Nkemnole EB*, Adoghe VO
Department of Statistics, University Lagos, Lagos, Nigeria
Received: 02-Aug-2023, Manuscript No. JSMS-23-108914; Editor assigned: 04-Aug-2023, Pre QC No. JSMS-23-108914(PQ); Reviewed: 18-Aug-2023, QC No. JSMS-23-108914; Revised: 25-Aug-2023, Manuscript No. JSMS-23-108914 (R); Published: 01-Sep-2023, DOI: 10.4172/ RRJ Stats Math Sci. 9.3.002.
Citation: Nkemnole EB, et al. A Comparison Between Long Short-Term Memory and Hidden Markov Model to Predict Maize Production in Nigeria. RRJ Stats Math Sci.2023.9.002.
Copyright: © 2023 Nkemnole EB, et al. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Visit for more related articles at Research & Reviews: Journal of Statistics and Mathematical Sciences
Due to population increase and import constraints, maize, a key cereal crop in Africa, is experiencing a boom in demand. Given this, the study's focus is on determining how maize output in Nigeria interacts with various climatic factors, particularly rainfall and temperature. The Hidden Markov Model (HMM) and the Long Short-Term Memory neural network (LSTM) are compared in this context to assess their performance. A variety of performance indicators, such as correlation, Mean Absolute Percentage Error (MAPE), Standard Error of the Mean (SEM), and Mean Square Error (MSE), are used to evaluate the models. The outcomes show that the HMM performs better than the LSTM, with an RMSE of 1.21 and a MAPE of 12.98 demonstrating greater performance. Based on this result, the HMM is then used to forecast maize yield while taking the effects of temperature and rainfall into account. The estimates highlight the possibility for increasing local output by demonstrating a favourable environment for maize planting in Nigeria. In order to help the Nigerian government in its efforts to increase maize production domestically, these studies offer useful insights.
Hidden markov model; LSTM; Time series; Maize; Baum-welch algorithm
Maize (Zea mays L.) is a vital cereal crop in Africa and the developing world, including Nigeria, crucial for food security and poverty reduction. However, challenges such as low productivity and limited adoption of improved technologies hinder maize production in Nigeria [1]. Behind the so-called maize issue is a larger issue with the provision of staple foods, particularly in urban areas. The amount of locally produced staple food is not enough to satisfy demand given the technological state of rural and urban areas today and the pricing structure of basic food items. In order to satisfy local demand, a number of agricultural items exported before I960 have been imported in recent years. Maize, one of Nigeria’s most popular food crops is consumed by millions of Nigerians and is also used to make animal feed. On July 13th, 2020, the central bank of Nigeria directed all authorized dealers to stop processing Form M for maize importation with immediate effect. The unpredictable wealth conditions and the negative effect of the COVID-19 pandemic have been added to the unknown factors that as caused a shortfall in maize production. M. Yahaya and A. Lawal did a stochastic model for rice yield forecast employing the Hidden Markov Model (HMM) on data pertaining to Niger state. However, in most cases, the production is hidden or invisible, and each state randomly generates one out of every k observation that is visible [2]. However, the present literature did not compare the model used with another model with a dataset emanating from Niger state. Therefore, this study will demonstrate the comparative of the prediction of Hidden Markov Models (HMM) and Long Short-Term Memory Neural Networks (LSTM-NN) with yearly datasets of maize production cases general Nigeria, to provide necessary information to the government to boost maize production in Nigeria.
Hidden markov model
The Hidden Markov Model (HMM), first introduced in 1957, finds extensive applications in various industries such as management, engineering, medicine, signal processing, and production [3-5]. HMM is a discrete stochastic process (Xt,Yt)t≥o , composed of an underlying unobservable process(Xt) and an observed process (Yt) generating independent random observations. The components of an HMM include states, transitions, observations, and probabilistic behavior (Figure 1). The HMM's parameters(A,B,Π) , representing the state transition probability matrix, state emission probability matrix, and initial state probability matrix, fully describe its behavior [3,4].

Figure 1: Illustrates the graphical representation of a hidden Markov model, including hidden states, transition probabilities, observations, and emission probabilities [6].
Parameters of hidden markov model
Hidden Markov Model (HHM) is basically structured with the following parameters.
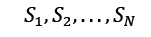
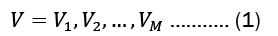
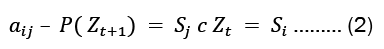
In a matrix, we frequently list the transition probabilities. The state transition matrix, also known as the transition probability matrix, is typically represented by P. The state transition matrix, if the states are is 1,2,.... r given by
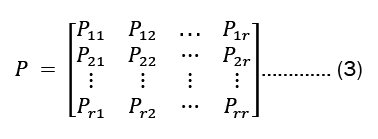
Note thatPi,≥0, and for all i, we have

• The observation likelihood or emission probability matrix (β) is a M x Nmatrix whose members 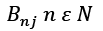 describe the likelihood of making an observation
describe the likelihood of making an observation 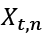 given a state
given a state 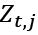 this could be expressed as
this could be expressed as
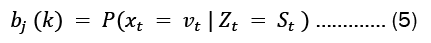
• An emission probability matrix of size (M + 2) × (N + 2) is given as
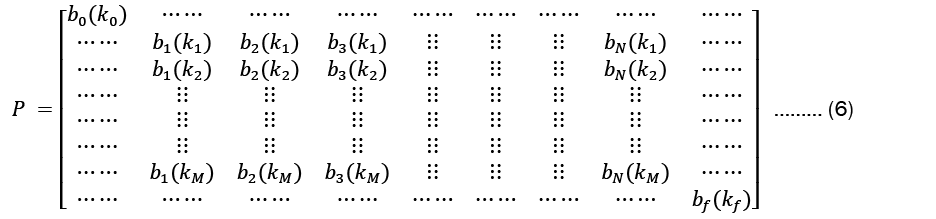
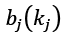 is the probability of emitting vocabulary item kj from state si:
is the probability of emitting vocabulary item kj from state si:
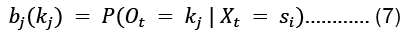
• Initial probability distributionΠ : This is a N x 1 vector of probabilities
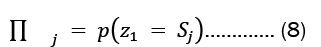
Solution to the likelihood problem
In order to solve the Likelihood problem, we determine the probability of an observation sequence X= x1,x2,x3 given a model, orP(x|λ). We took into account the state sequence Q= q1,q2,q3 where q1 and q3represent the beginning and final states, respectively. For our state sequence Q and a model ?, the probability of an observation n X series can be expressed as
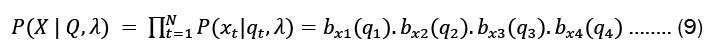
From the property of a Markov chain, we represented the probability of the state sequence as
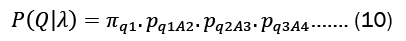
Summing over all possible state sequences is as follows:
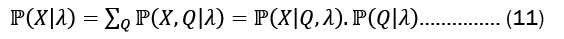
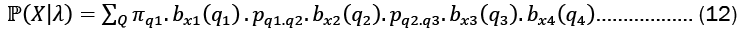
Forward algorithm
Using a forward variable, αt(i) which indicates the likelihood that, given the HMM model λ, a partial observation sequence will occur up to time t(i) and the underlying Markov process will be in the state T(i).
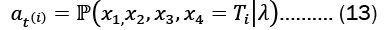
We compute αt(i) recursively via the following steps:
• Initialize the forward probability as a joint probability of state Ti and initial observation m1. Let α1(i)= πibi(πi) for 1≤i≥4
• Compute α3(i) for all states j at t= 3, using the induction procedure, substituting t=1,2,3:
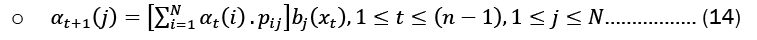
• Using the results from the preceding step, compute 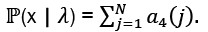
Backward algorithm
This research also constructs a backward variable for the forward algorithm βi(i), which indicates the likelihood of a partial observation sequence from time t+1 to the end (instead of up to t as in the forward method), where the Markov process is in state s1 at time t for a specific model, λ. The backward variable can be modeled mathematically as
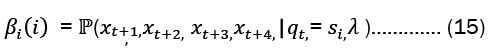
You can compute at(i) recursively via the following steps:
• Define βn(i)=1 for 1≤i≥N
• Compute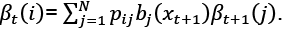
Solution to decoding problem
Viterbi algorithm says that to find the state that maximizes the conditional distribution of states given that data is provided a function µ it depends on the previous step, the transition probabilities and the emission probabilities.
The following equations represent the highest probability along a single path for first t observations which ends at state i .
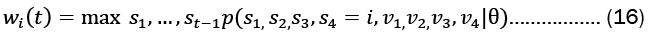
Using the same approach as the forward algorithm, we can calculate w(t+1)
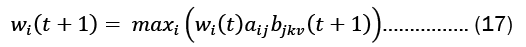
To find the sequence of the hidden states, we need to identify the state that maximizes w(t) at each time step t.
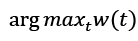
Solution to the learning problem
Baum-welch algorithm: The Baum-Welch Algorithm, also known as the forward-backward algorithm or the Expectation-Maximization (EM) Algorithm for Hidden Markov Models (HMMs), is used to estimate the unknown parameters of an HMM. The algorithm has two steps, the E-step and the M-step. These steps are:
1. Initialize A and B
2. Iterate until convergence.
E-Step:
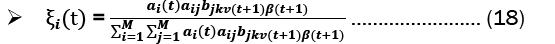
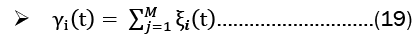
M-Step:
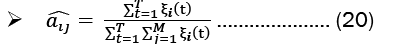
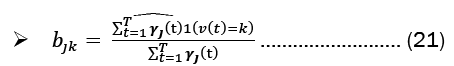
Long short-term memory
The Long Short-Term Memory (LSTM) is a Recurrent Neural Network (RNN) architecture designed to address the disappearing and exploding gradient problem. It uses memory cells, gates (input, output, and forget gates), and a hidden state to recognize long-term dependencies in sequential data. LSTMs are widely used in natural language processing, speech recognition, robotics, finance, and healthcare. A crucial component of LSTM is the "cell state", which preserves information over time. The gating mechanism, implemented using sigmoid functions, decides which data to ignore or retain based on the previous output and new input.
For each gate in the network, the learnable weights W (input weights), R (recurrent weights), and b (bias) are individually initialized as a column matrix, as given in Equation 22..
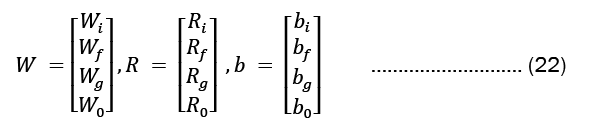
The cell state and concealed state at time ‘t’ are provided by Equation 23. The Hadamard product is represented by and is the state activation function-hyperbolic tangent function (tanh) respectively (element-wise multiplication).
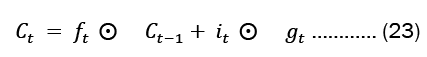
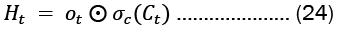
At each time step 't', Equation 23 illustrates the update process of values in the network. The activation function for the gates, denoted as 'g', is a sigmoid function.
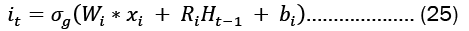
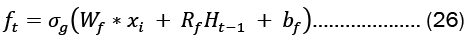
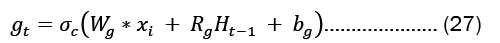
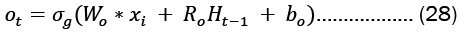
Gates in LSTMs control the addition and removal of information from the cell state. These gates may allow information to enter and exit the cell. It has a sigmoid neural network layer and a pointwise multiplication operation that help the mechanism [7,8].
This study information was obtained from the Nigeria index Mundi website and the central bank of Nigeria statistics database website on climate change and the production of maize. The factors taken into account were the annual temperatures, annual rainfall, and the annual production of maize in Nigeria from 1990 to 2022.
In this experiment, the performance of the models will be evaluated using some measures. The Hidden Markov Model (HMM) was then trained using the Forward-Backward Algorithm and then predicted the most likely states with Viterbi Algorithm and also forecasted using Baum Welch algorithm. The Long Short-Term Memory model (LSTM) was trained also using the means square error, the ADAM optimizer was used for the weight updates, and 200 epochs, where one epoch looped over all batches once. The best model due to their performance comparison was used to forecast.
In analyzing the result, we contrast the effectiveness of the Long Short-Term Model (LSTM) network and the Hidden Markov Model (HMM) technique. The datasets was partitioned so that we could train and test our models using 80% and 20% of the same data set.
Measures for the predictions of both models using various metrics are shown in the results reported in the following subsection. The values of the measures for both models are shown in Table 1.
| MAPE | RMSE | Corr | SEM | MSE | |
|---|---|---|---|---|---|
| HMM | 1.26 | 0.37 | -0.85 | 0.18 | 0.13 |
| LSTM | 12.98 | 1.21 | -0.85 | 4.19 | 0.87 |
Table 1. This table shows the values for all the measures for the prediction of both models.
According to the study's conclusions, HMM performed better than LSTM HMM had lower MAPE and RMSE values (1.26 and 0.37) compared to LSTM (12.98 and 1.21). HMM also had lower SEM and MSE values (0.18 and 0.87) compared to LSTM (4.19 and 0.87). The two models showed a negative correlation of -0.85.
LSTM training and evaluation analysis on maize production
The input layer passes the data onto the LSTM layer that has 200 nodes at the output. The output of the LSTM layer is passed onto a dense layer 1 (one) that has 200 nodes at its input. The dense layer 1 uses Mean Square Error (MSE) as the loss function and ADAM as the optimizer. The dense layer 1 is finally connected to the output layer that is also a fully-connected layer. From Table 2, the training loss is 0.7100, indicating reasonable performance on the training data.
| Hidden layer | Node or neurons | EPOCHS | Loss | Val_loss | Test accuracy |
|---|---|---|---|---|---|
| 1 | 32 | 200 | 0.71 | 0.1055 | 0.5813 |
Table 2. This table shows some parameters of the LSTM in training and evaluation.
The validation loss is 0.1055, lower than the training loss, indicating good generalization to new data. The test accuracy is 0.5813, suggesting poor performance on test data and limited generalization. In comparing the HMM with LSTM for predicting maize yield, the HMM outperforms LSTM. Therefore, the HMM model is used for future predictions.
Application of hidden markov model for maize yields forecast
Hidden Markov Models are thought of as an unsupervised learning process where just the observed symbols are visible and the number of hidden states is unknown. In order to anticipate future years, this section uses Nigeria's maize yield statistics and a Hidden Markov model. The summary of the data is presented in Table 3.
| Year | States | Observation |
|---|---|---|
| 1990 | 1 | M |
| 1991 | 3 | M |
| 1992 | 1 | M |
| 1993 | 1 | M |
| 1994 | 3 | M |
| 1995 | 1 | M |
| 1996 | 3 | M |
| 1997 | 3 | L |
| 1998 | 2 | L |
| 1999 | 3 | M |
| 2000 | 1 | L |
| 2001 | 1 | M |
| 2002 | 1 | M |
| 2003 | 3 | M |
| 2004 | 1 | M |
| 2005 | 2 | M |
| 2006 | 2 | M |
| 2007 | 2 | M |
| 2008 | 3 | M |
| 2009 | 2 | M |
| 2010 | 4 | M |
| 2011 | 2 | M |
| 2012 | 3 | M |
| 2013 | 2 | M |
| 2014 | 2 | H |
| 2015 | 1 | H |
| 2016 | 4 | H |
| 2017 | 4 | H |
| 2018 | 4 | H |
| 2019 | 1 | H |
| 2020 | 4 | H |
| 2021 | 4 | H |
Table 3. The states and observations of the hidden markov model for a period of thirty-two years.
Validity test for the model
In analyzing the result of the Hidden Markov Model (HMM) process, there is a need to determine the transition matrix. Thus, the data was entered into R and the following results were produced for the transition matrix for both temperature and rainfall (Figure 2).

Figure 2: Plot comparing the model to the actual data.
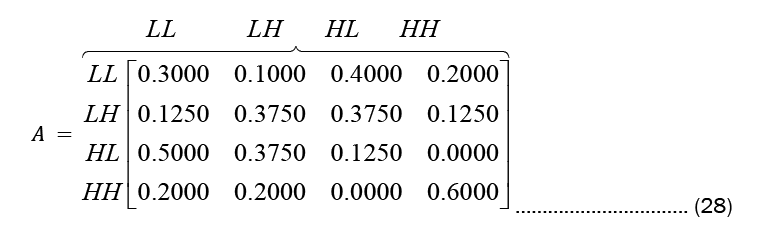
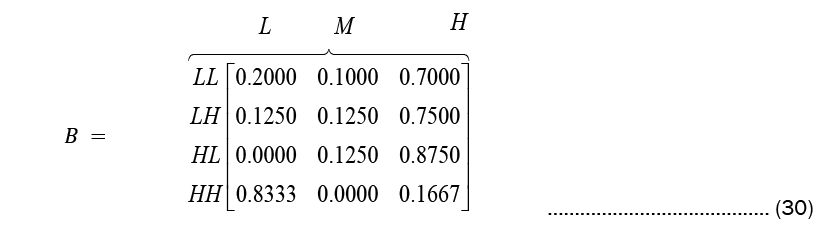
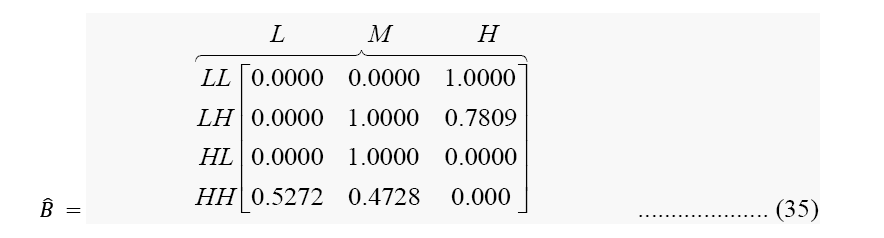
While Observation count matrix and Observation probability matrix or the emission probability matrix are given in Equations (29) and (30), respectively.
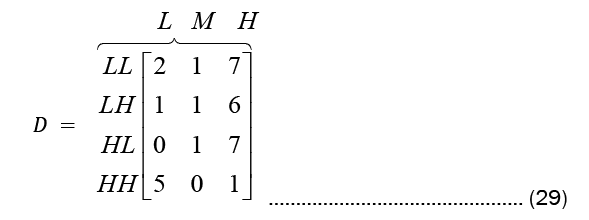
The initial state probability is given below
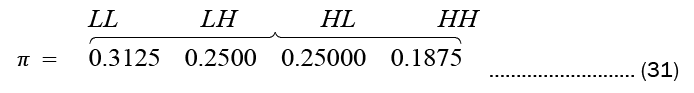
After 1000 iteration of Baum-Welch Algorithm, Equation (32) settled to (33)

Where
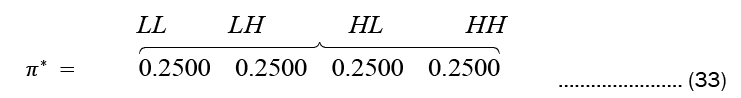
This π* shows the initialization process. The probabilities assigned is 0.2500 across the four (4) states.

Most likely states using viterbi algorithm
In finding the most likely states based on A and B estimates from the observed data, the following results were gotten employing the Viterbi Algorithm (Figure 3).
3 1 3 1 3 1 1 3 1 1 3 1 3 1 3 1 3 1

Figure 3: This plot shows that the hidden states are solely responsible for the observable factors.
Where state 1 is low rainfall and low temperature and state 3 is high rainfall and low temperature.
This shows that the hidden state (LL, LH, HL, HH) are 31.3% responsible for the observable factors of maize production (low, moderate, high).
Steady state
The likelihood that a Markov chain will remain in each state over the long run is its steady-state behavior. The initial probabilities are assumed to be equal for all states. The resulting steady state probabilities are:
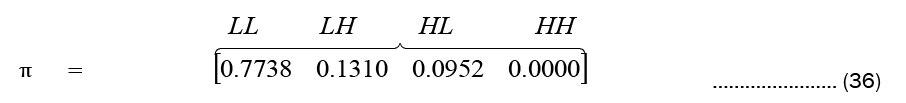
Which indicate that in the long run the system will be in state 1 about 77% of the time, in state 2 about 13% of the time in state 3 about 9% of the time, and in state 4 never. This is consistent with the prediction made below.
Hidden markov model for future forecast
HMM was developed to forecast maize yield for future years, the parameters of the HMM were determined utilizing rainfall, temperature and maize yield data from 1990 to 2021, at the point, we made forecast for 2022, 2023, 2024, and 2025 (Figure 4).

Figure 4: Future forecast states and observations.
Baum Welch algorithm,λ1 , settled to another model,λ2 , this new model was then used to make a forecast for future years. From the forecast, the HMM was in state 4 at time T (2021) emitting High rice maize, at that point, it then makes move to state 2 at time T+1 (2022) emitting High maize yield. Similar interpretation is given to move to state 2 at time T+2 (2023), move to state 2 at time T+3 (2024), move to state 2 at time T+4 (2025) all emitting High rice maize.
This experiment gives a quick overview of the HMM and LSTM, highlighting the salient features of stochastic modeling and deep learning for crop production. We also show the individual effectiveness of each model and the similarities between the HMM and LSTM using some multiple measures respectively. We discover from the measurement that there are some broad similarities, particularly at lower dimensionalities. We found out that HMM was the best model after checking their performances. Hidden Markov Model was then applied for future forecast on observed maize production data and use to develop a model which depicts sequences of observable factors given some hidden state and to estimate the predicted maize production in Nigeria. The stable state probabilities were estimated alongside the transition and emission probabilities. The hidden state showed to be 21.9% responsible for the variables which can be observed and the estimated model predicts a 31.3% chance that the observable factors are influenced by the hidden states. Given the results, the HMM is the higher performing model when predicting production of maize when comparing it with the LSTM. More than twice as low as the MAPE and RMSE of the LSTM forecast were the MAPE and RMSE of the HMM prediction. We say that the Hidden Markov Model is suitable for modelling maize production as it models either low production, moderate production and high production in Nigeria. It reveals the probability of changing from one state to another and the probability of emitting observations when in specific states.
[Crossref] [ Google Scholar]