Keywords
|
| Measurement, Ranking, Relationship, Generalized flow |
INTRODUCTION
|
| Wikipedia is habitually a better option for a user to achieve knowledge of a single object than typical search engines. A user also might long to discover a relationship among two objects. |
| A relationship is an association between two or more people that may range in duration from brief to enduring. Word Association is a common word game involving an exchange of words that are associated together. This association may be based on regular business interactions, or some other type of social commitment. Interpersonal relationships are formed in the context of social. Interpersonal relationships are dynamic systems that change continuously during their existence. |
| A innovative method for measuring a relationship on Wikipedia by reflecting all the three concepts: distance, connectivity, and co citation. Here relationships are measured rather than the similarities. Assignment of the gain to each edge is important for measuring a relationship using a generalized maximum flow. It is established through experiments that the gain function is adequate to measure relationships appropriately. The strength of the relationship between a source object and each of its destinations objects, and rank the destination objects by the strength. The connection and production of other words in response to a given word is done spontaneously as a game, creative technique, or in a psychiatric evaluation. |
| The link analysis is a data-analysis technique used to evaluate relationships (connections) between nodes. Relationships may be identified among various types of nodes. Data gathering and processing requires access to data and has several inherent issues, including information overload and data errors. Once data is collected, it must be transformed into a format that can be effectively used by both human and computer analysers. The user can recognize an explicit relationship between two objects easily by reading the pages for the two objects in Wikipedia. By contrast, it is tricky for the user to determine an implicit relationship and elucidatory objects without investigating a number of pages and links. So, it is an appealing problem to measure and explain the strength of an implicit relationship between two objects in Wikipedia. |
| A Wikipedia is a type of content management system, it differs from a blog or most other such systems in that the content is created without any defined owner or leader, and Wikipedia have little implicit structure, allowing structure to emerge according to the needs of the users. The encyclopaedia project Wikipedia is the most famous wiki on the public web, but there are many sites running many different kinds of wiki software. Wiki promotes meaningful topic associations between different pages by making page link creation almost intuitively easy and showing whether an intended target page exists or not. Wiki is not a carefully crafted site for casual visitors. Instead, it seeks to involve the visitor in an ongoing process of creation and collaboration that constantly changes the Web site landscape. |
| The nature of mining processes creates a potential negative impact on the environment both during the mining operations and for years after the mine is closed. This impact has led to most of the world's nations adopting regulations to moderate the negative effects of mining operations. Safety has long been a concern as well, and modern practices have improved safety in mines significantly. The data mining task is the automatic or semi-automatic analysis of large quantities of data to extract previously unknown interesting patterns such as groups of data records (cluster analysis), unusual records (anomaly detection) and dependencies (association rule mining). This usually involves using database techniques such as spatial indices. These patterns can then be seen as a kind of summary of the input data, and may be used in further analysis or, for example, in machine learning and predictive analytics. For example, the data mining step might identify multiple groups in the data, which can then be used to obtain more accurate prediction results by a decision support system. Neither the data collection, data preparation, nor the result interpretation and reporting are part of the data mining step, but do belong to the overall knowledge discovery process as additional steps. |
| Data mining uses information from past data to analyse the outcome of a particular problem or situation that may arise. Data mining works to analyse data stored in data warehouses that are used to store that data that is being analysed. That particular data may come from all parts of business, from the production to the management. Managers also use data mining to decide upon marketing strategies for their product. They can use data to compare and contrast among competitors. Data mining interprets its data into real time analysis that can be used to increase sales, promote new product, or delete product that is not value-added to the company. |
| Text analysis involves information retrieval, lexical analysis to study word frequency distributions, pattern recognition, tagging/annotation, information extraction, data mining techniques including link and association analysis, visualization, and predictive analytics. The overarching goal is, essentially, to turn text into data for analysis, via application of natural language processing (NLP) and analytical methods. A typical application is to scan a set of documents written in a natural language and either model the document set for predictive classification purposes or populate a database or search index with the information extracted. |
| In Wikipedia, the knowledge of an object is gathered in a single page updated constantly by a number of volunteers. Wikipedia also covers objects in a number of categories, such as people, science, geography, politic, and history. Therefore, searching Wikipedia is usually a better choice for a user to obtain knowledge of a single object than typical search engines. A user also might desire to discover a relationship between two objects. Classic keyword search engines can neither measure nor explain the strength of a relationship. The main issue for measuring relationships arises from the fact that two kinds of relationships exist:“explicit relationships” and “implicit relationships.” |
| This paper proceeds as follows. Section II describes the related work and the global operation of system. The different leveraged metrics and components of the system are presented in Section III. Section IV presents components. Section V explains the conclusion and future works. |
RELATED WORK
|
| To rank the relationships between two objects in Wikipedia, measure the strength of the link among two pages that constitute the relationship. Existing system measures the relationship based on distance, connectivity and co citation. |
Dataset
|
| Dataset in Wikipedia includes objects that have relationships between each other. The existing method implies how to measure the strength of relationships among pages. |
Loading a dataset
|
| A data set is a collection of data, it lists values for each of the variables, such as height and weight of an object. The query used to generate a particular data set from the selected connection or flat file profile. Multiple data set definitions can be created for the same profile in order to generate different data set instances. To improve classification accuracy, insignificant parameters and patient data could be deleted from the data set. |
| The schema of a Data Set can be defined programmatically, created by the Fill or Fill Schema methods of a Data Adapter, or loaded from an XML document. To load Data Set schema information from an XML document, use either the Read Xml Schema or the Infer Xml Schema method of the Data Set can be used. |
| Read Xml Schema allows one to load or infer Data Set schema information from the document containing XML Schema definition language (XSD) schema, or an XML document with inline XML Schema. Infer Xml Schema allows to infer the schema from the XML document while ignoring certain XML namespaces that is specified. |
Data Preprocessing
|
| Data pre-processing is an important step in the data mining process. Data-gathering methods are often loosely controlled, resulting in out-of-range values. Analyzing data that has not been carefully screened for such problems can produce misleading results. Thus, the representation and quality of data is first and foremost before running an analysis. |
| If there is much irrelevant and redundant information present or noisy and unreliable data, then knowledge discovery during the training phase is more difficult. Data preparation and filtering steps can take considerable amount of processing time. Data pre-processing includes cleaning, normalization, transformation, feature extraction and selection, etc. |
| The product of data pre-processing is the final training set. The lacking of attribute values, lacking certain attributes of interest, or containing only aggregate data, reduce the volume but producing the same or similar analytical results. |
Generalized Maximum Flow-based Method
|
| The generalized maximum flow problem is identical to the classical maximum flow problem except that every edge e has a gain γ(e)>0; the value of a flow sent along edge e is multiplied by γ(e)>0. Let f(e)≥ 0 be the flow f on edge e, and μ(e) ≥ 0 be the capacity of edge e. The capacity constraint f(e)≤ μ(e) must hold for every edge e. The goal of the problem is to send a flow emanating from the source vertex s into the destination vertex t to the greatest extent possible, subject to the capacity constraints. Let generalized network G=(V,E,s,t μ, γ) be information network (V.E) with the source s?V , the destination t?V , the capacity μ, and the gain γ. Fig. 4 depicts an example of a generalized maximum flow on a generalized network. |
| Here proposing a new method for measuring the strength of a relationship using the generalized maximum flow. The value of flow f is defined as the total amount of f arriving at destination t. To measure the strength of a relationship from object s to object t, the value of a generalized maximum flow emanating from s as the source into t as the destination is used; a larger value signifies a stronger relationship. The vertices in the paths composing the generalized maximum flow as the objects constituting the relationship are regarded. |
Distance
|
| In the methods based on distance, a shorter path represents a stronger relationship. For this method, γ(e)<1 for every edge e; then a flow considerably decreases along a long path. A short path usually contributes to the generalized maximum flow by a greater amount than a long path does. Therefore, a shorter path means a stronger relationship in the method. |
Connectivity
|
| In methods based on connectivity, a strong relationship is represented by many vertex disjoint paths from the source to the destination. The number of vertex disjoint paths can be computed by solving a classical maximum flow problem. The generalized maximum flow problem is a natural extension of the classical maximum flow problem. Therefore, it also can be used to estimate the connectivity. |
Co citation
|
| A flow emanates from the source into the destination, and therefore the flow seldom uses an edge whose direction is opposite that from the source to the destination. On the other hand, Use of both directions is required to estimate the co citation of two objects. Consider the relationship between two objects s and t in the network presented in Fig. 5a. Object u is co cited by s and t. |
| This co-citation is represented by two edges (s,u) and (t,u). However, unable to send a flow from s to t along the two edges, unless reverse the direction of the edge (t,u) to (u.t). Therefore, construct a doubled network by adding to every original edge in G a reversed edge whose direction is opposite to the original one. For example, Fig. 5b depicts the doubled network for the network presented in Fig. 5a. |
METHODS TO MEASURE THE RELATIONSHIP
|
Gain Function
|
| In order to determine the gain function, first consider what kinds of explicit relationships are important in constituting an implicit relationship. In a generalized max-flow problem, a path composed of edges with large gain scan contributes to the value of a flow. To realize such a gain assignment, construct groups of objects in Wikipedia. |
| Categories cannot be used as groups directly because the category structure of Wikipedia is too fractionalized. Mutation can result in several different types of change in sequences, Mutations in genes can either have no effect, alter the product of a gene, or prevent the gene from functioning properly or completely. |
Cycle-Free Effective Conductance (CFEC)
|
| The cycle-free escape probability from s to t is the probability that a random walk originating at s will reach t without visiting any node more than once. The transition from one state to another does not depend on the previous state. The transition could be to the same state also. In network, proximity is the infinite number of attempts that is made to reach from starting node to end node. |
| CFEC proximity allows to readily compute proximity graphs, which are small portions of the network that are aimed at capturing a related proximity value. It is extension of connection graph which is capable of presenting compact relationship between objects of a network. It can deduce relationship between more than two endpoints, the flexibility to handle edge direction, and the fact that they are obtained by solving an intuitively tunable optimization problem. |
RANKING
|
| A ranking is a relationship between a set of items such that, for any two items, the first is either 'ranked higher than', 'ranked lower than' or 'ranked equal to' the second. By reducing detailed measures to a sequence of ordinal numbers, rankings make it possible to evaluate complex information according to certain criteria. t is not always possible to assign rankings uniquely. A common shorthand way to distinguish these ranking strategies is by the ranking numbers. |
| In competition ranking, items that compare equal receive the same ranking number, and then a gap is left in the ranking numbers. The number of ranking numbers that are left out in this gap is one less than the number of items that compared equal. The assignment of distinct ordinal numbers to items that compare equal can be done at random, or arbitrarily, but it is generally preferable to use a system that is arbitrary but consistent, as this gives stable results if the ranking is done multiple times. Query-independent methods attempt to measure the estimated importance of a page, independent of any consideration of how well it matches the specific query. |
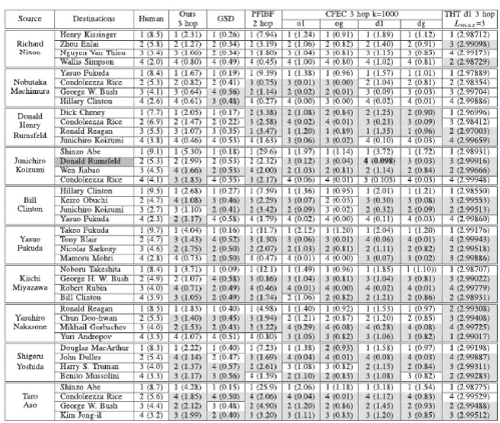 |
| In above example, for the source and the destination objects, select famous person known by the participants creating the rankings by their subjects. First select 10 famous Japanese and American politicians as source objects from Japanese Wikipedia, in order to enables the participants to investigate relationships among the persons on Wikipedia and create appropriate rankings. As the destination objects for each source, select four famous persons related to the source. Here only four destinations for each source is selected, because preliminarily observed that participants sometimes wavered in their judgments for five or more destinations. For each of the 40 obtained pairs of a source and a destination, the strength of the relationship from the source to the destination using this method is computed. |
CONCLUSION AND FUTURE WORKS
|
| Thus this method can measure the strength of a relationship between two objects on Wikipedia and rank them. Furthermore, this method does not underestimate objects having high degrees. This paper plans to form a relation tree, a directed tree with a unique node corresponding to the most recent common ancestor of all the entities at the leaves of the tree. |
| |
Figures at a glance
|
 |
 |
 |
| Figure 1 |
Figure 4 |
Figure 5 |
|
| |
References
|
- Y. Koren, S.C. North, and C. Volinsky, “Measuring and Extracting Proximity in Networks,” Proc. 12th ACM SIGKDD Int’l Conf.Knowledge Discovery and Data Mining, pp. 245-255, 2006.
- M. Ito, K. Nakayama, T. Hara, and S. Nishio, “Association Thesaurus Construction Methods Based on Link Co-OccurrenceAnalysis for Wikipedia,” Proc. 17th ACM Conf. Information and Knowledge Management (CIKM), pp. 817-826, 2008.
- K. Nakayama, T. Hara, and S. Nishio, “Wikipedia Mining for an Association Web Thesaurus Construction,” Proc. Eighth Int’l Conf. Web Information Systems Eng. (WISE), pp. 322-334, 2007.
- J. Gracia and E. Mena, “Web-Based Measure of Semantic Relatedness,” Proc. Ninth Int’l Conf. Web Information Systems Eng. (WISE), pp. 136-150, 2008.
- R.K. Ahuja, T.L. Magnanti, and J.B. Orlin, Network Flows: Theory, Algorithms, and Applications. Prentice Hall, 1993.
- K.D. Wayne, “Generalized Maximum Flow Algorithm,” PhD dissertation, Cornell Univ., New York, Jan. 1999.
- R.L. Cilibrasi and P.M.B. Vita´nyi, “The Google Similarity Distance,” IEEE Trans. Knowledge and Data Eng., vol. 19, no. 3, pp. 370-383, Mar. 2007.
- G. Kasneci, F.M. Suchanek, G. Ifrim, M. Ramanath, and G. Weikum, “Naga: Searching and Ranking Knowledge,” Proc. IEEE 24th Int’l Conf. Data Eng. (ICDE), pp. 953-962, 2008.
- F.M. Suchanek, G. Kasneci, and G. Weikum, “Yago: A Core of Semantic Knowledge,” Proc. 16th Int’l Conf. World wide Web Conf. (WWW), pp. 697-706, 2007.
- “The Erdo¨ s Number Project,” http://www.oakland.edu/enp/,2012.
- L. Katz, “A New Status Index Derived from Sociometric Analysis,” Psychometrika, vol. 18, no. 1, pp. 39-43, 1953.
- S. Wasserman and K. Faust, Social Network Analysis: Methods and Application (Structural Analysis in the Social Sciences). Cambridge Univ. Press, 1994.
- C. Faloutsos, K.S. Mccurley, and A. Tomkins, “Fast Discovery of Connection Subgraphs,” Proc. 10th ACM SIGKDD Int’l Conf. Knowledge Discovery and Data Mining, pp. 118-127, 2004.
- P.G. Doyle and J.L. Snell, Random Walks and Electric Networks, vol. 22. Math. Assoc. Am., 1984.
- M. Nakatani, A. Jatowt, and K. Tanaka, “Easiest-First Search: Towards Comprehension-Based Web Search,” Proc. 18th ACM Conf Information and Knowledge Management (CIKM), pp. 2057- 2060, 2009.
- L. Finkelstein, E. Gabrilovich, Y. Matias, E. Rivlin, Z. Solan, G.Wolfman, and E. Ruppin, The WordSimilarity-353 Test Collection,2002.
- E. Agirre, E. Alfonseca, K. Hall, J. Kravalova, M. Pas¸ca, and A. Soroa, “A Study on Similarity and Relatedness Using Distributional and Wordnet-Based Approaches,” Proc. 10th Human Language Technologies: Ann. Conf. North Am. Chapter of the Assoc. Computational Linguistics (NAACL-HLT), pp. 19-27, 2009.
- W. Xi, E.A. Fox, W. Fan, B. Zhang, Z. Chen, J. Yan, and D. Zhuang, “Simfusion: Measuring Similarity Using Unified Relationship Matrix,” Proc. 28th Ann. Int’l ACM SIGIR Conf. Research and Development in Information Retrieval, pp. 130-137, 2005.
- [19] D. Fogaras and B. Ra´cz, “Practical Algorithms and Lower Bounds for Similarity Search in Massive Graphs,” IEEE Trans. Knowledge Data Eng., vol. 19, no. 5, pp. 585-598, May 2007.
- “Country Ranks 2009,” http://www.photius.com/rankings/index.html, 2012.
|