Keywords
|
| Robust Statistics – RANSAC - MATLAB |
INTRODUCTION
|
| The origin of robust statistics was step in to the eighteenth century, when the first rules for the rejection of outliers were developed. Following that in the next century, these rules were formalized and techniques for robustly estimating ‘means’ were used. Later on, estimators that down weight outliers were developed, during the first half of the 20th century, robustness of statistical testing was considered. [1] and [21] demonstrated the importance for robust methods and their work was considered as a breakthrough in robust. After few years later, [7] and [6] put forward the foundation of comprehensive theory of robust statistics. |
| The goal of robust statistics is to reduce the impact outliers and their methods try to fit the data as a bulk one, which assumes that the good observation outnumbers the outliers. By using the residuals, outliers can be identified that are large in the robust analysis. An important task afterwards is to ask what has caused these outliers and they should not be ignored, but have to be analysed and interpreted. |
| Robust statistics are used in computer vision for the past three decades and the most popular today are linked to old methods that are proposed to solve specific image understanding or pattern recognition problems. In that, some of them were rediscovered in past few years. Computer vision techniques have numerous practical applications, in which some of them being character recognition, industrial inspection, medical image analysis, remote sensing navigation, robot navigation, scene modelling, surveillance human identification activity analysis etc. |
| The main goal of computer vision is to mimic human visual perception. In the broader sense an equivalent task had been performed when the robustness of a computer vision algorithm is judged against the human observer performance. Even though the usual information is carried only by a small subset of data and/ or is significantly different from an already stored representation, robustness has the ability to extract the visual information of relevance for a specific task. |
| In this paper an attempt has been made to study the performance of RANSAC techniques through the simulated data with error tolerance under the various classical and robust methods such as LS, LMS, LTS and M-estimators. The various most widely used RANSAC techniques are briefly discussed in the section 2 and Section 3 deals with the classical and robust methods which are used to study the performance of RANSAC techniques. The result obtained through the simulation study is summarized in the section 4 and the discussion is in the last section. |
RELATED WORK
|
| The RANSAC algorithm is one of the most popular robust estimators in computer vision and their structure was proposed by [5]. It is simple and most effective techniques that are commonly applied to the task of estimating the parameters of model that may be contaminated by outliers. RANSAC is also a non-deterministic algorithm for the estimation of a mathematical model from observed data that contains outliers. The speed of RANSAC depends on two factors. The first one is the level of contamination determines the number of random samples that have to be taken to guarantee a certain confidence in the optimality of the solution and the next one is the time utilized to evaluate the quality of each of the hypothesized model parameters that are proportional to the size of the data set. Typically, numerous erroneous model parameters obtained from contaminated samples are evaluated and such kinds are consistent with only a small fraction of the data. The original RANSAC algorithm works in a hypothesis testing frame work, it randomly samples a minimum set of data point from which model parameters are computed and verified against all the data points to determine a fitting score and this process is repeated until a termination criterion is observed. The RANSAC finds with a certain probability, all inliers and the correspondence model by repeated drawing random samples. RANSAC, a robust estimator which gives a correct estimation of a scale of inliers that can be robust to more than 50% outliers and their performance is largely depends on the given scale or error tolerance. |
| A. M-estimator Sample Consensus (MSAC) and Locally optimized MSAC (LOMSAC) |
| The M-estimator sample consensus (MSAC), a generalization of the RANSAC estimator that is introduced by [20], mainly used to robustly estimate multiple new relations from point correspondences. MSAC adopts the same sampling strategy as RANSAC to generate reputed solutions but chooses the solution that maximizes the likelihood rather than just the number of inliers. One of the problems in RANSAC is that if the threshold T for considering inlier is set too high then the robust estimator can be very poor. Maximum likelihood estimation sample consensus (MLESAC) is a case of MSAC that yields a modest to large benefit to all robust estimations with absolutely no additional computational burden. The maximum likelihood error allows suggesting an improvement over MSAC. By locally optimization this MSAC changed into LOMSAC. |
| B. R-RANSAC (RANDOMIZED RANSAC) |
| A new randomized version of R-RANSAC proposed by [2] that increases the speed of model parameter estimation under a broad range of conditions, due to the randomization of the hypotheses evaluation step. The sample contaminated by outliers was shown that it was sufficient to test only a small number of data points to conclude with high confidence. The emphasized ideas of the R-RANSAC are that the most model parameter hypothesis evaluated is influenced by outliers. To avoid such erroneous models, a statistical test have to be perform on only a small number of data points .The hypotheses generation step proposes a model that the data points are either good or bad, the property of good is a hidden state that is not directly observable events, but it is statistically linked to it. The observable events are “data a point are or is not consistent with the model”. |
| The speed up of the R-RANSAC depends mainly on the probabilities of the two types of errors that committed in the pre-test, the rejection of an uncontaminated and the acceptance of contaminated model. |
| R-RANSAC used random sampling more thoroughly in contrast to them. It uses small amount of data, when RRANSAC counts inlier candidates, most RANSAC based approaches are need to tune variables such as the number of iteration. The variable should be adjusted again when the given data are modified. |
| C. N Adjacent Points Sample Consensus (NAPSAC) |
| Author [11] introduced the N Adjacent points sample consensus estimator. The algorithm of N Adjacent Points Sample Consensus (NAPSAC) focused on the efficiency of the sampling strategy. The idea is that inliers tend to be closer to one another than outliers, and the sampling strategy can be modified to exploit the proximity of inliers. This might bring efficient robust recovery of high dimensional models, where the probability of drawing an uncontaminated sample becomes very low even for data sets with relatively low contamination of outliers. |
| D. Locally Optimized RANSAC (Lo-RANSAC) |
| Lo-RANSAC proposed by author [3]. It has been observed that to find an optimal solution, the number of samples drawn in RANSAC is significantly higher predicted from the mathematical model. This is due to the incorrect assumption, that a model with parameters computed from an outlier-free sample is consistent with all inliers. The Locally optimized RANSAC based on the observation that virtually all models estimated from an uncontaminated minimal sample contain large fraction of inliers within their support. An optimization process starting from the so-farthe- best hypothesized model is therefore inserted into RANSAC. The algorithm was extensively tested on the problem of estimation of the two view relations from image point correspondences. Lo-RANSAC improves hypothesis quality by performing a local optimization step on the current inlier set every time a new best hypothesis is found. Other approaches aim to reject bad hypotheses early on. |
CLASSICAL AND ROBUST METHODS
|
| A. Least Square Estimator |
| Linear regression analysis is an important tool in most applied science including computer vision. The least squares (LS) method is one of the most widely used to estimates the parameter in linear regression methods and it has been used in many scientific fields for a long time. |
| The classical linear model can be described in the following form |
 |
| The ordinary least squares regression estimator can be written as |
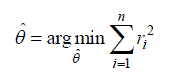 |
| The LS estimator is highly efficient and achieves optimum results under Gaussian distributed noise. Although the LS method has the advantages of low computational cost and high efficiency, it is extremely sensitive to outliers. |
| B. LMS and LTS Estimator |
| In the context of regression analysis many methods have been proposed, the two methods Least Median Square (LMS) and Least Trimmed Square (LTS) are still alive and widely used. [15] author Proposed the LMS and it is based on the idea of replacing the sum in least sum of squares formulation by a median. It finds the parameters to be estimated by minimizing the median of squared residuals corresponding to the data points. |
| The least median square estimate is as follows: |
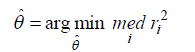 |
| The LMS method has excellent global robustness and high breakdown point. However, the relative efficiency of the LMS method is poor when Gaussian noise is present in the data. Rousseeuw noted that the LMS has a very low convergence rate [16].To compensate the deficiency Rousseeuw improved the LMS method by carrying out a weighted least square procedure after the initial LMS fit. The LTS method uses h data point (out of n) to estimate the parameters. The aim of LTS estimator is to find the h subset with smallest least squares residuals and use the h subset to estimate parameters of models. The LTS have less sensitive to local effects than LMS and also better statistical efficiency than LMS. The implement of the LTS method also uses random sampling because the number of all possible h subsets grows fast with n. Like LMS, the efficiency of LTS can also be improved by adopting a weighted least squares refinement as the last stage. |
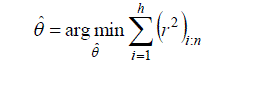 |
| C. M-Estimator |
| The maximum-likelihood type estimators (M-estimators) are well known among the robust estimators. The theory of M-estimator was firstly developed by Huber. They minimize the sum of a symmetric, positive-definite function of the residuals with a unique minimum at zero. |
| The M-estimator of the parameter are obtained by converting the minimization |
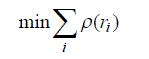 |
| into a weighted least squares problem which is handled by available sub routines. The weights depend on the assumed ρ function and the data. |
| M-estimators are generalizations of MLEs and least squares. In particular, the M-estimate of a is |
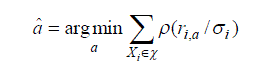 |
| Where ρ (u) is a robust loss function, σ2i is the variance. |
SIMULATION STUDY
|
| The simulation study has been performed to study the behaviour of various RANSAC methods under classical and robust methods such as LS, LMS, LTS and M-estimators. The data were generated with the model ax +by +c=0 where a2+b2=1 using MATLAB software with fixed threshold t = 0.2 and various sample sizes [n=100, 500, 1000] with error also consider here. The study has been performed in the context of number of inliers estimated by using the various RANSAC techniques and it is summarized in the TABLE I. |
| It is observed from the table except least square almost all other robust method estimated the number of inliers exactly when ε = 0.0. Number of inliers estimated by LS methods is around 90-95%. When ε increase LS method get mostly affected. While considering various RANSAC techniques, performance of NAPSAC is very poor to estimate the number of inliers under various models. No of inliers estimated by RANSAC and R-RANSAC methods provides the better result compare with other methods. |
CONCLUSION
|
| In this paper the behaviour of various RANSAC techniques such as RANSAC, R-RANSAC, MSAC, LO-MSAC, NAPSAC, LO-RANSAC discusses through a simulation study under various models LS, LMS, LTS and M-estimator. The study concluded that the robust models LMS, LTS and M-estimator provides better results when compare to least square with or without error. Among various RANSAC techniques RANSAC and R-RANSAC provides better solutions. One can apply this various RANSAC techniques and select proper robust models such as LMS, LTS, M-estimator and find better solution in the context of studying image processing application |
| |
Tables at a glance
|
 |
| Table 1 |
|
|
|
| |
References
|
- Alipio BC, David FC, Isabel RS, Juan CNM. Manuel AE. Comparison of batch, stirred flow chamber, and column experiments to study adsorption, Desorption and transport of carbofuran within two acidic soils. Chemosphere. 2012; 88(1): 106-120.
- Arnaud B, Richard C, Michel S. A comparison of five pesticides adsorption and Desorption processes in thirteen contrasting field soils. Chemosphere. 2005; 61(5): 668-676.
- Chunxian W, Jin-Jun W, Su-Zhi Z, Zhong-Ming Z. Adsorption and Desorption of Methiopyrsulfuron in Soils. Pedosphere. 2011; 21(3): 380-388.
- Chunxian W, Suzhi Z, Guo N, Zhongming Z, Jinjun W. Adsorption and Desorption of herbicide monosulfuron-ester in Chinese soils. J Environ Sci. 2011; 23(9): 1524-1532.
- Christine MFB, Josette MF. Adsorption-desorption and leaching of phenylurea herbicides on soils. Talanta. 1996; 43(10): 1793-1802.
|