Keywords
|
| VMM(Virtual Machine Monitor),APM(Actively used Physical Machine),LNM(Local Node Manager),IDV(Intelligent Desktop Virtualization), SLA(Service Level Agreement),EC(Elastic Computing) |
INTRODUCTION
|
| The Flexibility and lack of capital investment is appealing to a big sector of business community. The proposed system is a novel approach which provides dynamic resource allocation using concept of virtualization. The Proposed system use virtualization technology which multiplex no of virtual resources onto to the physical hardware. Our system consists of five modules which accomplish to major task examining the utilization of each physical machine and maintain green computing. In this system we introduce the concept of skewness and Hot Spot mitigation. The machines which are in Hot Spots will automatically get removed to make the system as green as possible. [1][2][3] |
| The approach which we are implementing here is a novel approach which decides the resource allocation to the users depending upon their premium membership. This means we are using Cost based priority approach for dynamic resource allocation.Green computing is unique as the number of PMs used should be diminished as long as they can still convince the needs of all Virtual Machines running on the system. PMs which are not working can be turned off to save energy. Simply make better performance over cloud surroundings by optimizing the number of PMs in use. The area of Green computing is also becoming increasingly essential in a world with partial energy resources and an everrising request for more computational power.In this paper we present the design and implementation of automated dynamic resource allocation system in green cloud environment. Our Proposed System provide a tradeoff between skewness and green computing. |
| We have implemented following things. |
| • We develop a dynamic resource allocation system which restrict the overloaded system effectively thus minimizing the no of Physical machines used |
| • We introduce the concept of skewness which measures the unevenness in the utilization of Physical Machines. By minimizing the skewness we increase the performance of the system |
| The rest of the paper is divided into following parts. Second part gives the description of the system, third part gives the concept of skewness algorithm, fourth part gives Hot Spot mitigation and fifth part gives the description of Green Computing. |
RELATED WORK
|
| Christopher Clark [4] proposed the intend options for drifting operating systems running services with live constraints, focusing on data center and bunch or cluster environment. They have also initiated and analyzed the notion of writable working set, and presented the blueprint, implementation and assessment of soaring performance OS migration built on crest of the Xen VMM. They have investigated an additional promote allowed by virtualization: that of live OS migration. Immigrating an entire OS and all of its applications as one unit permitted us to avoid many of the difficulties faced by process-level migration approaches.In particular the narrow interface between a virtualized OS and the virtual machine monitor(VMM) makes it simple to avoid the problem of residual dependencies[5] in which the original host machine must linger available and network-accessible in order to over haul certain system calls or even memory accesses on behalf of migrated processes. Michael Nelson [6] proposed a devise and implementation of a system that utilizes virtual machine technology to provide fast, transparent application migration. |
| Carl A. Waldspurgeret [7] proposed a number of novel ESX Server mechanisms and policies for administrating memory. One of their proposed methods was ballooning approach, which has recovered the pages considered smallest amount valuable by the operating system functioning in a virtual machine. Secondly, an idle memory tax approach has attained proficient memory utilization while maintaining performance separation guarantees. Finally, Content-based page sharing and hot I/O page remapping approaches have exploited the transparent page remapping to eliminate redundancy and reduced copying overheads. All the four approaches were combined to efficiently maintains virtual machine workloads that over commit memory. Norman Bobroffet introduced a forceful server migration, consolidation algorithm and proposed Dynamic Allotment of Virtual Machines for Managing SLA Violations [8].The above designated algorithm has been performed significant enhancement over fixed server consolidation in reducing the amount of obligatory capacity and the rate of service level agreement violations. The greedy resource allocation algorithm has been modified in [9] by Jeffrey S. Chaseet.al. Their proposed system is based on a monetary approach to managing shared server resources, in which services “bid” for resources as a function of distributed performance. The system often monitors load and plans resource allotments by estimating the value of their effects on service performance. |
| Tathagata Daset.al proposed a system [10] to save desktop energy by virtualizing the user’s desktop computing situation as a virtual machine (VM) and then migrated between the user’s physical desktop machine and a VM server, depending on whether the desktop computing situation was actively used or idle. Thus, the user’s desktop environment was “always on”, maintaining its network present fully even when the user’s physical desktop device was switched off and thereby saved energy.YuvrajAgarwalet.al explained the structural design and implementation of Sleep server [11], a system that enabled hosts to changeover to such low-power sleep states while still maintaining their application’s supposed network presence using an on stipulate proxy server. NiltonBilaet.al proposed a fractional VM Migration technique [12] that transparently migrated only the working set of an idle VM. Partial VM migration arche type can deliver 85% to 104% of the energy savings of full VM resettlement, while using less than 10% as much network resources, and providing migration latencies that are two to three orders of degree smaller. Super computers are adequately powerful to use virtualization to presence the delusion of many smaller virtual machines (VMs), each running a separate operating system example. In [3], the authors presented a VMM called Xen hypervisor (116 VMM), which has allowed manifold commodity operating systems to share traditional hardware in a secure and resource managed manner, but without suffering either performance or functionality. This was done by providing an idealized virtual machine thought to which operating systems such as Linux, BSD (Berkeley Socket Distribution) and Windows XP, can be ported with minimal effort. The structural design of the system is presented in Figure 1. Each PM runs the Xen hypervisor (VMM) which wires a privileged domain 0 and one or more domain U. Virtualization of computing resources has been an increasingly regular practice in recent years, specifically in data centre environments. This has helped in the rise of cloud computing, where data centre machinists can over-subscribe their physical servers through the use of virtual machines in order to enlarge the return on investment for their infrastructure. Overload evasion and Green computing parameters are playing chief of better resource allocation over green cloud background. There is an intrinsic trade-off between the two goals in the face of shifting resource needs of VMs. For overload evasion, we should keep the utilization of PMs low to reduce the possibility of overload in case the resource needs of VMs increase later. For green computing, we should keep the utilization of PMs reasonably high to make efficient use of their energy [13]. |
PROPOSED SYSTEM
|
| A. Design Considerations: |
| The architecture of the system is shown above in Figure 1. Each Physical Machine runs a Xen Hypervisor(VMM) which consist of Dom 0(Usher LNM,MM Allotter),Dom U(Web PM)[3].The multiplexing of VM to PM is managed by Usher framework. Each node runs an Usher Local Node Manager which runs on domain 0. The main task of this node is to collect all the resource usage statistics of that VM. The usage of memory within VM is not visible to user. The size or capacity of each virtual machine is decided by the WS prober [9].The resource usage statistics collected at each node is forwarded to Usher Central Controller (Usher CTRL) where our VM Scheduler runs. The scheduler runs several components like predictor, Hot Spot Solver, Cold Spot Solver and Migration List.The hot spot solver in our VM Scheduler detects if the resource utilization of any PM is above the hot threshold (i.e., a hot spot). If so, some VMs running on the system will be migrated from the list. The cold spot solver checks the overall temperature of the Physical Machines is below thethreshold valueto ensure green. If some of the PMs above the threshold value then they could potentially be turned off to save energy. It help in identifying set of PMs whose utilization is below the cold threshold (i.e., cold spots) and then attempts to migrate away all their VMs. It then compiles and collect a migration list of VMs and passes it to the Usher CTRL for further execution. |
| Earlier Priority based resource allocation failed to concentrate on both phase overload avoidance and green computing. We made minor changes over resource allocation phase in cloud medium .Our supplement stuff always focuses resource allocation under cost based aspect alone. Resource allocation is used to assign the available resources based on premium membership. Even though keep an eye over "priority based dynamic resource allocation and hot spot mitigation". It's a new kind of approach for Green Cloud Computing Environment. Cost based resource allocation doesn’t require the detailed level of analysis and value measurement necessary to employ a value-based resource allocation strategy. Our novelty approach of the cost based resource allocation algorithms over cloud computing never affect green environment. |
| B. Skewness Algorithm |
| We introduce the concept of skewness measure the unevenness in the utilization of multiple resources on a Physical Machines. Let n be the number of resources we consider and ribe the utilization of the ith resource. We define the skewness of a PM p as: |
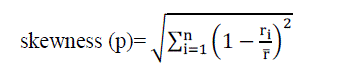 |
| Where r is the average utilization of all resources for PM p. In practice, not all types of resources are performance critical and hence we only need to consider critical resources in the above calculation. By reducing the skewness, we can combine different types of jobs nicely and improve the overall utilization of PM resources. |
| C. Detecting Hot Spots and Cold Spots |
| Our algorithm executes periodically to evaluate the resource allocation status based on the predicted future resource demands of VMs. We define a PM as a hot spot if the utilization of any of its resources is above a hot threshold. This indicates that the PM is overloaded and hence some VMs running on it should be migrated away. The temperature of a hot spot p is defined as the square sum of its resource utilization beyond the hot threshold. |
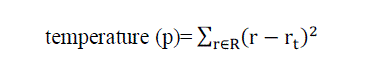 |
| Where R is the set of overloaded resources in PM p and r?? is the hot threshold for resource r. (we consider only overloaded resources for calculation). The temperature of a hot spot reflects degree of overloading of a PM. If a PM is not a hot spot, its temperature is zero. |
| We define a PM as a cold spot if the utilizations of all its resources are below a cold threshold. This indicates that the PM is mostly idle and liable to get turn off to save energy. However, implement that only when the average resource utilization of all actively used PM (i.e., APMs) in the system is below a green computing threshold. A PM is actively used if it has at least one VM running. |
| Otherwise, PM is treated as inactive. Different types of resources can have different thresholds. For example, let us define the hot thresholds for CPU and memory resources to be 90% and 80%, respectively. Thus a PM is a hot spot if either its CPU usage is above 90% or its memory usage is above 80%. |
| D. Hot Spots and Cold Spots Mitigation |
| We arrange the list of hot spots in the system in ascending order of temperature. Our goal is to remove all hot spots if possible. For each PM p, we first decide which of its VMs should be migrated away. We do sorting of the Virtual Machines based on the resulting temperature of the PM so that Virtual Machines having high temperature is migrated away. We aim to remove away the VM that can increase the PM’s temperature the most.If two VM have same temperature we select the one whose removal can reduce the skewness of the PM the most. |
| For each VM in the list, we search if we can find a destination PM to accommodate it. The PM must not become a hot spot after accepting this VM. Among all such PM, we select one whose skewness can be reduced the most by accepting this VM. |
| E. Green Computing |
| When the resource utilization of active physical machines is too low, some machines have to be turned off to save energy. This concept is implemented in our green cloud computing algorithm. The main task here is to reduce the number of active PMs during low load without compromising performance either now or in the future. |
| Our green computing algorithm is invoked when the average utilizations of all resources on active PMs are below the green computing threshold. We arrange the list of cold spots in the system based on the ascending order of their memory size. |
| Since we need to migrate away all its VMs before we can shut down an under-utilized PM, we define the memory size of a cold spot as the aggregate memory size of all VMs running on it. Remember that our proposed System assumes all VMs connected to share back-end data storage. |
| For a cold spot p, we check if we can move all its VMs somewhere else. For each VM on p, we try to search a destination PM to accommodate it. The resource utilizations of the PM after accepting the VM must below the warm threshold. While we can save energy by merge under-utilized PMs, Overloading of PM can create problem so warm threshold is implemented to solve that problem. |
| If multiple PMs are below the warm threshold and satisfy the above criterion, we prefer that which is not a current cold spot. This is because when we increase load on a cold spot it reduces the chances that it can be eliminated. Moreover, we will accept a cold spot as the final destination server if necessary. Now things are equal, we select a destination server whose skewness can be reduced the most by accepting this VM. If we can search destination servers for all VMs on a cold spot, we can collect the sequence of migrations. Green computing is initiated only when the load in the system is low. |
CONCEPTS PSEUDO CODE OF SCHEDULING ALGORITHM
|
| A. Scheduling Algorithm |
| In this system we first create the physical machines and then allocate the number of jobs which user wants to run. When the jobs are decided we allocate the resources to the host depending upon their priority which is based on the cost. After success full allocation of the jobs we search for the hot spot and mitigate them from further cycles of resource allocation that means those PM which are in hot spot will not take part in further upcoming cycles. The algorithm of the system is given below. |
| Algorithm:- |
| Begin: |
| To compute and assign priority for each request based on cost value and allocate resources to each service |
| Step 1:[ Generate the user data i.e. User Id, User Name, Host Name, E-mail, Phone No, Membership Duration] Insert all values into the table of database. |
| Step 2: [Generate Physical Machines] Physical Machines generated with Machine ID, Machine Name and Capacity. |
| Step 3: [Generate Random Client Request] Depending Upon the capacity of the PM No. of Jobs are allocated] Works Table get created for jobs which contain Work ID, Categories, Size, Duration. |
| Step 4: [Dynamic Resource Allocation] Depending upon Cost based priority resources are allocated. Resource Allocation contains three tables Resource Allocation table, Skewness table and Overall temperature. |
| • if (skewness (machine_id)>base value) |
| [The machine is said to be utilized depending upon how much skewness exceed base value] |
| else |
| [Machine is not utilized] |
| • if (temperature(machine_id)>threshold value) |
| [machine is in HOT SPOT ] |
| else |
| [machine is in COLD SPOT] |
| Step 5: [Green Computing] The machines which are in HOT SPOT will get eliminated from the next phase of resource allocation. |
| if (machine is in hot spot) |
| [Machine get eliminated for cooling because of heavy carbon emission violating Green computing norms] |
| Else |
| [Machine remain available for next cycle of resource allocation] |
| End |
SIMULATION AND RESULTS ANALYSIS
|
| We use C# to bulid our simulator which consist of 7 different modules to implement the task. These 7 different modules are as follows |
| • Creation of Physical Machines |
| • Resource Allocation |
| • User Creation |
| • User Deletion |
| • Hot Spot and Cold Spot detection Green Computing |
| A. Create Physical Machines |
| The Physical Machines contains VM Scheduler, USHER Framework for Resource Allocation. It is up to the Programmer or Service Provider that how many machines he wants to create. The table which contains description about physical machines contains three columns Machine ID, Machine Name and Capacity. Capacity determines how many requests can be handled by each Physical Machine in Parallel Execution. |
| B. Generate Random Client Request |
| The maximum no. of client request which can be generated at a given time this is depend upon the no of physical machines created. In this execution we can give 140 jobs for resource allocation at different pm for different resources. The table which get created consist of four columns and 140 rows. Some of the 140 rows shown on next page. |
| C. Resource Allocation |
| In the resource allocation phase the resources are get allocated to different physical machines with the help of LNM (Local Node Manager) and VM Scheduler. As the LNM take the responsibility of accessing resources, VM Scheduler takes the responsibility of Hot Spot Mitigation and restoring the concept of green computing. In the resource allocation phase we get three tables: |
| • Resource Allocation Table |
| • Over All Skewness |
| • Over All Temperature |
| 1) Resource Allocation Table |
| The resource allocation table is shown in TABLE III |
| The table consists of six different columns: |
| • PM Name: This column gives the detail of the Physical Machine |
| • Process Server: The Server which allocate resources to different PM |
| • Host ID/Host: ID of the host who is generating the request |
| • User: Website address of the user as the request is being handled |
| • Temperature (for green computing): Temperature of the machine this gives the initial temperature. The initial value is assume to be 0.05 |
| • Skewness: It measures the unevenness in the utilization of the PM. |
| 2) Over All Temperature |
| This table consist of two columns PM and Temperature. The temperature which is being displayed shows the final temperature after execution. |
| In the next cycle all the PM which are in hot spot will be removed that means they will not take part in the further resource allocation. |
| 3) Over All Skewness: |
| This table shows the utilization of PM. Some machines which are overloaded have a very high skewness factor in comparison to normal loaded machines |
| 4) Detecting Hot Spot and Cold Spot |
| After the success full allocation in the first cycle some machines get over heated due to which they comes in Hot Spot .They are removed from the list for next cycle of resource allocation. The Table VI shows name of the machines which are in cold threshold and which are in hot threshold. |
| In this table first four machines are in Cold Threshold and Next for are in Hot Threshold. So these machines are further removed from the next phase of execution. |
| E. Green Computing |
| In this segment we try to find out the time taken by the machines which are in hot spot. This step will help in preserving the green computing since we will have an idea that how much these machines are over loaded. |
| F. User Deletion |
| The last module is user deletion in this module we delete those user which no longer take part in further executions. Only those users are deleted who does not need any more resources for any further executions. The user deletion form contains User ID, User Name, Host, Email ID, Phone Number, Membership and Amount. Phone number and Email ID are very important for deletion. User Id once allocated to a user will not be allocated to anyone else even after the user id being deleted. |
SECOND PHASE OF EXECUTION
|
| A. Available Machines: |
| This section shows the list of available machines after first cycle of execution. Since the first user was having better premium membership than second user that’s why in the next cycle there were machines of first user.The available machines are then used for the resource allocation to the users and after the successful allocation we see again that how many machines are there in hot spot and how many in cold spot. Then again we click on the link “view available machines” to check how many machines are available.The system checks that if there are sufficient machines for resources allocation then next cycle of resource allocation starts otherwise system tell us to start the process again. |
| B. Resource Allocation of Available Machines: |
| This section shows resource allocation table, Skewness table and Temperature table after second cycle of dynamic resource allocation . The Table No Viii Shows How The Resource Are Dynamically Allocated To Different Pm Using Process Serverand It Also Shows The Temperature During The Time Of Execution.Initial Skewness Is 1 Which Shows During The Time Of Start Of Execution All 4 Machines Are Evenly Utilized. |
| C. Skewness table of second phase: |
| The Skewness Table shows the utilization of 4 machines after the successful allocation of all jobs by the 4 PM. This table given below shows Machine 4 is heavy utilized,which causes it to be in Hot Spot. |
| D. Temperature Table Of Second Phase: |
| This table shows which machines are in Hot Spot and which in Cold Spot ,The machines having temperature greater than 0.5 are in hot spot and are not allowed in further execution. |
| When all the jobs are allocated successfully and there are no more enough machines for next cycle of resource allocation then we have to start the system again. |
CONCLUSION AND FUTURE ENHANCEMENT
|
| Our proposed system is a novel approach which is used for dynamic resource allocation using Cost based Priority .In this system we have implemented modules to measure the skewness of physical machines and Hot spots and Cold spots.We have also tried to implement the concept of Green Computing by omitting those systems which are in hot spot for further cycles of resource allocation. |
| Green Computing is a new concept and it is being implemented by us in cloud environment . In order to achieve this some algorithms have been used which were discussed earlier.In Future we can implement Load prediction Module which will do the analysis and prediction of upcoming load on the machines and take the decision accordingly.This will help in avoiding the PM to get Over Heated and they also will not go in Hot Spot. |
| |
Tables at a glance
|
 |
|
|
|
|
| Table 1 |
Table 2 |
Table 3 |
Table 4 |
Table 5 |
|
|
|
|
|
| Table 6 |
Table 7 |
Table 8 |
Table 9 |
Table 10 |
|
| |
Figures at a glance
|
 |
| Figure 1 |
|
| |
References
|
- Barham,P. , Dragovic,B., Fraser,K., Hand,S.,Harris,T., Ho, A., Neugebauer,R., Pratt,I., and Warfield,A., “Xen and the art of virtualization,” in Proc. of the ACM Symposium on Operating Systems Principles (SOSP’03), Oct. 2003
- “Amazon elastic compute cloud (Amazon EC2), http://aws.amazon.com/ec2/.”
- Dixit,R., Buyan,P.,Dubey,V., “Priority Based Dynamic Resource Allocation for Green Cloud Environment: A Survey” International Journal of Engineering and Management Research (IJEMR) – volume 4 Issue 4, August- 2014.
- Clark,C., Fraser,K., Hand, S., Hansen, J.,G., Jul, E., Limpach,C.,Pratt, I.and Warfield, A.“Live migration of virtual machines,” in Proc.of the Symposium on Networked Systems Design and Implementation(NSDI’05), May 2005.
- Milojicic,D., Douglis,F., Paindaveine,Y., Wheeler,R. and Zhou,S. Process migration. ACM Computing Surveys, 32(3):241-299, 2000.
- Nelson.M.,Lim,B.,H. and Hutchins,G. “Fast transparent migration for virtual machines,” in Proc. of the USENIX Annual Technical Conference,2005.
- Waldspurger,C.A. “Memory resource management in VMware ESXserver,” in Proc. of the symposium on Operating systems design and implementation (OSDI’02), Aug. 2002
- Bobroff,N., Kochut,A., and Beaty, K.“Dynamic placement of virtual machines for managing sla violations,” in Proc. of the IFIP/IEEEInternational Symposium on Integrated Network Management (IM’07), 2007.
- Chase,J.S., Anderson, D.C.,Thakar, P.N., Vahdat,A.M. and Doyle, R.P. “Managing energy and server resources in hosting centers,” in Proc. Of the ACM Symposium on Operating System Principles (SOSP’01), Oct.2001.
- Das,T., Padala,P., Padmanabhan,V.N.,Ramjee,R. and Shin,K.G. “Litegreen: saving energy in networked desktops using virtualization,”in Proc. of the USENIX Annual Technical Conference, 2010.
- Agarwal,Y., Savage, S.andGupta,R. “Sleepserver: a software-only approach for reducing the energy consumption of pcs within enterprise environments,” in Proc. of the USENIX Annual Technical Conference,2010.
- Bila,N., Lara, E.D., Joshi,K., Lagar-Cavilla, H.A., Hiltunen, M. and Satyanarayanan,M. “Jettison: Efficient idle desktop consolidation with partial vm migration,” in Proc. of the ACM European conference on Computer systems (EuroSys’12), 2012.
- Xiao, Z., Song,W. and Chen,Q. "Dynamic Resource Allocation using Virtual Machines for Cloud Computing Environment", IEEE TRANSACTION S ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 24, 2013.
|