International Journal of Innovative Research in Computer and Communication Engineering
ISSN ONLINE(2320-9801) PRINT (2320-9798)
ISSN ONLINE(2320-9801) PRINT (2320-9798)
|
Visit for more related articles at International Journal of Innovative Research in Computer and Communication Engineering
In this paper, an imperceptible, fragile text watermarking algorithm has been proposed. The font color of each alphabet in the text document is varied in the greyscale in accordance with a sine function. The amplitude for the same is generated using a hash function. The authenticity of the received document can be verified by comparing the actual color values of the letters in the document with the expected values generated by the sine function. This scheme is highly sensitive to various malicious text related tampering attacks hence preserving the integrity of the document. Unlike earlier methods, the proposed algorithm provides tamper detection while maintaining watermark invisibility. The attack analysis illustrates that the scheme is efficient and secure.
Keywords |
| Greyscale; sine wave; text watermark; digital watermark; hash function; tamper detection |
INTRODUCTION |
| The increased role of internet and networking techniques in modern communication has raised concerns over the security of digital information. Greater access to mobile devices like flash drives, memory cards, iPods etc. has enabled large volumes of text material to be transferred over these channels, exposing them to plagiarism, copyright violation, redistribution and other forms of malicious attacks. While extensive work has been done in the fields of image, video and audio watermarking; the research in the field of text watermarking is rather limited. The growth of e-commerce, ebusiness and digital libraries has augmented the need for efficient text watermarking techniques. Over the years the methods of encryption, steganography and watermarking have been used to solve these problems. Recently digital watermarking has emerged as a more advantageous method. This method is preferable over its counterparts as it maintains the comprehensibility of the documents while ensuring their authenticity and integrity. The proposed algorithm is based on the variation of the colour values of the font which follows a sine function. A hash function is implemented on a paragraph of the text to generate amplitude values for the sine function. The algorithm is sensitive to any form of tampering attack. The paper is organised into 6 sections. Section II examines the previous related work done in the area of text watermarking. Section III describes the proposed algorithm. Section IV illustrates the implementation of the same. Section V describes the experimental results and Section VI lists the conclusions |
II. RELATED WORK |
| A digital watermark may be described as an identification code that is permanently embedded in the document. The invisible watermarks are more secure at preserving the authenticity of the document. In the past many techniques have been proposed. These include text watermarking using text images, synonym based, pre-supposition based, syntactic tree based, noun-verb based, word and sentence based, acronym based, typo error based methods etc. The text watermarking approaches are classified as follows. |
| A. Image Based Approach: |
| In image based approach towards text watermarking, the watermark is embedded in the text image. Brassil, et al. were the first to propose a few text watermarking methods utilizing text image [1]-[2]. Later, the performance of these methods were analysed by Maxemchuk, et al. [3]-[4]. Huang and Yan [5] proposed an algorithm based on an average inter-word distance in each line. Wiyada Yawai and Nualsawat Hiransakolwong showed how to use the intersection position of horizontal line, virtually run across text character skeleton line on a text image under the cross ratio applying, to be the marking point of zero watermarks [15]. |
| B. Syntactic Approach: |
| The constituents of a sentence such as nouns, verbs, prepositions etc. determine the syntactic structure of the sentence which depends on language and its conventions. Applying syntactic transformations on text structure to embed watermark has also been one of the approaches towards text watermarking in the past. Mikhail J. Atallah, et al. first proposed the natural language watermarking scheme by using syntactic structure of text [6]-[7]. Hassan et al. performed morpho-syntactic alterations to the text to watermark it [8]. |
| C. Semantic Approach: |
| Semantics of text like synonyms and antonyms are utilized to embed the watermark in text. Atallah et al. were the first to propose the semantic watermarking schemes in the year 2000[9]. Later, the synonym substitution method [10] was proposed. A noun-verb based technique for text watermarking was also proposed [11] which exploit nouns and verbs in a sentence parsed with a grammar parser using semantic networks. Later Mercan, et al. proposed an algorithm of the text watermarking by using typos, acronyms and abbreviation to embed the watermark [12]. Algorithms were developed to watermark the Text using the linguistic semantic phenomena of prepositions [13]. The algorithm based on Text Meaning Representation (TMR) strings has also been proposed [14]. |
| D. Zero-Watermarking approaches: |
| In zero watermarking approach, the host text document is not altered to embed the watermark; rather the characteristics of the text are utilized to generate a watermark. This watermark pattern is later matched using a pattern matching procedure with the pattern generated by tampered document to identify any tampering [16]. Jalil Z. et al. proposed a zero text watermarking algorithm based on occurrence frequency of non-vowel ASCII characters. The embedding algorithm makes use of frequency non-vowel ASCII characters and words to generate a specialized author key [17]. Zunera Jalil et al. developed an algorithm which utilizes a keyword from the text (selected based on author choice) to generate a watermark based on the length of preceding and next word length, to and from the keyword occurrences in text [19]. |
III. PROPOSED ALGORITHM |
| The aforementioned techniques have the drawback of attack specificity and often become unreliable when multiple attacks are performed. They also are not applicable to all types of text documents under random tampering attacks and are not specifically designed to solve tamper detection problem. The proposed algorithm aims to ensure authenticity and integrity over a wide variety of tamper attacks while also identification of location of tampering. |
| The algorithm uses variations in the font colour of the document. This watermarking technique exploits the fact that minor changes in colour are imperceptible to the human eye. The colour of every alphabet in the document varies sinusoidal within the greyscale. Xianmin Wei, earlier, proposed a sine wave based watermarking scheme which relied on word count, was limited to WORD documents only [18]. |
| In the proposed algorithm, the count of each alphabet present in the raw text determines the parameters of the color variations on the entire text. It is, therefore, independent of any format of the document i.e. doc, docx, pdf etc. because the algorithm runs on raw text. The same algorithm may easily be extended to other languages with only slight modifications involving the number of alphabets. The proposed technique of digital text watermarking can be adopted for IP protection of any text document |
| A. Watermark embedding process: |
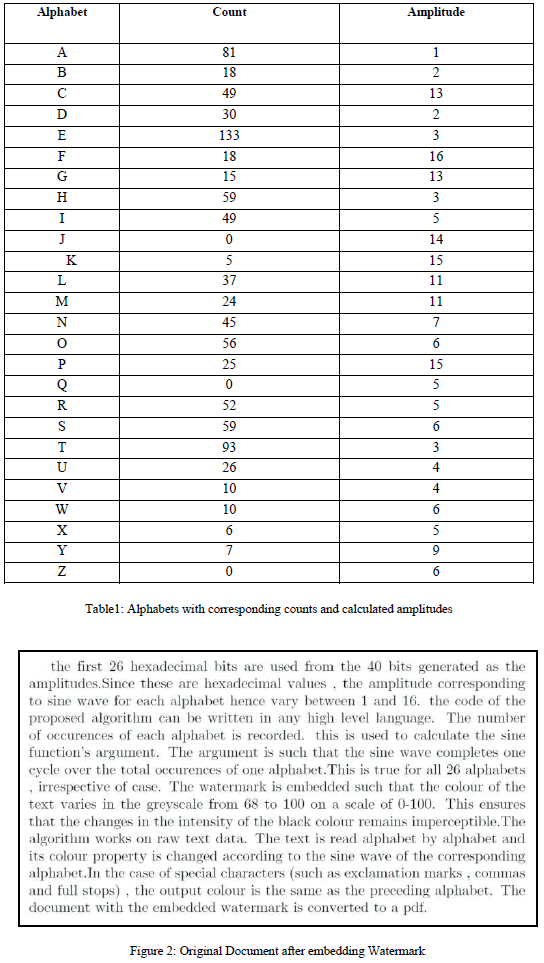
| The amplitudes of the sine waves are generated by applying the SHA-1 hash to any chosen paragraph of the document. This paragraph will be pre-decided between the sender and the receiver. The first 26 hexadecimal bits of the 40-bit hash so generated are used as amplitudes. The first 26 hexadecimal bits are used from the 40 bits generated as the amplitudes. Since these are hexadecimal values, the amplitude corresponding to sine wave for each alphabet hence vary between 1 and 16. The code of the proposed algorithm can be written in any high level language. The number of occurrences of each alphabet is recorded and this is used to calculate the sine function's argument. The argument is such that the sine wave completes one cycle over the total occurrences of one alphabet. This is true for all 26 alphabets, irrespective of case. The watermark is embedded such that the colour of the text varies in the greyscale from 85 to 100 on a scale of 0-100. This ensures that the changes in the intensity of the black colour remain imperceptible. The text is read alphabet by alphabet and its colour property is changed according to the sine wave of the corresponding alphabet. In the case of special characters (such as exclamation marks, commas and full stops), the output colour is the same as the preceding alphabet. The document with the embedded watermark is converted to a pdf. |
| B. Tamper Detection: |
| At the receiver end, the raw text is extracted from the received pdf document. The embedding algorithm is again run on the raw text to generate a new watermarked document. This generated document is compared against the received document. Any mismatch reported will indicate that the received document has been tampered with. The two documents can be compared by converting them to images and subtracting them using some software like MATLAB. If the document has not been tampered with, a resultant black image will be obtained |
IV. PROPOSED ALGORITHM |
 |
| 5. The subtracted image is given by Imsub= abs(Im1-Im2) and convert Imsub to greyscale format. 7. Plot the histogram. |
V. EXPERIMENTAL RESULTS |
| The following figures demonstrate the experimental observations. Figure 1 shows the raw text. The changes in the text document after embedding the algorithm are imperceptible, as seen in Figure 2. Figure 3 shows the tampered document. The subsequent images show the detection process. Figure 4 plots the histogram on comparing the untampered watermarked text obtained at the receiver’s end against the text obtained by running the algorithm again on it. Figure 5 illustrates the output on subtracting the images of the tampered watermarked text and the document obtained on running the algorithm again on the received tampered text. The histogram generated for Figure 5 is shown in Figure 6. It can be seen from these results that if the document has been tampered with, then a resultant black image with grey patches is observed on subtraction. Otherwise, the resultant image will be completely black. |
 |
| Figure 1:Original Raw Text |
| The raw text shown in Figure 1 when hashed with the SHA-1 algorithm (using a hash generator) generates the following 40-hexadecimal value: |
| “01c12fc24deaa65e4452335485854481603cd4bd” |
| The following table each alphabet along with its corresponding number of occurrences and the amplitudes calculated on the basis of the hash function. These values are then used as parameters {Nn and An} of the sine function to generate the instantaneous color value of the alphabets as explained in section IV. The total count and amplitudes for each alphabet are given in Table 1. |
 |
| Figure 3 shows the tampered document. The subsequent images show the detection process. |
 |
| Figure 3: Tampered Document after running the Extraction Algorithm |
| When the document is untampered, the received pdf and the pdf generated after extraction are identical. Hence on subtraction, the resultant image is completely black. This causes the histogram to be concentrated around 0 as shown in Figure 4. |
 |
| Figure 4: Histogram on comparing untampered watermarked document with the text obtained on running the algorithm again on it |
| Tampering of the document causes discrepancies in the parameters of the sine wave. Thus the resultant image has grey patches, shown in Figure 5. |
 |
| Figure 5: Subtraction of images of tampered text with that obtained in Figure 3 |
| On plotting the histogram of this subtracted image, it is observed that it is no longer concentrated along zero but rather distributed along the whole greyscale as in Figure 6 |
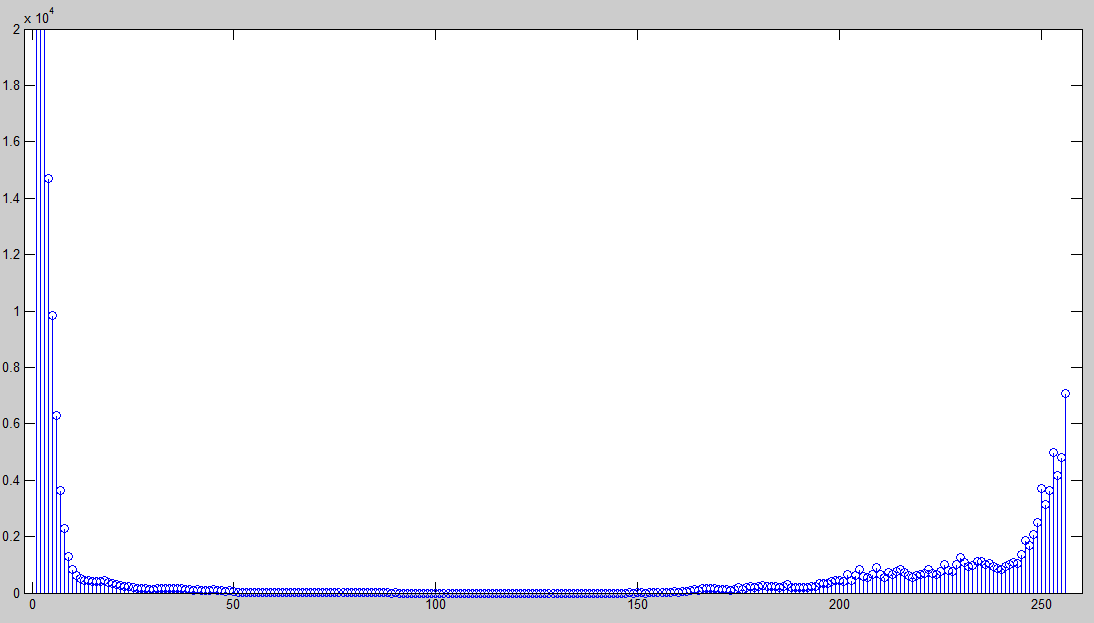 |
| Figure 6: Histogram of Figure 5 |
VI. CONCLUSION AND FUTURE WORK |
| The algorithm implemented here is a novel watermarking scheme that is imperceptible and preserves the authenticity and integrity of the document. Using alphabet count as a variation parameter allows for an unprecedented amount of sensitivity of even small changes which is the strength of the proposed technique. The earlier works on watermarking for text authentication are not reliable in the case of random tampering attacks, especially when the amount of tampering is low. The algorithm hence is versatile, highly imperceptible and fragile. Future works may include extending the algorithm to watermark coloured documents and to detect changes in formatting, like indentation, of the document. With small changes, the algorithm may also be extended to other languages too. |
References |
|