Keywords
|
| Traffic Monitoring System; Dynamic-Background; DER; OOI; Occlusion Detection. |
INTRODUCTION
|
| Video processing is a key area in information processing domain. Application in video processing extends from satellite information gathering to object tracking. Working of Current traffic monitoring system is based on constant time. It needs a manual override by the cops in order to change the timing of the signal. During peak hours this system is a muddle for the travelers. So, a more automated traffic control system is needed to address this issue. The automated system should be able to make decisions on its own to direct the traffic load depending on some parameters. Processing the image obtained from the video dataset at the traffic signal will give useful interpretations of the state of that particular traffic lane. The proposed system is going to design a framework which helps in controlling the signal by detecting the objects present in a lane. In any processing of frames for object detection background modeling is a key factor. The background from which the incoming frames are subtracted is a key and in [2], [3], [6] this background image is either a static image or a universal background image. But, in the proposed system this background image is dynamically calculated by taking into consideration all the frames. The proposed system can be easily extended easily to objects other than vehicles also. |
| The primary objective of the proposed system is to find the number of objects present at a particular lane at a certain point in time. To efficiently detect the number of vehicles in a lane, first the static background in the frame has to be removed and the remaining objects have to be checked for occlusion. After occlusion detection each object has to be compared with the pre-defined data set to identify the presence of the vehicle. Each vehicle has a separate weight age depending upon its size and the type of vehicle. For places where even the background is not a static there should be a constant updating of the background images also and it should be compared with the incoming images to make the necessary changes. The system proposed finding its application in a traffic monitoring system, particularly in the threeway and four-way junctions where there should be a constant switching of the traffic lane after a certain point of time. Approach to this issue in this system is a general one and therefore any future enhancements can be made to extend this system to other object models especially pedestrian detection. Section II deals about the detailed literature study of the system. Section III talks about the analysis of the Object Detection system which deals about the individual process of detecting the objects which starts from a block separation algorithm, background modeling and ends with occlusion detection. Section IV and Section V talks about the detailed experimental design and the results of the system respectively. Finally, concluding remarks are given in Section VI. |
RELATED WORK
|
| Javier Marin et al. [4] propose a block based segmentation of the input data frame from which even minute information in the frame can be easily noticed. This block representation is particularly useful when objects are overlapping inside a same frame. In traffic monitoring system, chances are that a fast running vehicle may be missing from the frame when whole based classification is used. This occlusion detection is performed efficiently in this paper using block separation. This method also deals about handling partial occlusion for Human Detection in still images. The Random Subspace Method (RSM) is used for handling occlusion. This method has various advantages over the other methods. It does not require manual labeling of body parts, and also it does not require additional data like stereo and motion. The main advantage of this method is that it can be extended to other object classes too. In this method the window is described by a block based feature vector which includes the features of all the blocks. The resulting feature vector is evaluated by the holistic classifier. If the result from the holistic classifier is not clear, then the occlusion inference process is applied. |
| In the occlusion inference process, for each block a discrete label is obtained which determines whether it is part of the pedestrian or background. Then segmentation is applied to remove the spurious response and to obtain a spatially coherent region. After segmentation only the blocks which are having the same property are grouped together. If they are not having the same features their features are distributed everywhere depending upon the upper bound of the features. In order to apply this method to pedestrians, this system makes use of both linear SVMs and HOG descriptors, which have been proven to provide excellent results for this object class. In addition to HOG descriptor, they also test our system using the combination of the HOG and the local binary pattern (LBP) descriptor. |
| Shao-Yi Chien et al. [6] performed a comprehensive survey of Video object segmentation and tracking which are the key issues to be addressed in any smart surveillance system. This system addresses this issue by comparing the segmented image with that of the multi-background image. This multi-background image is formed in a multibackground registration process where each and every pixel of the background image is updated and released regularly. This is done by having a counter value, and a weight value for each pixel and the counter with the most hits is represented in the final multi-background image. |
| In the proposed threshold decision algorithm, the thresholds for segmentation can be robustly determined for dynamic background conditions without any user input. In addition, it is based on a mechanism that is different from per pixel background subtraction so as to prevent possible error propagations. Analysis of the results so obtained showed that the memory reduction rate is at least two-third when compared to previous works and it is therefore memory efficient. |
| For video object tracking, with the information from video object segmentation, the tracker is robust to background clutter. By using Diffusion distance (DD) for color histogram matching, a non-rigid moving object can be robustly tracked even under drastic changes in illumination. From a computational point of view, DD is also ideal as it is most suitable for parallel implementation and hardware realization. The disadvantage here is that more powerful post processing for the object masks, such as shadow and ghost region removal, should be further integrated into the object segmentation subsystem. Enzweiler et al. [1] Proposes a framework which involves a set of classifiers which are expertly trained on features derived from the values obtained in depth, intensity and motion of the frame. To handle partial occlusion, here expert weights are computed that shows the degree of visibility of the component. This degree of visibility of the object is determined by examining the boundaries the occluded objects are covered by, i.e. discontinuities in motion and depth. Occlusion based component weights allow focusing the combined decision of the mixture of- expert’s classifier on the non-occluded body parts. At the core of this framework are a set of expert classifiers that trained in depth, intensity and motion features and they depend on the particular component. Occlusions of individual body parts manifest in local depth- and motion discontinuities. In the phase of application, an algorithm for segmentation is applied to extract areas of coherent depth and motion. Based on the segmentation result, this system determines occlusion-dependent weights for our component-based expert classifiers to focus the combined decision on the visible parts of the pedestrian. But the primary disadvantage of this scheme is that manual labeling of parts is needed for processing. It also needs the usage of both stereo vision and motion information for effective identification of body parts. Gao et al. [3] Proposes the bounding box representation. This bounding box representation is computed by grouping all pixels inside a bounding box under the same category. This kind of assumption makes this system robust less to the object with occlusion. In this method, the system employs the bounding box with a pair of binary variables, each of which corresponds to a call indicating whether the pixels in the cell belong to the object. But, this same division of pixel in a pedestrian detection system cannot work as it is the traffic monitoring system since pixel cannot be captured when vehicles travel at the faster rate. The rich representation makes the detection more robust to occlusion and offers a richer output. The inference algorithm combining, graph-cut and branch-and-bound is novel and efficient. Finally, the globally coherent object model incorporates semantic information about the object spatial relationship by jointly inferring the relative depth ordering of multiple detections. |
| Caroline Lougier et al. [7] propose a matching technique based on shape is used to track the person’s silhouette along with the video sequence. The shape deformation is then normalized from these silhouettes based on shape analysis methods. Finally, falls are detected from normal activities by comparing with the silhouettes. This is done using a Gaussian mixture model. This paper is based on data collected from the realistic dataset with a set of daily activities and simulated actions. The results produced by this paper sounds good compared with other common image processing methods. This paper also suggested that the addition of edge points within the silhouette will improve the results. Edges can be sensitive to bad matching points; only those matching points which are reliable were kept for shape deformation assessment. The peak representing the fall is an important feature to characterize a fall here, but the lack of significative movement after the fall is also important for robustness when occlusions occur. A little motion after the fall will not significantly influence the human shape deformation. This paper was done with a realistic data set, and in spite of the low-quality images (high compression artifacts, noise) and segmentation difficulties (occlusions, shadows, moving objects, different clothes, and so on), the recognition results are excellent. |
| Jae Kyu Suhr et al. [8] offers a background subtraction method particularly for the Bayer-pattern image sequences. The proposed method uses a mixture of Gaussians (MoG) models the background sequence in the Bayer-pattern, domain and separates the foreground in an interpolated red, immature, and blue (RGB) domain. This method is efficient in a way it produces as accurate the result as it will be provided by processing RGB color images using MoG. The means and standard deviations of the individual distributions are taken into account for this purpose. Experimental results demonstrate that the proposed method is a full resolution to obtain high accuracy and low resource requirements simultaneously. This result so obtained is of at most important, particularlyin a low-level work such as background subtraction since it is accurate. It also has the potential to carry out high-level tasks, and additionally applicable in realtime embedded system tasks such as smart surveillance through the camera. |
| Nguyen. T. M. et al. [9] proposes a new model that incorporates spatial information into the Gaussian mixture model for image segmentation. This method is comparatively fast and easier to use than the other complex methods. This method applies the Expectation-Maximization (EM) algorithm directly to reduce the parameters used. The previous mixture models that have been used are not robust to noise and also very complex.In this paper, initially the spatial information between the pixels are obtained that is the parameter set areestimatedand the initial values are assigned in such a way to handle the noises and the parameter set is optimized by evaluating it with the log-likelihood. Once the parameters are obtained every pixel is assigned to a label that has a large posterior probability. The main drawback of this method is that it depends on initial starting since the EM algorithm is used, bad initialization can lead to bad results. |
| Tsung Han Tsai et al. [10] proposes a foreground detection method based on Human-Machine Interaction in the object level (HMIiOL) scheme. This method is a hardware-oriented foreground detection method. The HMIiol is used to partition the frame into various regions with the help of user knowledge and finds the object appearance constraint and object shape constraint for the regions. The threshold value is determined based on the object appearance constraint for each region. A processor is designed for the foreground detection and also for the human interaction. The architecture of the processor is made of data path of accelerators and a RISC processor. The accelerators using three level pixel pipelining structure for increasing the speed of background modelling. It performs 30% more than the similar designs. The main drawback is the cost since the hardware components are used, it is more costly to implement. |
| Here we propose a method for detecting objects which are obtained by finding the difference between the current frame and the Dynamic-Background. The Dynamic-Background is computed by taking into consideration pixel values of all pixels in all the frames. The Dynamic-Background is particularly useful when we have an ever changing background scene. The object detected is further processed to check for the occlusion in the object so that even minute information’s are recorded. This object detection system can be extended to other object classes also. |
PROPOSED ALGORITHM
|
| A. Proposed Outline: |
| The overview of the proposed system is shown in Fig. 1. This system presents a general outline for detecting objects. In the background modeling system, a multi-background registration (MBR) process as proposed by the Shao- Yi Chien et al. [6] is taken into consideration. MBR used here takes a universal background image into consideration from which a modified background image is obtained. But, in the current system we are using a Dynamic Background which computes the background image dynamically with the help of a count and weight values for all the pixels. In the occlusion handling using classifier, individual occlusion scores of each object detected in the previous system is calculated so that the presence of occlusion in objects can be predicted. |
| B. Block Separation: |
| There are various kinds of datasets that can be passed as the input. For training, various datasets are taken as input, datasets including traffic data with occlusion, traffic data without occlusion, pedestrian, non-pedestrian, both pedestrian and non-pedestrian. The dataset that is ready for processing are separated into various frames [f1, f2,…, fn] so that individual frames can be processed in video(V),where n is the number of frames. The frames are stored in a directory so that they can be retrieved whenever they are needed for processing. Each frame is taken from the directory and they were divided into smaller blocks. In this system, a frame is divided into four blocks to get more clear result and also to decrease the processing time. It is found that processing the images that are divided into smaller blocks reduces the processing time by almost half. Based on the requirement the number of blocks to be divided is decided. Each frame taken from the directory after getting separated into four blocks are stored in a directory for future processing. Blocks are stored in sequential order in four separate directories depending upon the part of the frame being processed.The blocks that are stored in the individual directories are used for the background modelling process. |
 |
| C. Background Modeling: |
| Blocks from the block separation are taken as input for Background Modelling process. All the blocks from individual parts directories are compared to eliminate the foreground and to obtain only the background image. Three important variables like count, weight, average are used in this process. For each and every pixel position of the block, count, weight, average values is computed. The frames are converted into gray scale for fast processing. Based on the range of intensity the count weight and average values are assigned. The count value for a particular range of intensities is assigned. In our process, we are labelling pixels into 13 different sections with the first 12 sections have a range of 20 pixel values and the last section having 16 pixel values (240,.., 255). The count value is incremented for every time a label is encountered in a pixel position. The count value denotes the number of times a pixel value in a particular position is repeated. The weight value is also calculated for every pixel position. The weight value denotes the cumulative addition of the intensities of the pixel positions in the particular range of intensities. The average value is to find out the average intensity from the range of intensities. It is computed by dividing weight by count for every range of intensities. After finding these values, the maximum count value is determined. Then, based on the maximum count value the corresponding average value is applied to the corresponding pixel position. |
 |
| By this way, the background image is obtained. The background image is stored in a directory. This step is repeated for the remaining 3 blocks and the corresponding background for all the blocks are obtained. Then these blocks are combined to form a complete frame. The Background Image (BI) obtained from the previous process is used to determine the object in the frame. The Current Frame (CF) is subtracted from the BI to compute the Background Difference (BD). The BD had so formed is the Object of Interest (OOI) which is used to take the count later. This is done by proceeding further to the final object test where score from the occlusion handling system compares to this score to identify the presence of the object. |
| D. Occlusion Handling using Classifier: |
| In general-purpose detection of occlusion regions is difficult and important because one-to-one correspondence of imaged scene points is needed for many tracking and video segmentation. If there is a partially occluded human figure in the frame sequence, we make use of a method similar to HOG-LBP. The response from a classifier can be perceived as ambiguous if it is close to 0. When the output is ambiguous, an occlusion inference process is applied. This is based on the responses obtained from the features computed in each block. The algorithm for the occlusion inference and the posterior reasoning is described in Occlusion Detection Algorithm. Javier Marin et al. [4] proposes an ensemble of local classifiers using a Random Subspace Classifier which is primarily based on blocks. It involves finding the random subset of individual blocks until t- different subsets are found. After finding this random space this subspace values are each trained by individual classifiers. This process of classifying using individual classifiers is very costly and it is not efficient. |
 |
| Normally, partial occlusions can vary considerably in terms of shape and size; In this proposed paper, once detected the foreground object from background modelling and frame difference, it will pass on to blob analysis stage. In this process, each and every frame blob has information about moving objects. |
 |
| Rather than using this classifiers a method which uses a fuzzy based approach which is based on choosing the threshold for a particular dataset. The number of variations in the frames object’s starting position and the ending positions are checked. This is done after the shadow pixels present in the frame are removed. Those columns whose continuity are less than (0.1* size of the column) are said to be shadows the remaining pixels are termed as object pixels. Among the object pixels the difference in the presence of first object pixel’s continuity and the next object pixel’s continuity is checked. If this difference is more than (.15 * size of the column) then the column is counted as a column with more than one object. Finally, for a frame the frame’s value of this count of the total number of columns with more than one object is taken into account for the final occlusion count. If this value is greater than 23% of the total number of columns, then the two objects present in the frame and if it is greater than 60% of the total number of columns then three objects present in the frame and this process goes on. Once we find all moving objects, and then extracted random space of object shape and other invariant features. These features will used for matching of object in incoming frame sequence. As a result of this matching process, the partial occlusion has been detected. |
EXPERIMENTAL DESIGN
|
| In this section, we outline the setup followed in our experiments. We describe in detail the different datasets used, as well as the procedure conducted during the training phases. Performance evaluation and comparison were conducted using 4 video sequences. As part of our validation we make use of four datasets with occlusion, partial occlusion and no occlusion. We also present a human dataset to prove the efficiency of our system detecting human objects. Description of the four different datasets that are used is given in Table 1. The datasets DS2 and DS3 are taken from the same place using a same camera, but at different points of time. The dataset DS2 is taken to ensure the system works well with noisy data. This dataset is taken when the road is overflowing with the rain water. But, in DS2 the traffic congestion is very small. To test the performance of the system during heavy traffic congestion DS3 is chosen. DS3 looks similar to DS2, but traffic congestion is 10 times heavier than DS2. The camera setup of DS2 and DS3 is on an elevated plane compared to that of other data sets. The elevated view of the camera is used to cover a larger view. The size of both DS2 and DS3 is 320*240 pixels. DS1 dataset does the same purpose as DS2, DS3 but it provides a frontal camera view. Both DS1, DS3 datasets have objects with occlusion and DS2 didn’t have occlusion since traffic congestion is less here. DS1 is about the same size as DS2, DS3 (320*240). DS4 is used to show the effects of using the same algorithm for human detection. It consists of a frame size of 180*144 much smaller than the other three datasets. The reason to experiment with the human detection dataset is to show how well the system works when extended for other types of dataset. This experimental setup is shown in a way such that it covers all different camera angles and all possible objects with and without occlusion. |
EXPERIMENTAL RESULTS
|
| In this section we describe the experimental results of our system. For measuring accuracy of the results, the following criteria are employed: |
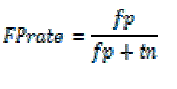 (1) (1) |
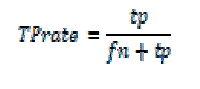 (2) (2) |
| Where tp, tn, fn, fp denotes the true positives, true negatives, false negative and false positives respectively. The results of TPP and FPP are shown for the per frame basis and per window basis in the Fig. 6. and Fig. 7. respectively. |
| a. Per Frame Analysis: |
| The results of FPPF and TPPF for all datasets are extracted by means of their blobs in the detected object. Per Frame evaluation employs a technique which takes the ratio of the number of informative pixels found per total number of pixels in a frame. The total size of pixels depends on the OOI used. Our results show that DS2 scores slightly better compared to that of another dataset sets since here traffic congestion is less and occluded objects are less. |
| b. Per Window Analysis: |
| Per window evaluation employs a scheme for detecting the amount of useful information present in the window to its original size. In our case, it’s the OOI. The window size may depend on the frame size of the dataset used. In our case the minimum window size is 250 pixels and the maximum window size is 3600 pixels. Experimental results show that the values for both false positive and True positive per window (Fig.7.) are slightly better compared to that of the previous False Positive and True Positive perFrame (Fig. 6.). This isbecause the ratio of presence of informative pixel position in a window is small compared to that of a frame. |
CONCLUSION AND FUTURE WORK
|
| In this paper, we present a general approach for detecting and counting objects, even in the presence of occlusion. The proposed paper also computes a dynamic background which is particularly useful in an ever-changing background scene. Dynamic background combines the working principle of the multi – background registration used in the previous system with an additional technique which takes into consideration all the frames to compute the dynamic background rather than a universal background as used in the latter. The proposed paper also provides the results of both the occluded dataset and non-occluded data set of traffic data and also a human detection data. Results show that the proposed system works better in computing the Dynamic background for both low and highly congested data set. Results also show that this system works better compared to the previous work in finding the False positive and True positive per frame and window (Fig.6. and Fig.7). The proposed framework works better in finding the human objects also therefore it can be extended to other object classes too. |
| |
Tables at a glance
|
 |
| Table 1 |
|
| |
Figures at a glance
|
 |
 |
 |
 |
| Figure 1 |
Figure 2 |
Figure 3 |
Figure 4 |
|
| |
References
|
- Enzweiler .B. S. M, Eigenstetter .A and Gavrila. D. M, “Multi-cue pedestrian classification with partial occlusion handling,” in Proc. CVPR, San Francisco, CA, USA, 2010, pp. 990–997.
- Andrews Sobral, Luciano Oliveira, LeizerSchnitman “Highway Traffic Congestion Classification Using Holistic Properties”, Dept. of Computer Science Federal University of Bahia Salvador, Bahia, Brazil
- Gao .T, Packer .B, and Koller .D, “A segmentation-aware object detection model with occlusion handling,” in Proc. CVPR, Colorado Springs, CO, USA, 2011, pp. 1361–1368.
- Javier Marín, David V´azquez, Antonio M. L´opez, JaumeAmores, and Ludmila I. Kuncheva, “Occlusion Handling via Random Subspace Classifiers for Human Detection”, 2012.
- Piotr Doll ´ ar, Christian Wojek, BerntSchiele, and PietroPerona, “Pedestrian Detection, An Evaluation of the State of the Art”, June 2013.
- Shao-Yi Chien, Wei-Kai Chan, Yu-Hsiang Tseng, and HongYuhChen,”Video Object Segmentation and Tracking Framework WithImproved Threshold Decision and Diffusion Distance”, June 2013.
- Caroline Rougier, Jean Meunier, Alain St-Arnaud, and Jacqueline Rousseau,“Robust Video Surveillance for Fall Detection Based on Human Shape Deformation” in May 2011.
- Jae Kyu Suhr, Ho Gi Jung, Gen Li, Jaihie Kim, “Mixture of Gaussians-Based Background Subtraction for Bayer-Pattern Image Sequences” in March 2011.
- Nguyen. T. M,”Fast and Robust Spatially Constrained Gaussian Mixture Model for Image Segmentation” in April 2013.
- Tsung Han Tsai, “Algorithm and Architecture Design of Human–Machine Interaction in Foreground Object Detection With Dynamic Scene” in January 2013.
|