International Journal of Innovative Research in Computer and Communication Engineering
ISSN ONLINE(2320-9801) PRINT (2320-9798)
ISSN ONLINE(2320-9801) PRINT (2320-9798)
Vijayalakshmi A , Pethuru Raj
|
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Innovative Research in Computer and Communication Engineering
Extensive research on video based face recognition has been carried out by researchers in the recent years as security is a major concern in today’s world. Performing a comparison of face recognition with a still face and upon a video, video is given more importance as it can give more information to the user compared with still face image. Even though video can provide widespread information of a face, there still exist problems with respect to video like, occlusion and pose variation. From past several years there are extensive research going on in recognising faces from video, recognising partially occluded faces remains a challenging task. There has been lot of study going on in coming up with a better recognition rate with respect to occlusion. In this paper we propose a method to recognise face from video. Adaboost algorithm is used to detect faces from each frame and if there are occluded faces they are reconstructed using in painting and texture synthesis. On the pre-processed face image that is for all the faces that are stored in the dataset with occlusion. The features are extracted using Discrete Cosine Transform. Finally matching is done against the input face image. The algorithm is tested against You tube dataset and it is found that it gives better recognition rate compared to existing algorithms.
KEYWORDS |
| Face recognition from video, in painting, texture synthesis, Adaboost, Discrete cosine transform. |
I. INTRODUCTION |
| Face recognition is considered as one of the most important and reliable biometric system in today’s world as they don’t require user interaction with the system. Among the two different variations in face recognition namely still based and video based facerecognition, video based face recognition is gaining popularity at present. Video based face recognition is tending to carry more information about a face when compared with still based face recognition [1]. A face recognition system is formulated by the basic four modules [2] as shown in the given Figure 1.1. |
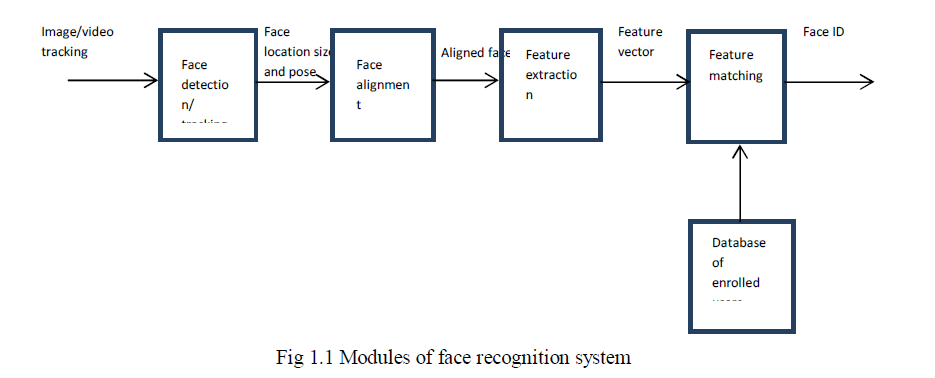 |
| The basic modules can be classified as detection, alignment, feature extraction and feature matching. Face detection is a method in which the face is detected from the background. One of the cues used in face detection is using skin colour. In video based face recognition this method has a great importance as the face has to be detected and the detected face has to be tracked using the face tracking component. Next is the component of normalizing the face geometrically and with respect to photometrical variations. Feature extraction is a component that provides effective information that is required to identify a person from the set of images. Face recognition is a procedure that depends on the process of extracting the features from the face image and matching it across the test images. |
| The major reason for considering face recognition as one of the best biometric is simply because; the interaction of the user with respect to the system can be completely ignored. Keeping the advantage of face recognition from a video, there exist major flaws with respect to video based face recognition like occlusion. Occlusion is a major concern in video based face recognition system as it is difficult to recognise faces which are partially occluded [3],as user does not interact with the system in the case of video based recognition, there are heavy chances of a face being susceptible to changes in expression, pose and occlusion. Studies made on these factors prove that an advance knowledge of occlusion on an image helps in an improved result of identifying the face [4]. In this paper[3]a study is made on holistic, component based and near holistic methods. They performed an experimental analysis in determining facial occlusion by detecting occluded area before performing recognition with respect to non-occluded areas of the face. The detection of face occlusion is carried out using Gabor wavelet, PCA and support vector machines. In this approach face is divided into components and Gabor wavelet features are extracted from the different components and the dimension is reduced which are fed to a SVM machine. The researchers claim that the result of this method is better compared to existing algorithms. |
II. LITERATURE SURVEY |
| ChangboHuet al. performed a work on recognising partially occluded faces from a video [5]. They used a method of recognising face from video based on face patches. Face patches are collected from different frames and these patches are stitched together to reconstruct a still face image. Sparse representation is used in recognising the reconstructed faces. The researchers claim that this approach reaches a high recognition rate on recognising face from video. |
| Rui Min et al. proposed a model in which partially occluded faces can be recognised at a better rate [3]. They carried out the research on specific occlusion materials like sunglasses and scarf. In this method, occlusion detection is carried out using Discrete Cosine Transform, PCA and SVM algorithms. The method identifies the occluded region and performs face recognition from non-occluded parts of the face. |
| Yousra Ben Jemaa and Sana Khanfir performed an experiment on face recognition using Discrete Cosine Transform and they concluded that Discrete Cosine Transform are proved to be better than geometric distances. Discrete Cosine Transform can represent images in various frequencies at different orientation [7]. |
III. PROPOSED METHOD |
| Detecting human faces from a frame of video can be performed using many cues. Skin tone is one of the cues that can detect a face from a video[2].In the proposed method, we use Adaboost algorithm to detect face from each frame. Skin texture from selective areas of the face and extract features for those selected areas. |
| PROPOSED ALGORITHM |
| Input: The face image to be recognized and the video in which to be recognized |
| Output: The Face Marked Frames in which the face is present. |
| 1. Face is detected from each frame using Adaboost algorithm. |
| 2. Once the face is detected from the video frames, occlusion is removed using in painting and texture synthesis. |
| 3. On the pre-processed face image skin texture is extracted using DCT. |
| 4. Matching is done against input face image DCT feature. |
| DISCRETE COSINE TRANSFORM FEATURE EXTRACTION |
| Discrete cosine transform is used as this method gives a robust and accurate data images. The sum of cosine functions of varied frequency is expressed as a set of data points in this method. This method is mainly used in images to reduce the dimension of the image. Upon application of this method on faces, energy is compacted in the upper left corner [5][6]. |
 |
| INPAINTING AND TEXTURE SYNTHESIS: |
| We are making use of in painting and texture synthesis for the occluded regions for an effective reconstruction of the face. Texture synthesis is obtained by performing the projection for several offset and averaging the result. Texture in painting is performed on the occluded region of the face. Performing in painting and texture synthesis on occluded region helps in reconstructing the face. The reconstructed face image can be used in extracting Discrete Cosine Transform and then matching across the test image. |
IV. EXPERIMENTAL RESULT |
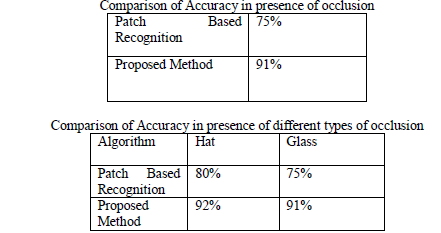
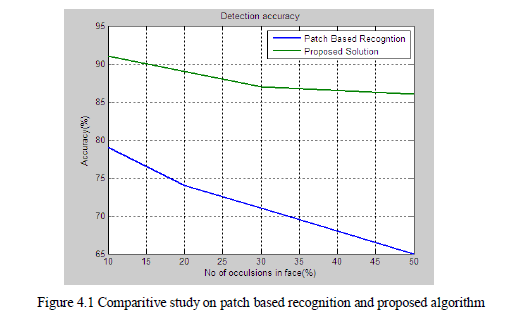
| The algorithm identifies a face from the video sequence. Upon the identified face, predicted face combination are created and stored in the dataset. This procedure of storing the predicted face reduces the time in matching the faces that is captured from the video. The features are extracted from the predicted faces that are stored in the dataset by using Discrete Cosine Transform. These features are matched against the content of the dataset which gives the accuracy rate at which matching is done. It is found that when You Tube dataset is used in identifying faces, the accuracy rate of recognising faces is comparatively high with respect to patch based method. Figure 4.1 shows the comparative study on the accuracy at which faces are recognised when compared with an existing algorithm. |
 |
 |
V. CONCLUSION |
| We proposed a method to recognise faces from video that are partially occluded. As the first stage of the algorithm, Adaboost method is used in detecting the faces. Upon detection of face, a dataset is created with various type of occluded faces. To these occluded faces in painting is done to reconstruct the occluded region. Upon dataset being created, the features from the faces are extracted using Discrete Cosine Transform.Finally the result of this method shows that our algorithm provides with a better recognition rate for partially occluded faces. The major disadvantage of video based face recognition is with partial occlusion, pose variation and illumination. Our further study is on better recognition rate of a face in a video with variant pose effects. |
References |
|