Research & Reviews: Journal of Engineering and Technology
ISSN: 2319-9873
ISSN: 2319-9873
1Assistant professor, Department of ECE, MITS, Chittor, Andhra Pradesh, India
2Professor and Head of ECE Department, JNTU College of Engineering, Pulivendula, Andhra Pradesh, India
Received date: 07/10/2015; Accepted date: 16/11/2015; Published date: 27/11/2015
Visit for more related articles at Research & Reviews: Journal of Engineering and Technology
At present there is an increased interest in Therapeutic image processing in most fields of engineering. Imaging modality provides detailed information about anatomy. It is also helpful in the finding of the disease and its progressive treatment. The Prime signs of Diabetic Retinopathy (DR) are Exudates which leads to severe vision loss in chronic condition. Exudates are the remnant of exuded blood and protein based particles from the damaged blood vessels of retina. Laser healing requires accurate location of exudates for faithful removal through Laser burns. Segmentation of fundoscope image will help the ophthalmologist in diagnosis, classification and to determine the severity. Multiple methods are designed and developed for Medical Image segmentation based on thresholding, Region Growing, Markov Random Model, Clustering, Deformable Model, Classifier, Neural Networks, Expectation Maximization and Support vector machines etc. Out of these the fuzzy clustering methods are less complex and are robust in operation. This paper aims in performance evaluation of Fuzzy C means clustering (FCM) algorithm, Kernel induced FCM (KFCM) and Spatial FCM (SFCM) algorithms are done.
Fuzzy C means Clustering (FCM), Kernel based Fuzzy C Means (KFCM), Spatial Fuzzy C means (SFCM), Image segmentation, Diabetic Retinopathy.
Diabetes is a chronic condition which requires lifelong therapeutic care and edification of self-management by the patient to put off initial complications and to lessen the threat of continuing problems. Beyond glycemic control, its care is quite complex as it poses the root cause of many issues.
Diabetes is classified into 4 medical classes:
Type 1 diabetes (outcome of islet cell damage of pancreas, results in absolute insulin deficiency) Type 2
diabetes (results in lack of insulin secretion) Other explicit causes includes hereditary issues in – functioning of organic cells , hereditary causes in action of insulin, issues with exocrine pancreas (like cystic fibrosis), and chemical actions during treatment of certain complications like AIDS or after organ replacement
Gestational diabetes mellitus (GDM) (found in pregnant women)
The patients with diabetes will have common symptoms like increased urination (polyuria), thirst (polydipsia), hunger (polyphagia) and weight loss. Vision blurriness, peripheral neuropathy, repeated vaginal infections, and tiredness are analyzed in clinical diagnosis.
Out of the above classification DR is more prevalent in type 2 diabetes. DR is a results mainly due vascular changes in the retina. Exudates are one of the primary sign of Diabetic Retinopathy [1]. Retina is a light sensitive muscular layer which is nourished by a network of blood vessels. Any vascular change results in difficulties of light perception. Depending upon these vascular changes in the eye fundus, DR is classified into non proliferative and proliferative. Proliferative refers to uncertainty of neovascularization (abnormal blood vessel growth) in the retina. DR with no neovascularization is called non proliferative diabetic retinopathy (NPDR). As the pathos progresses into proliferative diabetic retinopathy (PDR) [Presence of neovascularization] serious visual consequences are resulted. The vascular changes include weak and fragile blood vessels that exude blood, and protein particles into the eye fundus [Exudates]. Before they actually break they got swollen and ballooned out. These are called micro-aneurysms. In time these micro-aneurysms burst and leads to accumulation of Exudates. Also the blood vessels may block making the retina cells suffer from nourishment. Hence new blood vessels are stimulated which are abnormal, weak, transparent and probably ruptured. This makes situation chronic. It would be useful to have an automated method of detecting exudates in digital retinal images produced from DR screening programs [2]. Early detection and diagnosis of DR help the patient in preventing severe vision loss. Retinal images obtained by the fundus camera are used to diagnose DR. Automated methods of DR screening help to save time, cost and vision of patients, compared to the manual methods of diagnosis [3,4].
Image segmentation is defined as a method of sub dividing an image into group of peels that have homogeneous characteristics with respect to various principles. These are area oriented instead of pixel oriented. Segmentation splits an image into meaningful connected regions. These methods are classified into two: (i) Local segmentation, and (ii) global segmentation.
Local segmentation deals with segmenting sub images which are small windows on a whole image. The number of pixels available to local segmentation is much lower than global segmentation. Local segmentation must be frugal in its demands for pixel data. Global segmentation is concerned with segmenting a whole image. Global segmentation deals mostly with segments consisting of a relatively large number of pixels. This makes estimated parameter values for global segments more robust. Image segmentation can be approached from three different philosophical perspectives. They are (i) region approach, (ii) boundary approach, and (iii) edge approach.
Clustering method tries to attain the common features/characteristics of the pixels in different data sets and organizes the patterns into separate groups based on specific similarities. In the clustering technique, an attempt is made to extract a feature vector from local areas in the image. A standard procedure for clustering is to assign each pixel to the class of nearest cluster mean [5]. Most clustering algorithms do not depend on expectations common to traditional numerical methods, such as the basic statistical distribution of data, and therefore they are useful in situations where little prior knowledge exists. The strength of clustering procedures expose the principal structures in data can be made use in wide-ranging applications, including image processing, pattern recognition, classification, identification and modeling.
Clustering methods can be classified into two - Hierarchical and Partitional clustering. Hierarchical clustering methods make use of proximity matrix to determine the resemblance of data points needed to be grouped. They produce cluster trees which signifies the nested set of patterns and likeness levels at which grouping varies. In these methods the resulting clusters are always created as the inner nodes of the tree, while the root node is kept reserved for the whole dataset and leaf nodes are for individual data samples. The clustering procedures vary with respect to the rules by which two small clusters are fused or a large cluster is fragmented. The two key types of procedures used in the hierarchical clustering framework are agglomerative and divisive. Partition based clustering uses an iterative optimization procedure that aims at minimizing an objective function, which measures the goodness of clustering. Partition based clustering are composed of two learning steps— the partitioning of each pattern to its closest cluster and the computation of the cluster centroids [5]. A common characteristic of the partition based clustering is that the clustering process starts with an initial assumption of known number of clusters. The clustering centroids are typically calculated based on the optimality condition i.e., minimization of objective function. Partitioning procedures are characterized into Partitioning relocation methods and density based partitioning. Partitional clustering methods e.g., K-means clustering and fuzzy clustering are more advantageous than hierarchical clustering methods, where a portion of the data points optimizes some criterion functions.
In this paper a comparative analysis is done on three fuzzy based clustering methods. These includes Fuzzy C Means clustering (FCM) proposed by Dunn [6], and Kernel induced FCM proposed by Zhang [7,8] and Spatial FCM proposed by Keh-Shih Chaung [9].
Clustering methods are classified as crisp (hard) and fuzzy. In Crisp clustering data is fragmented mutually exclusive subgroups. Whereas Fuzzy methods gives significance on the uncertainty of data points as they poses variable amount of belongingness to multiple clusters concurrently. This belongingness is termed as membership degree whose value varies between 0 and 1. In many applications, fuzzy clustering is more natural and quite beneficiary than crisp methods. Even the data elements on the corners are not forced to merge in any one of the classes, but rather assigned with membership values prior to clustering.
The discrete nature of the hard partitioning also causes difficulties with algorithms based on analytic functionals, since these functionals are not differentiable [5].
Joe Dunn [6] reported FCM method in 1974 and improved by Bezdek [7] in 1981. FCM aims at Minimizing the Objective Function JFCM defined as
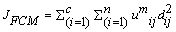 (1)
(1)
Where uij is the Membership function which represents the degree of belongingness of a pixel to a particular Cluster or Region. And dij is the Euclidean distance metric.
Let X = (x1, x2, x3……xn) be the set of data points.
C = (c1, c2, c3…..cn) be the set of centers.
1. Receive the input image in the form of data matrix, X
2. Fix the cluster of clusters “C”
3. Calculate the Fuzzy membership by using
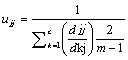 (2)
(2)
4. Compute the Fuzzy centers using
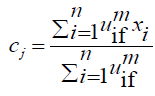 (3)
(3)
5. The iteration will stop when 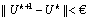 (4)
(4)
Based upon the distance metric between the data point and the cluster center the algorithm assigns membership to each data point. Membership value varies inversely with the distance value between them. Clearly, summation of membership of each data point should be equal to one. Cluster centers and Membership are updated according to the formula 2 and 3 after each iteration. The benefit of FCM is its converges speed but suffers with some limits like long computational time, sensitivity to the initial guess (speed, local minima), less immune to noise and one expects low (or even no) membership degree for outliers. For the detailed information of FCM refer [6,7].
This is an improved version of FCM in which the basic Euclidian metric in the FCM is modified by inducing a Gaussian kernel. This will improve the clustering efficiency and reduce the outliers’ problem present in FCM.
The objective function of KFCM is defined as
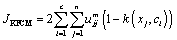 (5)
(5)
Let X=(x1, x2, x3---------- xn) be the set of data points.
C= (c1, c2, c3----------- c3) be the set of centers
(1) Receive the input image in the form of data matrix, X
(2) Fix the number of clusters “C”.
(3) Calculate the Fuzzy membership by using
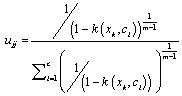 (6)
(6)
(4) Compute the Fuzzy centers using
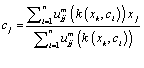 (7)
(7)
(5) The iteration will stop when 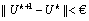 ( 8)
( 8)
A KFCM algorithm has better noise immunity and reduce outlier’s effect present in FCM but has limitations of computational complexity and less performance to large data sets. The detailed information of KFCM is provided in reference [8].
The earlier versions of Fuzzy clustering methods do not incorporate any spatial information. With the inclusion of spatial information i.e., information of the neighborhood pixels around the Exudates help in achieving optimum Segmentation results.
The objective function of the SFCM is defined as
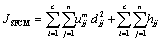 (9)
(9)
SFCM algorithm has two steps
1. The first step membership function calculation is done which is identical to standard FCM
2. In the second step, the mapping of pixel membership information to the spatial domain is done
A spatial function is computed from the second step.
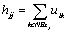 (10)
(10)
Where
NB(xj) is a square window centered on pixel xj.
A 3*3 square window was used throughout this method.
hij is the probability that pixel xj belongs to ith cluster.
The Membership function is updated as
 (11)
(11)
Thus the neighbor pixel characteristics are incorporated into the membership function as in equation [10]. The complete information of SFCM is providing in reference [9].
The following statistical measures are useful to compare image segmentation methods.
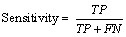 (12)
(12)
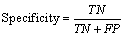 (13)
(13)
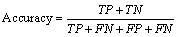 (14)
(14)
TP=Number of exudates pixels correctly detected
TN=Number of non-exudates pixels that are correctly detected as non-exudates
FP= Number of non-exudates pixels that are wrongly detected as exudates
FN=Number of exudates pixels that are not detected as exudates
Peak Signal-to-Noise Ratio [PSNR] is defined as the ratio between the maximum possible power of a signal (here the Image) and the power of corrupting noise that affects the fidelity of its representation. PSNR is usually expressed in terms of the logarithmic decibel scale and is given by
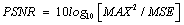 (15)
(15)
Where MAX is the maximum possible pixel value in an image and MSE is the Mean Square error between the input and processed images, given by the following equation
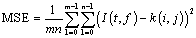 (16)
(16)
Where I(i,j) is the input image and K(i,j) is the processed image. m*n refers to size of the image.
The below Figures 1-4 shows Original Fundoscope images and the results of FCM, KFCM and SFCM methods. From these figures we can determine the segmentation and retinal exudates of FCM, KFCM and SFCM methods.

Figure 1: (a) Original image; (b)-FCM Segmentation results ; (c)-KFCM Segmentation results; (d)-SFCM Segmentation results.
The Table 1 shows the statistical analytical results of FCM, KFCM, SFCM.

Table 1: Performance-measures
From the above results it is quite evident that the results of SFCM are quite optimum compared to FCM and KFCM. The statistical results show that SFCM has highest Accuracy and PSNR compared to the other two clustering methods. Further the robustness of the SFCM towards noise can be improved with the implementation of edge preserving filtration at the front end to it. Even the convergence characteristics of these methods can be improved by weighted distance metric.