International Journal of Innovative Research in Computer and Communication Engineering
ISSN ONLINE(2320-9801) PRINT (2320-9798)
ISSN ONLINE(2320-9801) PRINT (2320-9798)
Ram Kiran Puttagunta1*, S Ravi Kishan2
|
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Innovative Research in Computer and Communication Engineering
With the advent of depth on the Internet, if you are looking for a vehicle or the like, such as real estate, a database of the Internet for the whole area, it was modified for the routine work I can be one of the problems in this context is to display results of a dilemma for the new user Dossier evaluation database query and previous techniques for solving this problem, using the frequencies for the profile of the end user. Through a number of techniques, the classification can be ended in a way that does not depend on the application and / or standard user string. Including this paper proposes a strategy for new complaints and charges lead to data sources from the internet for the dilemma of specific classification to the user. Most new rating models and existing for the new rankings are provided by you, to run victory against the dilemma of end user, the decision to support the idea of the similarity of the dilemma of the end user. This particular execution, you can buy rare configurable work load in terms of the number of this type of ranking function to frame the request for different users. For the equivalent row of inclination of the screen, the end user equivalent depends on the intuition of the specific result of the application of the equivalent model of a particular.
Keywords |
| Ranking, Web Database, Query and User Similarity |
INTRODUCTION |
| A variety of applications, for example, the advent of deep Web, has led to the proliferation of a number of databases on the Web for airline reservations, find a car, screening properties. Usually, these databases are obtained by blending the query criteria in the schema attribute. If the number of results returned is large, in order (s), further investigation is a more useful time to view the answer, you want to select. Currently, by displaying the sort query results by the value of a single attribute database on the Web, to simplify this task, for example, price, and mileage, however, Web most users, the obtained command using the values of multiple attributes will be close to its expected to prefer. Sort-based mechanism - current used in the web database does not work as rank. Making it possible to manually specify the weight of the extended attributes of some SQL, but this approach is cumbersome for most users Web. The automatic classification of the database search results , and has been studied in the context of relational databases , they , therefore , do not distinguish between users , many techniques for performing classification dependent request , all provides ranking of single query for specific users. |
| In contrast, techniques for building extensive user profiles as well as requiring users to order data tuples, proposed for user- dependent ranking, do not distinguish between queries and provide a single ranking order for any query given by the same user. Recommendation i.e., collaborative and content filtering as well as information retrieval systems use the notions of user- and object/item-similarity for recommending objects to users. Although our work is inspired by this idea, there are differences that prevent its direct applicability to database ranking. |
| The selection of the appropriate function based on the paper proposed a novel similarity-based ranking model. The assumption behind our approach to the results of a query, similar users display comparable ranking preferences, and user presentations on the results of the same questions, similar to the ranking of priorities. The similarity of the question and the user similarity: We break into the concept of similarity. As a result of the proposed measures and the question of the situation or the question-the former, the latter is a set of common questions among users is calculated by comparing the individual ranking functions are estimated using either though. Independently applied to each model, we also propose a unified model to identify an improvement in the ranking order. The importance of the attribute values are represented by the weights of the individual features and the value refers to the importance of the attribute weights: use our framework, the ranking function is a linear function of weight amounts. |
II. RELATED WORK |
| Ankur Gupta [1] With billions of web pages available on the web, a user query entered in a search engine may return thousands of web pages, and thus, it becomes extremely important to rank these results in such a manner that the most “relevant” or “authoritative” pages are displayed first. This task of prioritizing the results is performed by ranking algorithms, and various search engines employ different schemes for ranking the results. This is also dynamic field of research with different researchers proposing their algorithms corresponding to their interpretation of “relevance” or “authoritativeness” of a page to the user. |
| Author explains the need for ranking web pages and discusses various major ranking algorithms. Page rank is one of the major ranking algorithm developed by Google search engine. Page Rank (PR) visited the likelihood of side by such a user according to this model. PR is on the link structure of the web-based, i.e., the analyzes in the left and links from the pages in the web and gives ranks to them accordingly. The algorithm assumes that if a page has a link to another page then that it’s Page. Therefore, each in - link is to a page its meaning under this concept and is captured by the Page Rank algorithm.PR is a recursive algorithm in which the Page depends on the PR of the pages linked to. So is not only the number of in - links to a page effect, but also PR of the pages linked to. One side gives meaning to the pages that it points to the uniform distribution of its PR value among all out- links. The following is a simplified example the PR algorithm. |
| Hilltop [2] is also an approach to authoritative ranking of the similar to HITS, but popular queries not used topic Distillation. The aim of this algorithm is to identify documents, The "experts", similar to the hub pages in HITS, to which Query issue and they, as a means to guide the search results. Hill is a two-stage process in which The first step concerns the identification of experts on the part of query topic and the second stage uses these experts to calculate the ranking of landing pages. In response to a request, relevant experts selected pages on the query topic. in the next step authoritative sites are determined on the query topic selected by the out-links of the pages in the experts previous step. |
| Query Sensitive Page Ranking [3] it explains about the global importance and local importance scope for a web page. While ranking, it proposes a algorithm to the query combining both global as well as local importance of the web pages. The number of votes a page gets is a measure of its query sensitiveness. The final ranks to the pages are assigned as a combination of their query sensitiveness and global importance values like Page Rank |
| Aditya Telang, Sharma Chakravarthy [4] The emergence of the deep Web databases has a new connotation to the concept of ranking query results. Previous approaches for the ranking of the analysis frequencies of database values and query logs or the establishment of user profiles used. In contrast, an integrated approach, which was based on the idea of a similarity model for supporting user-and query-dependent ranking, is proposed recently [5]. An important part of this ranking framework is a labor of ranking functions; each function represents preferences of an individual user on the results of a particular query. At the time of answering a query for which no prior ranking function is present, the similarity model can provide only if a ranking function is for a good quality of the rankings for a very similar userquery pair in the workload. |
| The emergence of the deep Web [6] [7] has led to the proliferation of a large number of Web databases for a variety of applications (e.g., airline reservations, vehicle search, real estate scouting). Typically, these databases are searched by formulating queries on their schema attributes, and often, these queries yield too many results. Currently, Web databases assist users by displaying the query results in a sorted order on the values of a single attribute (e.g., Price, Mileage, etc.).The context of Google Base’s [8] Vehicle database that comprises of a table with attributes Make, Price, Color, and so on |
| Query similarity Model:This model is based on the hypothesis – “if an input query Qj is most similar to aquery Qy (in Ui’s workload), Ui would display similar ranking preferences over the results of both queries; thus, the ranking function (Fiy) derived for Qy can be used to rank Qj’s results”. The similarity between two queries (in this case Qj and Qy) is determined by comparing the attribute values in the query conditions. |
| User similarity Model: This model is based on the hypothesis – “if user Ui is similar to an existing user Ux, then, for the results of a given query (say Qj ), both users will show similar ranking preferences; therefore,Ux’s ranking function (Fxj ) can be used to rank Qj’s results for Ui as well”. This hypothesis is translated formal model that determines similarity between a pair of users based on the similarity of their individual ranking functions over different common queries in the workload. |
| Pramod Kumar Ghadei [9] Online Web database in response to a question, the answer is relative to a lot of responses to cope with the problem, this paper proposes a unique ranking of the results of this question. The user cares about each attribute and assigns it as a specific weight of the load on the database, we assume. Then, based on the relationship between different attribute values, the initial question of the degree of user satisfaction degree, the level of satisfaction in accordance with the ranking method to take all tuples response, development. Tuples, then for the same degree of compliance, each feature can be used for the partitioning of the tuples to the user, and the "importance" in accordance with the result is a null value. Finally, preliminary results of the experiment can be used to better serve customers in the web database can affect the ranking of the methods. |
| Immediately due to the rapid development of WWW, online business development and web over the changes. Web Database support is usually required for online business using the Internet has changed the way to display product information. Here is a web database interface refers to the online web database and is accessible by the user. Real-time applications, online query processing, web database models the user as he / she wants to know what to do, and certainly he / she is able to specify the questions of the consultation requirements are shown. Practically in real time, users, databases, and has enough knowledge about its structure, and their intentions are often vague question. In relation to such inquiries as they would like to see a more meaningful information. Therefore, the question submitted by the user to receive the results of the query should be soft obstacles. |
| Ranking user Query has been inspected in information retrieval for a long days. The probabilistic ranking model [10] and [11] and the statistical language model [12] have been successfully used for ranking functions. In addition and explore the combination of database and information retrieval techniques to rank tuples of text attributes. And a few keyword-query based on retrieval techniques for databases are suggested. Whereas, most of these techniques concentrates on text attributes so it is very difficult to apply these techniques to rank tuples with categorical and numerical attributes. |
| Also, various studies have been proposed to rank the results of a database query. [13] and [14], SQL query language specified by the user, according to the ranking function to specify the features that allow for the expansion of their choice. In [15] and [16], as the prices of the tuples in a relation to what it thinks are important, and that customers are looking for, extracted automatically by the help of analyzing workloads. [17] and [18], respectively, were in a quantitative and qualitative selection model. In the first, each tuple of a number of options to answer the question indirectly by using the functions associated with the specified rating. In the second, while the tuples of relations between the options using the steps specified. However, it should also be pointed. These mainly focus on the results of the ranking of the original question, and the more hard to rank up the results of a relative question. |
| Neelam Duhan [19] The World Wide Web is considered to be the most valuable space for Information Search and Knowledge Discovery. Retrieving the user questions, information from a search engine results and a collection of documents. In the web mining tools users of the documents are used to classify the cluster. Easy to navigate and find the desired search results information content. The most effective way to manage clustering and ranking documents, the name is a combination of clustering, can be applied to a group of documents and ranking .The sequence of pages within each cluster. Based on this approach in this paper a mechanism that is being proposed. It can be ordered in the form of groups in accordance with the results of the user’s question. Effective page ranking method has also been proposed according to the orders of both the relevance and the importance of the documents. This approach helps to limit the user’s top documents based up on his interest in the exploration of some of the special groups. |
| Most of the search engines are page ranking algorithms, by using their relevance in order of importance the documents can be the content score. Some search engines also apply to the Web mining Such as clustering, classification, association rule methods, the discovery and characterization of the filter, classify as well as group their search results. Many page ranking algorithms [20] have been proposed as successful, intelligent, Page Rank, High page rank, page content rank. Some of the algorithms based on their popularity Scores are linked to the structure of the documents, to look for some content user query in relation to the documents. And others use a combination of the two links they use, assign a rank, such as the content of the related document. |
| Page Rank Algorithm: Page Rank [21] was developed by Larry Page and Sergey Brin. Google uses this algorithm in order to the search results, such as important way to move up the documents in the search results and moving the less important pages down in the list. If they have some important incoming links to a page that tells the algorithm, then its outgoing links to other pages is important. Therefore, it is taking into account the ranking of the campaign by links. Some question at a given time are, Google to combine page rank score to obtain a text matching scores precompiled in response to each of the web page as a result of an overall ranking score question. |
| Weighted Page Rank Algorithm: Wenpu Xing and Ali Ghorbani [22] proposed an extension of weighted standard Page Rank Page Rank (WPR) that assumes the more popular web pages and more links to other pages that contain them, or through them. The values of the ranking algorithm are used to allocate the more important pages. Instead of value of the rank of a page in splitting it evenly between the outgoing of the linked pages, and get a value for each out link page. Each out link page gets a value proportional to its popularity or importance and this popularity is measured by its number of incoming and outgoing links. |
| Sruthi Ambati1, Raghava Rao [23] The Internet has paved the way for the emergence of the web database. Investigation of such database information is necessary to become a simple task. The results of such a question in the ranking still remain a problem to be addressed. User profiles, such as query logs, and database values to the ranks of the existing solutions to the user which are independent and query-independent fashion. The ranking cannot be effective. In this paper, an award query results to the ranking of the deep web is the process of ranking for the question and depends on the user. The results of the ranking is the question of the proposed ranking framework, it is based on two fundamental aspects. One is the question of similarity and the other is similarity of the user. To question the effective ranking of these comparisons of robbed Results, a sample application is built to test the ability of our model. Exposure of the empirical results of this approach can be used in real-world applications. |
| In this paper the ranking model is based on two notions such as user similarity and query similarity. User similarity indicates that different users can have same preferences. Query similarity indicates that different users can have same queries. In order to achieve this ranking of users and queries are to be maintained. We have developed a workload file that contains the user and query ranking functions. When new record is entered into web database, obviously that is given by a user. There might be many users who issued that query previously and there might be same queries issued earlier. The workload file is in tabular format and it gets updated with ranking functions as per the proposed algorithm as and when new queries are made. |
III. PROPOSED METHOD |
| In this paper a new ranking function, i.e. Kendall’s rank correlation coefficient is used for query based ranking. This ranking function produces accurate and efficient results compared to existing ranking functions. |
Methodology : |
| 1. Ranks are first assigned in an ascending order of magnitude to the scores of each variables (continuous or discontnuous) separately. |
| 2. The ranks (R1) of the variable with no tied score are arranged in an ascending order along a column. And each such R1 rank is paired in the adjoining column with the rank (R2) of the other variable in the same individual. |
| 3. If neither or each of the variables has tied scores the ranks of any of them are arranged as R1 ranks in the ordered manner pairing them with the ranks(R2) of the other variable in the respective individuals. |
| 4. Moving down word from the top of the column of the paired R2 ranks of the second variables, each R2 rank is used in turn as the pivotal rank for comparing with every successive subsequent rank following the pivotal rank. |
| 5. Each subsequent r2 rank is counted here as +1,0 or -1 according as it exceeds. Equals (tied with) or lower than the particular pivotal rank. |
| 6. Such counts of subsequent ranks are entered in a third column and totalled score as S ( Nc2). |
| 7. Here ranks are assigned to N individuals range from 1 to N. Kendalls rank correlation (ïÿýïÿý) i.e., tau is given by |
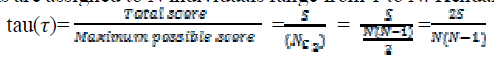 |
IV. SIMULATION RESULTS |
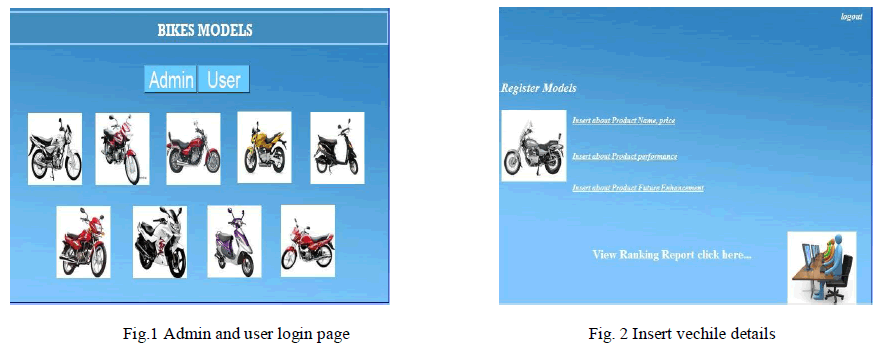
| The simulation results for the proposed method are shown in the following figures. The fig.1 shows the admin and the user login. In fig.1 the admin can login into his account. So when admin login into his account he can see the ranking details and all the other various bike details. When user login into the account he can see all the bike details and he can give feedback to that vehicle.Fig.2 shows the page when admin logins. In fig.2 the admin can insert vehicle details like product name, price, product performance and product future enhancement. Here the admin can also see the ranking report of the vehicles. Fig.5 shows the user similarity based results.Fig.5 gives results of all vehicles when user wishes to see all the other details of vehicles. |
 |
| In fig.3 the customer can search a vehicle of his choice by giving the product name product type and price. According to his query the results will be displayed.In fig.4 the user’s choice of results will be displayed. The results are based on his query details |
 |
| Fig.5 is displayed when user sees all the details of vehicles.Fig.6 shows where the admin logins. Here admin only can login where the admin can insert all the vehicle details. |
 |
| Fig.7 shows the ranking results of all the vehicles. Fig.7 is displayed to the admin.In fig.8 the customer gives feed back to the vehicle he searched. So that when admin logins he observes all the feedback given to the vehicles by the customer so basing on the feedback the ranking will be done for all the vehicles. |
 |
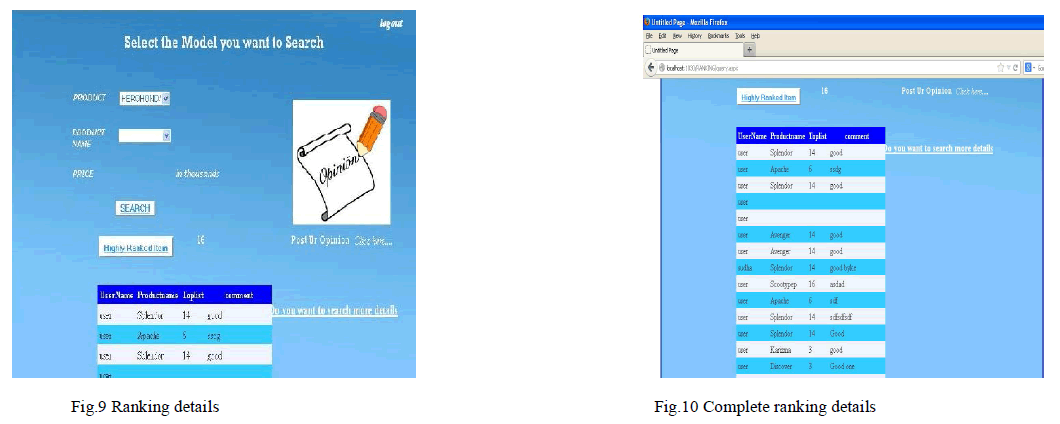
| Based on the feedback given by the customer the ranking of bike query system is obtained and it is displayed as shown in fig.9.The fig.10 shows the ranking of all the vehicles and it also displays the comments of the vehicle given by the user. It also shows the rank of each individual vehicle. So that the user can know the rank and comments of the vehicle given by other users. |
 |
V. CONCLUSION AND FUTURE WORK |
| This paper proposed a new ranking model for ranking query results of web databases. We used a web databases for experiments. They are vehicle database. The model is based on both user based similarity and query based similarity. We have also built a web based application that describes the efficiency of the proposed ranking model. A workload file is maintained that that continually stores updated ranking functions for both query based similarity and user based similarity. When a new query is made, this workload file is used for giving ranking to the query results. Developing a workload is challenging in the context of web databases. We have implemented an algorithm for computing user based and query based similarities and update workload constantly. The experimental results shows that our new ranking model works well and it can be used for real world web databases. |
References |
|