International Journal of Innovative Research in Computer and Communication Engineering
ISSN ONLINE(2320-9801) PRINT (2320-9798)
ISSN ONLINE(2320-9801) PRINT (2320-9798)
Nivi A.N 1, Vanitha S 2, Saranya K.R 1, Sivaranjani B 1, Kavitha S 1
|
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Innovative Research in Computer and Communication Engineering
Internet of things is in its peak in today’s world. The web search is the widely performing task in the internet world. When the query is searched over web should provide the relevant information to the users. The irrelevant results may annoy the users and hence the efficiency of the query search should be improved. To improve the search, personalized web search framework is proposed to retrieve the data based on user’s interest. When the information is retrieved based on user’s interest, user’s profile will be publicly available. In this paper, the User’s profile is also protected to handle privacy threats using generalization technique with Greedy Discriminating Power and Greedy Info Loss algorithm. The efficiency of search is improved by transferring the query with user’s profile to the web server to retrieve the results. If the results are not satisfied to the user then the re-ranking technique is proposed to retrieve the most relevant search results.
KEYWORDS |
| personalised web search, user’s profile protection, re-ranking, generalization, search utility |
I. INTRODUCTION |
| Web search is mostly performed by all the people to retrieve the useful information from the search engine. The search may return irrelevant results that are not satisfied to the users. This irrelevance is due to variation in user’s perspective and also due to text ambiguity. This issue is handled with personalized web search framework [1] using profile based method. In profile based method [2], the user’s profile is created based on user’s search interest via queries [3],[4],[5] and browsing histories [6],[7]. It improves the quality of data retrieval and user’s satisfaction along with re-ranking technique [8]. The created user profile should be protected to overcome the privacy threats using generalization algorithms which also help to improve the data utility. |
| A. Security Threats: |
| There are privacy threats which lead to the solution with generalization algorithms the major threat is identity disclosure of an individual as explained in [9]. The identification of individual is done with the help of sensitive values from user’s profile while transferring the search query and user’s profile to the web server. This problem of pseudo identity, group identity, no identity and no personal information are solved in [10], [11], [12]. The personalized privacy protection is given with generalization algorithm which is introduced in Privacy Preserving Data Publishing (PPDP) [13]. This paper further consists of Related Work in section II, Personalized web search framework in section III, Experimental Settings in section IV and Conclusion and Future Work in section V. |
II. RELATED WORK |
| Personalized web search is mainly focused on better data utility and privacy. We proposed user’s profile protection with this framework and efficiency of search results is increased with re-ranking technique [14], [15], [16]. The most of the search engines use re-ranking technique for image retrieval. The user’s profile generation of this framework is in hierarchical structure with weighted graph such as ODP [2], [17], [18]. The performance of the personalized web search is estimated with metrics like average precision [19], [20], rank scoring [21] and average rank [4], [22]. Identity disclosure is described in [9]. In this paper we have analysed the threat with privacy preserving data publishing [13] algorithms. |
III. PERSONALIZED WEB SEARCH FRAMEWORK |
| The personalized web search is a framework where the user profile is protected during the search. The PWS is used to search the most relevant information from the web server using both the query and the user’s profile. This is a profile based search in which user’s profile is created with the cookies, browsing and query histories. These created profiles should be protected with the generalization techniques because it may be available on public repository and used by others as background knowledge. |
| A. User’s Profile Protection: |
| The user’s profile is generated with the details of user’s browsing history, cookies and also based on the query. The profile can be generated in two phases, online and offline phases and it adopts a hierarchical structure. Consider the following figure 1 which is a general taxonomy of search from which the user profile is generated represented in figure 2 with the sensitivity of topic.c |
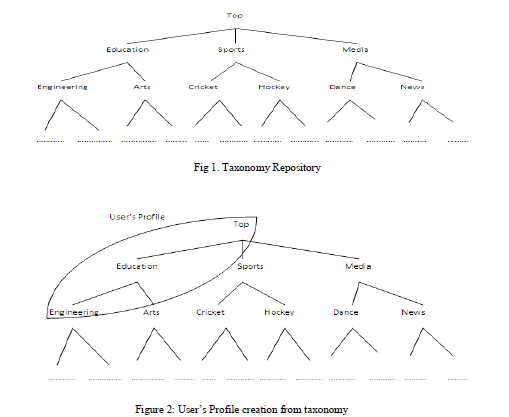 |
| 1) Offline Phase |
| The original user profile and customized privacy are constructed in the offline mode. |
| Profile Construction |
| The user’s profile is constructed from the hierarchy H of the data based on user interests. It is a subset (S) of H where SeH. to detect the respective topic in S for every document D, a naïve method is used to calculate the frequency of words (w) in topic (t) for a Naïve Bayesian Classifier (nb) using eq 1. |
 |
 |
Generalization of profile |
| The profile generalization is implemented to preserve the privacy of users profile during the search. It is done based on the metrics of utility and privacy with generalization algorithms. |
| B. Generalization: |
| The critical metrics for generalization and two generalization algorithms called Greedy Discriminating Power and Greedy Info Loss are proposed in this section. |
| 1) Metric for utility: |
| The quality of search is predicted with the utility metric because the quality of search depends on the user’s search in the personalized web search engine. We estimate the Discriminating Power of a query for a profile instead of utility prediction when the specific topics are observed more or the topics are similar or a few topics are concentrated more. The utility metric is estimated with information content which identifies the specific topic using eq.3 and profile granularity that calculates the probability distribution using eq.4. |
 |
| 3) Greedy Discriminating Power Algorithm: |
| The Greedy Discriminating Power Algorithm is used for generalizing the data. It is a greedy algorithm which generalizes the data in bottom up manner in the hierarchical structure of the user’s profile. It starts from the leaf node and the pruning of the profile’s data is done with repeated iteration for better data utility and privacy of the user’s profile. For all user profiles it requires re-computation for pruning from leaf node to root node. The disadvantage of this algorithm is it requires more memory space and computations. |
| 4) Greedy Info Loss Algorithm: |
| The Greedy Info Loss Algorithm is used for more efficient generalization which uses heuristics for pruning. Here the priority of user’s profile is maintained in the queue for pruning till the end of all iterations for generalizing the user’s profile. It also identifies the specific topic of the user’s profile search from the pruned leaf. The computation is simplified than Greedy Discriminating Power algorithm. |
| C. Re-ranking Technique: |
| Re-ranking is an efficient method used to retrieve the results from the search engines. It is mainly used in image retrieval where a query yields a set of images as result and if the result is irrelevant further search takes image from already retrieved results as a query for refined search and more relevant search results. The comparison of input query image with others in the database is done with the semantic features of the image that avoids irrelevant results to be retrieved. |
IV. EXPERIMENTAL SETTINGS |
| In this section, the experimental setup and experimental results are explained in detail. |
| A. Experimental Setup: |
| An online shopping website is created for personalized web search using Java and HieldSQL with JDBC connectivity is shown in fig 4. When the registered user login and search for the desired shopping his/her user profile is generated using their search query and previous searching histories. Once the user profile is created, it is generalized using GreedyDP and Greedy IL algorithms. The generalized user profile along with the query is send to the web server. The obtained results can be ranked again if it is not satisfied to the user using re-ranking technique. The ranked query will be send to the sever and the most relevant results are retrieved without losing the user’s privacy. |
 |
 |
V. CONCLUSION AND FUTURE WORK |
| The web search is a major task in the internet. The search history and queries of the user are saved by the search engines. The saved data can be accessed by the users as a profile for analysis or to provide other relevant data for users. The browsing histories and search queries of a user creates a user’s profile and it should be protected to avoid privacy threats. From our experiment, it is observed that Greedy Info Loss algorithm works better for generalization of user’s profile that protects the identity disclosure of a user. The data retrieval is made efficient with re-ranking technique which retrieves more relevant results for the user’s query. |
| In future, the other privacy threats can be handled with efficient algorithms and the scalability of data can be analyzed with personalized web search. |
References |
|