INTRODUCTION
|
| Even though there exists numerous algorithms that have been proposed tracking remains a challenging problem due to appearance change caused by pose, illumination, occlusion, and motion, among others. An effective appearance model is of prime importance for the success of a tracking algorithm that has been attracting much attention in recent years [1–10]. Tracking algorithms can be generally categorized as generative [1, 2, 6, 10, 9] and discriminative [3– 5, 7, 8] based on their appearance models. Generative tracking algorithms typically learn a model to represent the target object and then use it to search for the image region with minimal reconstruction error. Despite the improvement, the computational complexity of several trackers is rather high, thereby limiting its applications in real-time image feature space based on compressive sensing theories [12, 13]. It has been demonstrated that a small number of randomly generated linear measurements can preserve most of the salient information and scenarios. This has been further extended by using the orthogonal matching pursuit algorithm for solving the optimization problems efficiently in Li et al. [9]. Despite these advancements still there exist several practical issues. First, numerous training samples cropped from consecutive frames are required in order to learn an appearance model online. Since there are only a few samples at the outset, most tracking algorithms often assume that the target appearance does not change much during this period. However, if the appearance of the target changes significantly at the beginning, the drift problem is likely to occur. Second, when multiple samples are drawn at the current target location, it is likely to cause drift as the appearance model needs to adapt to these potentially misaligned examples [8]. Third, these generative algorithms do not use the background information which is likely to improve tracking stability and accuracy. |
| Discriminative algorithms pose the tracking problem as a binary classification task in order to find the decision boundary for separating the target object from the background. There are certain methods which are developed to separate background and target of an image using positive and negative samples, still there occur problems due to noise and misaligned samples which often leads to the tracking drift problem. Later in [7,8,11]ref. different approaches for reducing the drift problem were proposed .The major problem with online tracking can be understood from the following figure. |
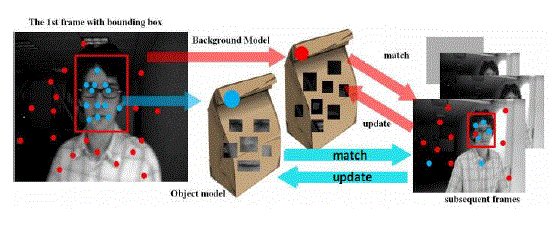 |
| In this paper, we propose an effective and efficient tracking algorithm with an appearance model based on features extracted in the compressed domain. The main components of our compressive tracking algorithm are shown below which generative as the object can be well represented is based on the features extracted in the compressive domain and also discriminative because we use these features to separate the target from the surrounding background via a naive Bayes classifier. In our appearance model, features are selected by an information-preserving and non-adaptive dimensionality reduction from the multi-scale space based on compressive sensing theories. |
| It has been demonstrated that a small number of randomly generated linear measurements can preserve most of the salient information and allow almost perfect reconstruction of the signal if the signal is compressible such as natural images or audio [12–14]. We use a very sparse measurement matrix that satisfies the restricted isometric property [15], thereby facilitating efficient projection from the image feature space to a low-dimensional compressed subspace. For tracking, the positive and negative samples are projected (i.e., compressed) with the same sparse measurement matrix and discriminated by a simple naive Bayes classifier learned online. The proposed compressive tracking algorithm runs at real-time and performs favorably against state-of-the-art trackers on challenging sequences in terms of efficiency, accuracy and robustness |
PROPOSED ALGORITHM
|
| In this section, we present our tracking algorithm in details. The tracking problem is formulated as a detection task and our algorithm is shown in Figure. We assume that the tracking window in the first frame has been determined. At each frame, we sample some positive samples near the current target location and negative samples far away from the object center to update the classifier. To predict the object location in the next frame, we draw some samples around the current target location and determine the one with the maximal classification score. |
Classifier Construction and Update :
|
| For each sample z ε Rm, its low-dimensional representation is v = (v1, . . . , vn)_ ∈ Rn with m _ n. We assume all elements in v are independently distributed and model them with a naive Bayes classifier [22], |
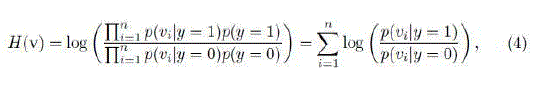 |
| where we assume uniform prior, p(y = 1) = p(y = 0), and y ∈ {0, 1} is a binary variable which represents the sample label. Diaconis and Freedman [23] showed that the random projections of high dimensional random vectors are almost always Gaussian. Thus, the conditional distributions p(vi|y = 1) and p(vi|y = 0) in the classifier H(v) are assumed to be Gaussian distributed with four parameters |
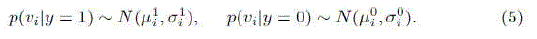 |
| The scalar parameters in (5) are incrementally updated |
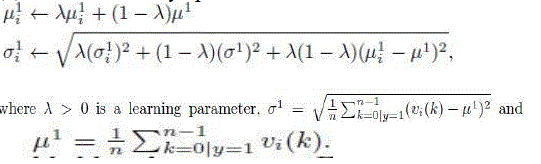 |
| The above equations can be easily derived by maximal likelihood estimation. |
| Figure 3 shows the probability distributions for three different features of the positive and negative samples cropped from a few frames of a sequence for clarity of presentation. It shows that a Gaussian distribution with online update using (6) is a good approximation of the features in the projected space. The main steps of our algorithm are summarized in algorithm 1. |
Algorithm for Tracking:
|
| Input: t-th video frame |
| • Sample a set of image patches, Dγ = {z|||l(z) − lt−1|| < γ} where lt−1 is the tracking location at the (t-1)-th frame, and extract the features with low dimensionality. |
| • Use classifier H in (4) to each feature vector v(z) and find the tracking location It with the maximal classifier response. |
| • Sample two sets of image patches Dα = {z|||l(z) − lt|| < α} and Dδ,β = {z|δ <||l(z) − lt|| < β} with α < δ < β. |
| • Extract the features with these two sets of samples and update the classifier parameters according to (6). |
| Output: Tracking location lt and classifier parameters |
DISCUSSION
|
| It is known that while making any advancement, simplicity is the prime characteristic and so is our algorithm. In this algorithm the proposed sparse measurement matrix R is independent of any training samples, thereby resulting in a very efficient method. In addition, our algorithm achieves robust performance as discussed below. |
Difference with Related Work:
|
| It should be noted that our algorithm is different from the other algorithms in aspects such as |
| • It requires only matrix multiplications while the rest requires tedious salvations to be done. |
| • Earlier there are algorithms which are generative models that encode an object sample by sparse representation of templates using _1-minimization, which results in cropping the training samples from the previous frames, storing and updating, but this is not required in our algorithm as we use a data-independent measurement matrix. |
| • Our algorithm extracts a linear combination of generalized Haar-like features but these trackers [10][9] use the holistic templates for sparse representation which are less robust. |
Robustness to Ambiguity in Detection
|
| Ambiguity is caused when the target moves fast or when its appearance changes too quickly to recognize. Multiple instance learning schemes have been introduced to alleviate the tracking ambiguity problem. Proposed algorithm is robust to the ambiguity problem. The most “correct” positive samples are similar in most frames. Whereas , the less “correct” positive samples are different as they involve some background information. Thus, the distributions for the features extracted from the most “correct” positive samples are more concentrated than those from the less “correct” positive samples which makes the features from the most “correct” positive samples much more stable than those from the less “correct” positive samples. In addition, our measurement matrix is data-independent and no noise is introduced by misaligned samples. |
Robustness to Occlusion
|
| Each feature in the proposed algorithm is spatially localized which is less sensitive to occlusion than holistic representations. Similar representations, have been shown to be more effective in handling occlusion. Moreover, features are randomly sampled at multiple scales by our algorithm in a way similar to [27, 8] which have demonstrated robust results for dealing with occlusion. |
| • The proposed algorithm is robust for conditions: |
| • Scale, Pose and Illumination Change |
| • Occlusion and Pose Variation |
| • Out of Plane Rotation and Abrupt Motion |
| • Background Clutters |
Implementation
|
| 1. Initially images(frames) are considered which are further divided into samples. These samples are further classified as target(fore ground) and back ground samples |
| 2. The multi scale filter bank splits or categorizes these samples into multiple components. These components are then represented in the form of a matrix. |
| 3. These matrices are then transformed as sparse measurement matrix which avoids or eliminates least significant information. |
| 4. These vectors are then inspected for positive probabilities using naïve bayes classifier. Using this method more positive probabilities are considered which helps in tracking desired object efficiently. |
CONCLUDING REMARKS
|
| In this paper, we proposed a simple yet robust tracking algorithm with an appearance model based on non-adaptive random projections that preserves the structure of original image space. A very sparse measurement matrix was adopted to efficiently compress features from the foreground targets and background ones. Our algorithm combines the merits of generative and discriminative appearance models to account for scene changes which enables this algorithm to perform well in terms of accuracy, robustness, and speed. |
| |
Figures at a glance
|
 |
 |
| Figure 1 |
Figure 2 |
|
| |
References
|
- Black, M., Jepson, A.: Eigentracking: Robust matching and tracking of articulated objects using a view-based representation. IJCV 38, 63–84 (1998)
- Jepson, A., Fleet, D., Maraghi, T.: Robust online appearance models for visual tracking. PAMI 25, 1296–1311 (2003)
- Avidan, S.: Support vector tracking. PAMI 26, 1064–1072 (2004)
- Collins, R., Liu, Y., Leordeanu, M.: Online selection of discriminative tracking features. PAMI 27, 1631–1643 (2005)
- Grabner, H., Grabner, M., Bischof, H.: Real-time tracking via online boosting. In: BMVC, pp. 47–56 (2006)
- Ross, D., Lim, J., Lin, R., Yang, M.-H.: Incremental learning for robust visual tracking. IJCV 77, 125–141 (2008)
- Grabner, H., Leistner, C., Bischof, H.: Semi-supervised On-Line Boosting for Ro-bust Tracking. In: Forsyth, D., Torr, P., Zisserman, A. (eds.) ECCV 2008, Part I. LNCS, vol. 5302, pp. 234–247. Springer, Heidelberg (2008)
- Babenko, B., Yang, M.-H., Belongie, S.: Robust object tracking with online multi-ple instance learning. PAMI 33, 1619–1632 (2011)
- Li, H., Shen, C., Shi, Q.: Real-time visual tracking using compressive sensing. In: CVPR, pp. 1305–1312 (2011)
- Mei, X., Ling, H.: Robust visual tracking and vehicle classification via sparse rep-resentation. PAMI 33, 2259–2272 (2011)
- Kalal, Z., Matas, J., Mikolajczyk, K.: P-n learning: bootstrapping binary classifier by structural constraints. In: CVPR, pp. 49–56 (2010)
- Donoho, D.: Compressed sensing. IEEE Trans. Inform. Theory 52, 1289–1306 (2006)
- Candes, E., Tao, T.: Near optimal signal recovery from random projections and universal encoding strategies. IEEE Trans. Inform. Theory 52, 5406–5425 (2006)
- Wright, J., Yang, A., Ganesh, A., Sastry, S., Ma, Y.: Robust face recognition via sparse representation. PAMI 31, 210–227 (2009)
- Candes, E., Tao, T.: Decoding by linear programing. IEEE Trans. Inform. The-ory 51, 4203–4215 (2005)
- Achlioptas, D.: Database-friendly random projections: Johnson-Lindenstrauss with binary coins. J. Comput. Syst. Sci 66, 671–687 (2003)
- Baraniuk, R., Davenport, M., DeVore, R., Wakin, M.: A simple proof of the re-stricted isometry property for random matrices. Constr. Approx 28, 253–263 (2008)
- Liu, L., Fieguth, P.: Texture classification from random features. PAMI 34, 574–586 (2012)
- Li, P., Hastie, T., Church, K.: Very sparse random projections. In: KDD, pp. 287–296 (2006)
- Viola, P., Jones, M.: Rapid object detection using a boosted cascade of simple features. In: CVPR, pp. 511–518 (2001)
- Li, S., Zhang, Z.: Floatboost learning and statistical face detection. PAMI 26, 1–12 (2004)
- Ng, A., Jordan, M.: On discriminative vs. generative classifier: a comparison of logistic regression and naive bayes. In: NIPS, pp. 841–848 (2002)
- Diaconis, P., Freedman, D.: Asymptotics of graphical projection pursuit. Ann. Stat. 12, 228–235 (1984)
- Raina, R., Battle, A., Lee, H., Packer, B., Ng, A.Y.: Self-taught learning: Transfer learning from unlabeled data. In: ICML (2007)
- Bingham, E., Mannila, H.: Random projection in dimensionality reduction:
- Ahonen, T., Hadid, A., Pietikainen, M.: Face description with local binary patterns: application to face recogntion. PAMI 28, 2037–2041 (2006)
- Leonardis, A., Bischof, H.: Robust recogtion using eigenimages. CVIU 78, 99–118 (2000)
- Kwon, J., Lee, K.: Visual tracking decomposition. In: CVPR, pp. 1269–1276 (2010)
- Santner, J., Leistner, C., Saffari, A., Pock, T., Bischof, H.: PROST Parallel Robust Online Simple Tracking. In: CVPR (2010)
- Adam, A., Rivlin, E., Shimshoni, I.: Robust fragements-based tracking using the integral histogram. In: CVPR, pp. 798–805 (2006)
- Hare, S.,Saffari, A., Torr, p.: Struck: structured output tracking with kernels. In: ICCV, pp. 263–270 (2011):
|