Keywords
|
| Clickthrough Data; Implicit Response Mechanism Ranking; Information Recovery; Search Result Reorganization; Restructuring |
INTRODUCTION
|
| Web Mining is the Lively and Popular Research Field Web Removal is a very hot investigation topic which combines two methods of Data Mining and World Wide Web. The Web Removal research are belongs to Removal research are belongs to Numerous Communities Such as the Database, Artificial Intelligence and Information Recovery. We Categorize Web Mining into three parts: Web Structure Mining, Web Gratified Mining, and Web Usage Mining. Web gratified mining focuses on the Retrival and Discovery of the useful information fillings or data or documents from the Mesh. Web structure emphasizes to the detection of how to model the fundamental link structures of the Web. Web usage removal is relative independent, but not remote, category which mainly labels the techniques that learn the user's usage pattern and try to forecast the user's behaviors. Web Removal is one which helps in doing Commercial, Education and Company. Web is a large Dynamic, Diverse and Formless Data Repository field. Web a large, shorttempered, miscellaneous, dynamic and typically unstructured data Repository which supplies vast quantity of information .Existing search trains such as Google, Yahoo and Amazon often reappearance a long list of search results, hierarchical by their relevancies to the stated query. Web users have to go through the list and inspect the titles, tags and (short) snippets successively to identify their required consequences. This is a time consuming task since manifold sub-topics of the given query are varied together. |
LITERETURE SURVEY
|
| In an web based request, queries are submitted to the Search Trains to represent information wants of the user yet some queries may not precisely represent users’ specific information wants since it is vague and may cover a broad topic and different user may need to get info on different aspects when they succumb the same query. For example Fig 1 shows the outline of our approach .when the query “The Sun” is succumbed to the search engine ,some user are in need of Indian Newspaper, some are in need of usual language about Sun. hence it is essential to capture the goals of different operators in the case of Information Retrieval. the main advantage of implication and analysis of user search goals is as |
| shadows First, we can restructure the web hunt results according to the search results with the same search goals hence users with different search goals can easily find what they need. Second, user search goals represented by some keywords can be used in query reference; it helps the users to form the queries more exactly. Third, the deliveries of user search goals can be valuable in the application such as re-ranking web search results that contain dissimilar user search goals. It can be getabridged in to three classes: |
| 1. Query Organization, |
| 2. Search Result Re organization, and |
| 3. Session border Detection. |
| In the existing system all the feedback meetings of a query are first removed from user click-through logs and mapped to pseudo-documents.. Since we do not distinguish the accurate number of user hunt goals in advance, So several different standards are tried and the optimal worth will be determined by the response from the bottom part. In the bottom share, the original search results are efficient based on the user hunt goals inferred from the upper part. Then, evaluate the presentation of restructuring search consequences by this evaluation criterion Classified Regular Precision CAP. And the assessment result will be used as the response to select the optimal number of user hunt goals in the higher part. |
PROPOSED SYSTEM
|
| The existing feedback meeting consists of both clicked and un-clicked URLs and ends with the last URL that was clicked in a solitary session. It is used to find what the user need on that time based on this clicked data current feedback consists. Most document-based approaches focus on analyzing users’ clicking and browsing performanceslogged in the users’ clickthrough data. On Web search trains, click through data are significant implicit feedback device from users. An example for the clickthrough data for the enquiry “apple,” which contains a list of hierarchical search results obtainable to the user, with the ID on the results that the user has clicked on[2]. It rearranges the result both founded on user interest and most clicked URL links. The user attention is not considers by the single session or last hunt session. In proposed system make a user profile and monitor users search meeting any time and also after anywhere. The advantages of our future system was we can change the attention of the User animatedly, User interest based search result will be get absorbed first, URL ranking in takes place, Hunt history will be universal Process. |
FRAMEWORK OF OUR APPROACH
|
| The framework is getting divided into two parts: |
| 1) In the first part, all the response session get extracted from the user Clickthrough logs and get mapped to the pseudodocuments. Gathering has been done by means of Keywords. Since we does not know the careful number of User search goals inloan several different values are been strained and then the optimal worth will be get determined from the lowest part. |
| 2.)In the second part, Unique Search Results are get Efficient based on the User Search goals incidental from the upper partShown in the fig 2.fig 2 shows the URL that has been get clicked so far or get just skimmed from top to bottom will be confidential therectangular box and which has been outdoor the box has not yet watched yet(other links) |
| The main aim of our Future system is one which creates the User Profile for each separate and it has been get genuine by the client. The Interest of the user get listed in the database, since user interRest will be get changed dynamically[5]. Based on that database will be get updated often. First the user enter the keyword if it is already in the database will be get check by the server .Based on that it will be get showed by the client Rearrangement is get performed and for each user attention ranking will also be get done. Based on the Rearrangement results it is one Ranking is get did .Ranking is done on the User attention .Hence the very system has been get applied. It is get briefly clarified in the diagram shown in the Fig 3.It shows the employed principle of the System founded on the keyword given by the user. and check the file and update the interest. |
SYSTEM IMPLEMENTATION
|
| There are four units in this system like capturing feedback meetings, building pseudo-documents, gathering pseudodocuments, restructuring based on web search results. |
| Given anvague query, q. When the user submits query search results are obtained on the basis of that query, say |
| S={s1,s2,s3,s4,…,sn} |
| First, user will click on some of the results,say{s1,s4,s5} and the click order obtained from this is,{s1=1,s4=2,s5=3}. So, the clicked order of resultsis as follows, |
| {s1=1,s2=0,s3=0,s4=2,s5=3,….sn=0} |
| One feedback session covers URL’s till the last clicked URL. These response sessions are represented by, {fs1,fs2,…fsn}. Map these feedback meetings to pseudo documents to find out the user goalmouths. so, pseudo documents are created as,{pd1,pd2,..pdn}. Finally, cluster these pseudo-documents to find out resemblance, |
| {pd1=sg1,sg2,…sgn|pd2=sg1,sg2,…sgn|…|pdn=sg1,sg2,..sgn} |
| Similarity computation, simi,j=cos(Ffsi,Ffsj) |
| Where, Ffs is the feature picture of feedback session. After gathering all the pseudo-documents, each cluster is considered as one user hunt goal. Evaluation based on web hunt results |
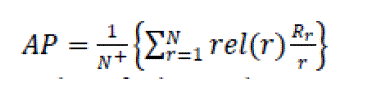 |
| N+ is number of relevant documents r is rank N is total number of saved documents rel() binary function on the relevance of given rank Rr is number of relevant saved documents VAP(voted AP) is the AP of the class with more clicks as votes. Here URL's in the single meeting are restructured into two classes, bold-faced and unbold faced. VAP is still unacceptable. So, there should be arisk to avoid categorizing search results into too many lessons. |
EVALUATION CRITERION
|
1: AVERAGE PRECISION
|
| A possible evaluation standard is the average precision (AP) which evaluates according to user understood feedbacks. AP is the average of precisions which is calculated at the point of each relevant document in the hierarchical sequence, shown in |
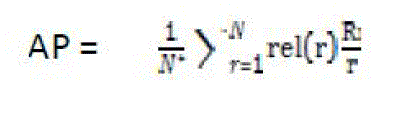 |
| Where |
| N is the number of relevant (or clicked) leaflets in the retrieved ones, r is the rank, N is the total amount of retrieved documents, rel(r) is a binary function on the significance of a given rank,andRr is the number of pertinent retrieved documents of rank r or less. |
2: VOTED AP (VAP)
|
| It is calculated for purpose of rearrangement of search results classes i.e. dissimilar clustered results classes. It is same as AP and calculated for class which having more clicks. |
3: RISK
|
| It is the AP of the class counting more clicks? There should be a risk to avoid categorizing search results into too many classes by error. So we propose the Risk. |
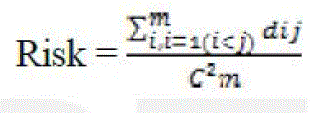 |
4: CLASSIFIED AP (CAP)
|
| VAP is extended to CAP by presenting combination of VAP and Risk. Secret AP can be calculated by using the formula, as follows: |
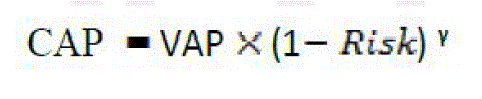 |
CONCLUSION
|
|
|
| In this paper, a novel method has been proposed to infer user search goals for a query by gathering its feedback sessions represented by pseudo-documents. First, we Present feedback sessions to be analyzed to infer user search goals rather than hunt results or clicked URLs. Both the clicked URLs and the un clicked ones before the last click are considered as user implicit responses and taken into account to concept feedback sessions. Therefore, Feedback sessions can reflect user info needs more professionally. Second, we map feedback sessions to pseudo documents to approximate goal texts in user attentions. The pseudodocuments can enrich the URLs with extra textual contents including the titles and scraps. |
| |
Figures at a glance
|
 |
 |
 |
| Figure 1 |
Figure 2 |
Figure 3 |
|
| |
References
|
- Leuski A. and Allan J. Improving Interactive Retrieval by Combining Ranked List and Clustering. Proceedings of RIAO, College de France, pp. 665-681, 2000.
- S. Beitzel, E. Jensen, A. Chowdhury, and O. Frieder, “Varying Approaches to Topical Web Query Classification,” Proc. 30th Ann. Int’l ACM SIGIR Conf. Research and Development (SIGIR ’07),
- H. Chen and S. Dumais, “Bringing Order to the Web: Auto-matically Categorizing Search Results,” Proc. SIGCHI Conf. Human Factors in Computing Systems (SIGCHI ’00), pp. 145-152, 2000.
- C.-K Huang, L.-F Chine, and Y.-J Oyang, “Relevant Term Suggestion in Interactive Web Search Based on Contextual Information in Query Session Logs,” J.Am.Soc. for Information Science and Technology.
- T.Joachims, “Evaluating Retrieval Performance Using Click-through Data,” Text Mining, J. Franke, G. Nakhaeizadeh, and I. Renz, eds., pp. 79- 96, Physica/Springer Verlag, 2003.
- T. Joachims, L. Granka, B. Pang, H. Hembrooke, and G. Gay, “Accurately Interpreting Clickthrough Data as Implicit Feedback,” Proc. 28th Ann. Int’l ACM SIGIR Conf. Research and Development in Information Retrieval (SIGIR ’05), pp. 154-161,2005.
|