (deletion, insertion, substitution) required to make the two words equal. For example user typed the query ?mices? but the mices is not in the xml document it contains miches ed{mices, miches} = 1 so therefore the best similar prefix is miches it is displayed. |
RELATED WORK
|
| Bast and Weber[5] proposed complete search in textual document, which document, which can find relevant answer by allowing query keyword appear at any place in the answer. However, complete search does not support approximate search, that can’t allow minor error between query keyword and a answer. Recently, S Ji, G. Li studied fuzzy type-ahead search in textual document [9]. It allow user to explore data as they type, keyword. C Li and J.Feng also studied type-ahead search in relational database [8]. Lowest common ancestor (LCA) of keyword query in the LCA of set of content node corresponding to all the keyword in the query. Many algorithms for XML keyword search use the notation of LCA [10]. Improve search efficiently and result quality, Xu and papkonstantiou [10] proposed Exclusive Lowest Common Ancestor. Type-ahead search also main part of that specify the matching approximate keyword into statement in the matching approximate keyword into statement in the presence of minor error also give approximate answer[6]. The limitation of XML query that complete search it affect the minor error, it is hard to understand to user into the system [1]. To solve the problem into minor error keyword search and matching particular word into query type-ahead search [1]. Minimal cost tree is for each node, we define its corresponding answer to the query as its sub tree with paths to nodes that include the query keyword [7]. J Chen, Lyad A. Kanjb define how top-k work in XML database and how ranking the keyword as effective manner [8]. G Li, Chen Li, J Feng and L Zhou define that when particular keyword present in XML tree how to retrieve and if particular keyword not perfectly match how they retrieve a accurately[9]. XML query techniques Feature Limitation Xpath Collection of element can be retrieve by specifying Directory. One or more condition place on path to increase lack of complexity. Xpointer Specific location defines start point and End point. It specify the absolute location Location path composed of a series of step join with “/” each in down the preceding, not a single step.MCT High ranking score Top- Bottom, Left-Right search data much time need LCA To get answer good ranking They using “And” semantic between keywords ignore the answer that contain query keyword Fuzzy type ahead top-k Easily retrieve data in high ranking score Multiple keyword search required much time. |
TRADITIONAL XML QUERY TECHNIQUES
|
| In conventional search system Xpath and Xquery these two types are used in Xml. Xpath is powerful query language for XML that provide a simple syntax for addressing part of on Xml document. Xpath could be retrieved by specifying a directory like path with zero or more condition place on the path. We have XML document in logical tree with nodes for each element, namespace, processing instruction, comment, attribute text and root reference. |
| The fundamental of the addressing mechanism is the start node and location path derived from one point in an XML document to another. Xpointer can be used specify on specific location or nearer location. Location of path is composed of a series of step connected with “/” each move down the preceding step from root to leaf node. Xquery is slot in feature from query language for relational system and Object oriented system. Xquery co-operate operation on |
| document order and can negative, extract and restructure document. W3c query working group has developed a query language for XML called Xquery. Values in a sequence node can be a document, namespace , attribute, text and elements. The top level path express are ordered according to their position in the original hierarchy, top-down and leftright order [14],[18]. The currently needful parts are Data-Centric document and Document-Centric document in xml data. The Data-centric document Xpath are very hard for understand in less time . It is originate from both in the DB and outside the DB. These documents are used for exchanging data between companies. These are processing by machine; they have effective regular structure, fine gained data and no mix content. Document-Centric are document usually developed for human use, they are usually collected directly in XML or some other format(RTF,PDF and SGML). This is then translated to XML. Document-Centric doesn’t have regular structure, larger achiever data and lots of mixed content [13]. |
FUZZY SEARCH FOR XML QUERY TECHNIQUES
|
| This sections contain important XML query and keyword search methodologies are explain. Major problem associated to Xpath and Xquery are their limitations involved in the syntax for query. Here compared to Xpath and Xquery, LCA-based interaction search reference [7],[21] and minimum cost tree reference [14],[22] are efficient and better. Below mentioned subsection give detailed information on the above said methods. |
| A. Minimum cost tree: |
| To retrieving relevant information , to a keyword query over XML document. The every node, we define all its relative answer to the query as its sub tree with paths to nodes that contain the query keyword. This sub tree in XML document format called the minimal cost tree (MCT) for that node. Different node from different answer to the query, and we will learn how to compute relevance based rank of xml data. Suppose in XML data contain document D, a node n The keyword query Q={k1,k2,k3,…,kl}, a MCT of query “Q” and node n in the sub tree rooted at N, and each keyword ki € Q, if node N is a predecessor of n then it is a qussi-content node of k with data in this node, The sub tree include the pivotal path for ki and node n. we first identify the every predicated word for each input keyword from query. After, we construct the MCT for each node in the XML tree based on the predicated word, and write the best ones with the highest score. |
| The main advantage of this method is, even if a node does not have descendent nodes that include all the keyword in the query, this node has still be considered as a potential answer reference [4]. |
| B. LCA-Based interactive search: |
| We know a lowest common ancestor (LCA) based interactive search method. We use the semantics of Exclusive LCA(ELCA) to knowing relevant answer for predicated words. We use trie index structure in XML data for tokenized words. Primarily for a single keyword, finding nearest feasible node from XML document tree , Then we locate the leaf descendents of this node, and retrieve. The corresponding predicated words and the predicated XML element on their inverted lists and the query string into each and every keyword k1, k2, k3,k4,…, kv. the every keyword ki (1< v< m), there are list of many predicated word from xml data [5]. |
Steps :
|
| 1. The keyword query for LCA based method retrieve content nodes in XML that are in inverted lists. |
| 2.Finding the Lowest common ancestor(LCA) of content nodes from inverted list. |
| 3. Taking the sub tree rooted at Lowest common ancestors(LCAs) answer to the query. |
Limitation :
|
| It is provide low result quality and answers are not relevant . |
| C. ELCA based method |
| To overcome the limitation of LCA based method exclusive LCA (ELCA) [4],[26] is proposed. It states that an LCA is ELCA if it is immobile an LCA after removing its LCA descendents. For example suppose from above fig.the user has typed the query “db tom” then the content nodes of db are {13, 16} and for tom are{14,17}, the LCAs of these content nodes are nodes 2,12,15,1, here the ELCAs are 12,15. With relevant answer sub tree rooted with these nodes is displayed which are relevant answer Node2 is not an ELCA while it is not an LCA after removing nodes 12 and 15. XU and papakonstantinou [9] developed a binary-search based method to efficiently identify ELCAs. The advantage of ELCA is retrieving more relevant than the LCA based method. |
| D. Fuzzy Type-ahead and top-k for XML data search |
| In this paper we first check it out that how fuzzy type-ahead search algorithm are reduce the limitation of Xpath and Xquery language and keyword search. First there are know auto complete search that, if there are keyword is available in same place in the xml document, After he can retrieve easily and efficiently but keyword place different place (node) into the document then auto search unable to work in this state. Example “apple iphone” and “iphone has some different assets”, in that situation, case and strategy “apple iphone” present in one node and next node but iphone feature present in other node. Second one is complete search provide to access data in different place in text document but it can not access data when keyword contain minor error into the keyword query . |
| The above situation is addressed in fuzzy type-ahead search. It had contain keyword, If keyword contain minor error into the keyword query it can access data approximately. For ranking the answer of keyword it used LCA and MCT with their particular score [7],[14],[16]. The present parameterized top-k algorithm proceeds in two different stages. The first is a structure algorithm that on a problem that on a problem instance construct a structure of feasible size of keyword, and the other stage is an enumerating algorithm that produces the k best solutions to the instance based on the structurein xml data. We develop new techniques for supporting efficient enumerating algorithm. We preparing the relation between fixed-parameter tractability and Parameterized top-k algorithms in searching and ranking answers , [1][23]. For the ranking query answer, we have discussed how to rank the MCT for a node n as answer to the query. Intuitively, we first evaluate the effectiveness between node n and each input keyword, and then combine all these relevance score as the all score of the minimal cost tree( MCT). We will look towards on different method to quantity the relevance of node n to a query keyword, and adding relevance score of node [4], [5]. |
| 1. Ranking the sub tree |
| There are mainly two ranking function to quantify the rank(score) between node n and keyword ki. Case 1: n contain keyword ki. The relevance or score of node n and keyword ki is calculated by |
 |
| Where, tf (ki, n) – no: of occurrence of ki in sub tree rooted n idf (ki)- ratio between number of node in XML to number of nodes that contain keyword ki itl(n)- length of |n/nmax|=node with max terms s- Constant set to 0.2 Suppose fig.2.1 user composed a query containing keyword “db” |
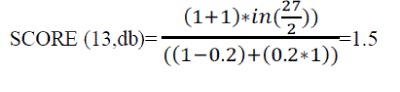 |
| Case 2: Node n doesn’t contain keyword ki but its descendent has ki. Ranking based on ancestor and descendent relationship. Second ranking function to compute the score between n and kj is |
 |
| Where p- set of pivotal nodes α – constant set to 0.8 -Distance between n and p |
| 2. Ranking Fuzzy search |
| Suppose a keyword query Q= {k1, k1,….,kl} in term of fuzzy search, the minimal-cost tree may not contain predicated list of words for every keyword, for contain predicted words for every keyword. Suppose predicated word be {w1,w2,….,wl} the best similar prefix of wi would be considered to be most parallel to ki. The function to quantify the similarity among ki and wi Where ed- edit distance ,ai –prefix ,wi – predicted word –constant. |
 |
| Where value of γ is turning parameter between 0 and 1, as the former is more important, γ is near to 1. The experiment suggested that a good value for γ is 0.95. We elaborate the ranking function by incorporating this similarity function to support fuzzy search as-below: |
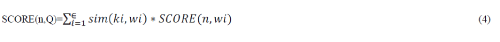 |
CONCLUSION
|
| In this paper, we studied the need of fuzzy type-ahead search in XML data. We derived useful index structures, efficient algorithms, and narrative optimization techniques to gradually and efficiently spot the top-k answers. We examined the ELCA-based technique to interactively and effectively identify the predicted answers from massive data. We have developed a minimal-cost-tree (MCT) based search method to efficiently This paper presents the keyword search over the XML data which is user-friendly and there is no need for the user to study about the XML data..We have implemented our method achieve high search effectiveness and result quality. |
Future Scope
|
| 1.The application can be used for extending search on web. |
|
|
| 2.Facility to incorporate downloading of files. |
| 3.The application can be extending for searching multiple xml files. |
| |
Figures at a glance
|
 |
 |
| Figure 1 |
Figure 2 |
|
| |
References
|
- J.Feng and Guoliang Li “Efficiently Fuzzy type-ahead searching XML data” IEEE transction on Knowledge and Data Engineering Vol.14,pp. 1280-1292,May 2012.
- CH.Lavanya “Interactive search over XML Data to obtain Top-k result” International journal of Soft Computing and Engineering, ISSN: 2231- 2307, Volume-3, Issue July 2013
- S.Agrawal, S. Chaudhri and G.Das “DBXplore: Asystem for Keyword Based Search over relational Database”, proc. Int’l Conf. Data Eng(ICDE), pp.5-16,2002
- Z. Bao, T.W.Chen and J. Lu, “Effective XML Keyword search with relevance oriented Ranking”, proc Int’l conf Data Eng(ICDE)2009
- H. Bast and I.Weber, “Type less, find more:Fast Auto Completion search with a index”, Proc. Ann Int’l ACM conf Research and Development in information Retrieval(SIGIR) 2006
- [ L.Li, H. wang, J. LI, H.Gao “ Efficient algorithum for skyline top-k keyword queries on XML streams” Harbin Institude of Technology.
- Y.Xu and Y.Papakonstantiou, “Effiient keyword search for smallest LCA in XML data” procInt’sconf Extending Database Technology Advance in Database technology(EDBT) 2008
- G. Li, S.Ji,C.Li and J.Feng, “Efficient type-ahead search on Relational Data: A Tastier Approch” proc ACM SIGMOD Int’tconf Management of data,2009
- S.Ji, G. Li, C. Li and J.Feng, “Efficient Interactive Fuzzy Keyword Search”, Proc Int’l conf World Wide Web ,2009
- Yu. XU Teradat, YannisPapakonstantion university of California, “Efficient LCA based keyword search in XML Data” ACM Copyright, 2003
- Andrew Eisenberg IBM, “Advancement in SQL/XML” Jim Meton oracle corp, 2002
- Ronald Bourret, “ XML and Database”, Independent consultant, Felton, A 18 Woodwardia Ave. Felton CA 95018 USA SPRING 2005.
- G.Li, JianHua Feng, Lizhu Zhou, “Interactive search in XML Data” Deparment of Computer Science and Technology, Tshinghua National Laboratory for Information Science and Technology, Tsinghua university, Beijing 100084,China
- Bolin Ding, Jeffrey Xu Yu, Shan Wang, Lu Qin, Xiao Zhang Xuemin Lin “ Finding top-k Min-cost –connected Tree in Database”, The Chinese university of Hong Kong China
- L.Chen, Lyad A kanj, JieMeng, Ge Xia, FenghuiZhange , “Parameterized top-k algorithm”, communicated by D-Z DU, 2012
- Dolling Li, Chen Li, J. Feng, Lizhu Zhou, “SAIL: Structure aware indexing for effective and progressive top-k keyword search over XML document”, Deparment of Computer Science, university of California, Irvine, CA 92697- 3435,USA
- H.Willimson,”The complete Reference of XML”, The McGrew Hill Companies, Inc, New York 2009
- Luis M. de Campos, Juan M. Fernández-Luna, Juan F. Huete, and Eduardo Vicente-López, “Using Personalization to Improve XML Retrieval”, IEEE Transactions on Knowledge and Data Engineering,pp.1280-1292,2011.
- Jianxin Li, Chengfei Liu, Rui Zhou, Wei Wang, “Top-k Keyword Search over Probabilistic XML Data”, IEEE International conference on data engg.(ICDE),pp.673-684,2011 .
- NikolausAugsten, Denilson Barbosa, Michael M. Bo ¨hlen, and Themis Palpanas, “Efficient Top-k Approximate Subtree Matching in Small Memory”, IEEE Transactions on Knowledge and Data Engineering,pp.1123-1137,2011.
- Jianhua Feng, Guoliang Li, and Jianyong Wang, “Finding Top-k Answers in Keyword Search over Relational Databases Using Tuple Units”, IEEE Transactions on Knowledge and Data Engineering,pp.1784-1194,2011.
- Ye Yuan, Guoren Wang, Lei Chen, and Haixun Wang, “Efficient Keyword Search on Uncertain Graph Data”, IEEE Transactions on Knowledge and Data Engineering,pp.2767-2779,2013 .
- Ruby Carlin GeorgewinSathiaseelan, SriramSitharaman, RaghavBabuSubramanian,RadhaSenthilkumar, “On Fly Search approach for Compact XML ”, IEEE International Conference on Recent Trends in Information Technology (ICRTIT),pp.347-351,2013 .
- Chandragandhi.S,Nithya.L.M, “Optimizing Fuzzy Search in XML Using Efficient Trie Indexing Structure”, IEEE International Conference on Recent Trends in Information Technology (ICRTIT),pp.496-501,2013.
- Wangchao Le, Feifei Li, AnastasiosKementsietsidis, and SongyunDuan, “Scalable Keyword Search on Large RDF Data”, IEEE Transactions on Knowledge and Data Engineering,pp.2774-2788,2014 .
- Bettina Fazzinga, Sergio Flesca, and Andrea Pugliese, “Top-k Approximate Answers to XPath Queries with Negation”, IEEE Transactions on Knowledge and Data Engineering,pp.2561-2573,2014 .
|