Keywords
|
| character recognition; feature extraction; classifier; ANN; OCR; neural network; pre-processing; segmentation; training |
INTRODUCTION
|
| Isolated handwritten character recognition has been the subject of intensive research during last decades because it is useful in wide range of real world problems. An isolated character is drawn in an isolated form when it is written alone and is drawn in three other forms when it is written connected to other characters in the word. There are two types of character recognition systems “on-line and off-line" systems [7]. Each system has its own algorithms and methods. The main difference between them is that in an on-line system the recognition is performed in time of writing while the off-line recognition is performed after the writing is completed. On-line systems for handwriting recognition are available in hand-held computers such as PDAs with acceptable performance. Off-line systems are less accurate than on-line systems due to their less informative data capturing device, which is usually the scanner.. However, they are now good enough that they have a significant economic impact in specialized domains such as interpreting handwritten postal addresses on envelopes and reading courtesy amounts on bank cheques. The ultimate goal of isolated character recognition is to simulate the human reading capabilities. Character recognition system can improve the interaction between man and machine in many applications [1] [2]. Some classifiers were based on neuronal networks [3] [4], on hidden Markov models [6], on affixed approach or the K-nearest neighbours [5]. The feature extraction method zoning, is used for extracting features of the character under consideration in this problem. In zoning method, the frame containing the character is divided into several overlapping or non-overlapping zones and the densities of object pixels in each zone are calculated. Densities are used to form a representation. The final, classification stage is the main decision making stage of the recognition system. It uses features extracted in the feature extraction stage to identify the character. K-Nearest Neighbor and Support Vector Machine are the two classifiers used for identifying the character in the problem. |
| Comparing the achievements of various researches in this field is quite difficult as the databases and general approaches might differ. Testing done with different databases would give results as variations and complexity of the data in the databases are not the same. Similar issues are also with approaches. Approaches would differ in recognition of characters, digits, words, cursive, and non-cursive, with or without post-processing. |
LITERATURE SURVEY
|
| Various researchers have worked the field of character recognition using various methods. A few are discussed as follows. George Nagy, Thomas A. Nartker [1] Focused their research work on the basis of diversity of errors which occur while the recognition and fetching of characters out of an image . Further more they briefly state that On the basis of the diversity of errors that they have encountered, we are inclined to believe that further progress in OCR is more likely to be the result of multiple combinations of techniques than on the discovery of any single new overarching principle. Their contribution in this arena is remarkable. Vijay Laxmi and Babita Kubde[7] Proposed a fast and easy method to use Feature Extraction for good performance, focussing on isolated characters. Diagnol feature extraction scheme is proposed in it for bringing accuracy and better results. Shashank Araokar [3] Focused their work on establishing the neural network (artificial) in the contrast of classification of the image . An artificial neural network is consisted of hidden layer and input and output layer. The proper training method helps the neural network for the classification at the time of testing. Net. train method is the remarkable method added in the simulator of MATLAB which requires a training set and a target set. . Holger Schwenk and Yoshua Benjio[6] Proposed a boosting algorithm AdaBoost, that has been applied with great success to several benchmark machine learning problems. In particular it is used to automatically learn a variety of learning styles when the amount of training data for each style varies alot. . Ankit Sharma and Dipti R. Chaudary[5] Provided a useful method for the recognition of handwritten characters to a great extent. The proposed method has been applied on different unknown characters. Neural network based method gives the accuracy 85 %. Developed Proposed algorithms cannot be applied to recognize a cursive handwriting Recognition. . Vivek Shrivastava and Navdeep Sharma [2] Presented their work mainly focused on the feature extraction of the image. They briefly state that, feature extraction is a very important step in order to make a successful classification of the image. Their statement towards this work is quite absolute as the features saved in the database decide what exactly is going to be the output of the classification. |
SEGMENTATION AND RECOGNITION OF ISOLATED CHARACTERS
|
| A. Registration of reference image |
| First of all, all the feature points are detected from the reference images, and the positions of them are registered. The information of the position is represented by voting vectors as shown in Figure 1. |
| Let the origin be the upper left corner of the reference image. Let N(k) i be the number of occurrences of i-th feature in the reference image of character k. let (xij,yij) be the coordinate of j-th occurrence of i-th feature in the character k. The voting vector is defined as |
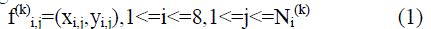 |
| Furthermore, the total number of occurrences of eight features in the reference image of character k is defined. At first, all the feature points are detected from the input image. Then, characters are detected by voting. At the same time, category of the character and its location are determined by voting at the voting point. In short, the voting point is a candidate of the upper left corner of a character image as shown in figure 2. To allow deformations of a character image, the neighbours of the voting point are also voted. |
| At first, all the feature points are detected from the input image. Then, characters are detected by voting. At the same time, category of the character and its location are determined by voting at the voting point. In short, the voting point is a candidate of the upper left corner of a character image as shown in figure 2. To allow deformations of a character image, the neighbours of the voting point are also voted. |
| Let v(k)ij (x, y) be the voting value, which stands for the voting value of character k at (x, y) of the input image. In advance, it is initialized as v(k)ij (x, y) = 0 for all (x, y) and all k. The neighbors within r pixels distance from the voting point are determined. |
| After the voting, voting values are summed. |
| V (k)(x, y) stands for the possibility that the upper left corner of the character image of category k exists at (x, y). Let T2 be the threshold of character segmentation where0 ≤ T2 ≤ 1. |
OPTICAL CHARACTER RECOGNITION
|
| Optical character recognition, abbreviated as OCR, is the process of converting the images of isolated characters, typewritten or printed text (usually captured by a scanner) into machine editable text or computer process able format, such as ASCII code. Computer systems armed with OCR system improve the speed of input operations, reduce data entry errors, reduce storage space required by paper documents and thus enable compact storage, fast retrieval, scanning corrections and other file manipulations. OCR have applications in postal code recognition, automatic data entry into large administrative systems, banking, automatic cartography, 3D object recognition, digital libraries, invoice and receipt processing, reading devices for blind and personal digital assistants. OCR includes essential problems of pattern recognition. Accuracy, flexibility and speed are the three main features that characterize a good OCR system. OCR aims at enabling computers to recognize optical symbols without human intervention. This is accomplished by searching a match between the features extracted from a given symbol’s image and the library of image models. The basic process of OCR Systems is shown in Figure3. |
| The process of optical character recognition of any script can be broadly broken down into 6 stages as shown in Figure 3. |
| Basic steps of OCR: |
| i. Digitization: Digitization produces the digital image, which is fed to the pre-processing phase. |
| ii. Preprocessing: The image produced by digitization may carry some unwanted noise. The preprocessing stage takes in a raw image, reduces noise and distortion, removes skewness and performs skeltonizing of the image. After preprocessing phase, we have a cleaned image which goes to the segmentation phase. |
| iii. Segmentation: The segmentation stage takes in the image and separates the different logical parts, like lines of a paragraph, words of line and characters of a word. |
| iv. Feature Extraction: After segmentation, set of features is required for each character. In feature extraction stage every character is assigned a feature vector to identify it. This vector is used to distinguish the character from other characters. Various feature extraction methods are designed like zoning, PCA, Central moments, structural features, Gabor filters and Directional Distance Distribution. Feature extraction is the process of selection of the type and the set of features. |
| v. Classification: Classification is the main decision making stage of OCR system. It uses the features extracted in the previous stage to identify the text segment according to preset rules. Many type of classifiers are applicable to OCR like K-nearest neighbour, Neocognitrons and SVM. |
| vi. Post processing: The output of classification may contain some recognition errors. Post-processing methods remove these errors by making use of mostly two methods namely, dictionary lookup and statistical approach. |
GENERAL STEPS OF ISOLATED CHARACTER RECOGNITION
|
| Fuzzy logic was first developed by Lotfi Zadeh [8]. It was developed for solving decision making problems with „IF-THEN? rules later, it was used to deal with uncertainly and imprecise data management. . For several years fuzzy logic has been applied in different filed, such as automated control ,consumer products, [9] industrial systems, automotives, decision analysis, medicine, geology ,controlling aircraft flight, chemical reactor and processes and applications of artificial intelligence such as expert systems ,pattern recognition and robotics. Fuzzy logic is much more general than binary logical systems. The generality of fuzzy logic is needed to deal with complex problems in the realms of search. Fuzzy logic provides a foundation for the development of new tools for dealing with natural languages and knowledge representation. Such as precipitated natural language, theory of hierarchical definability, unified theory of uncertainty [10]. Its advantages not much different than the binary logic, except the binary Logic working on only two levels ((0,1) but the fuzzy Logic treat with hypotheses to be correct confirm the degree of reality between (0,1) The real values of the assumptions indicate the degree of emphasis on the premise that is correct. Fuzzy logic easy way to reach definitive conclusions based on vague, and ambiguous and imprecise and noise, therefore, it makes sense to control the individual to take a quick decision [11] [12]. There are many motives that prompted scientists to develop fuzzy logic with the development of computer software and created a desire to invent or programming systems could deal with the information of others as human minute but this problem was born as the computer cannot deal only with specific and accurate information, has resulted in this trend known as expert systems and artificial intelligence, fuzzy logic is one theory in which to build these systems. There are many concepts of fuzzy logic such as fuzzy set theory, fuzzy logic operations (complement operation, union operations and the intersection operation) these operations can be also applied on binary sets [13]. |
CONCLUSION
|
| Isolated character recognition has been the subject of intensive research during last decades because it is useful in wide range of real world problems. The fuzzy logic implementation uses very little memory, making it possible to provide full functionality. The explosion of information technology has helped a rapid growth in the area of OCR. Complex algorithms for isolated character recognition systems were developed. With powerful computers and more accurate electronic equipments, efficient and modern use of methodologies such as neural networks (NNs), hidden Markov models (HMM), fuzzy set reasoning and natural language processing are possible. There is, however, still a long way to go in order to reach the ultimate goal of machine simulation of fluent human reading, especially for unconstrained on-line and off-line handwriting. Research in the area are extensive many more can be done at not necessarily in improving the percentage of accuracy but also at attempting to reduce complexity of its pre-processing techniques, its classifier, its post-processing and also the need for huge databases for trainings. |
Figures at a glance
|
 |
 |
 |
 |
| Figure 1 |
Figure 2 |
Figure 3 |
Figure 4 |
|
References
|
- Abdel wahabzramdini, Rolf ingold, “ Optical Font recognition from projection profiles,” Electroic publishing, Vol 6, 1993.
- Ahmed M. Zeki and Mohamad S. Zakaria, 2004, ”Challenges in Recognizing Arabic Characters” International Islamic Universityalaysia(IIUM),Kuala Lumpur .Malaysia).
- BrigetteKrantz, A "Crisp, “ Introduction to Fuzzy Logic, Colorado University”.
- Chen, G., Pham T., 2001, “Introduction to fuzzy sets, fuzzy logic, and fuzzy control systems,”.
- H.AL-Yousefi , S. S.Udpa, “Recognition of Arabic Characters”, IEEE Transactions on pattern analysis and Machine Intelligence, Vol.14.
- Korsheed, M. S. 2002, “Offline Arabic character recognition –review, “ Pattern Anal.Appl.5.
- Lorigo, L., Govindaraju, V., “Offline Arabic handwriting recognition: A survey,” IEEE Trans.on Pattern Anal. Machine Intell. 28, 2006.
- Majida Ali Abed, Hamid Ali Abed, “Fuzzy Logic approach to Recognition of Isolated Arabic Characters,” International Journal ofComputer Theory and Engineering, Vol. 2, No. 1 February, 2010 1793-8201pp.9-17.
- Margner, V., Pechwitz, M, “Arabic handwriting recognition competition,” The8th International Conference on Document Analysis andRecognition,vol.1, ICDAR 2005.
- Mohammed Abdel-Hadi, Ibrahim al-Hamdi, “Fuzzy logic in the decision-making", Arab Journal of Administrative Sciences Vol. 6,Kuwait. 1999.
- Ruspini, E., 1992, “Introductio n to Fuzzy set theory basic concepts And structures”, IEEE.
- Zadeh ,Lotfi A. 2004 , “Fuzzy logics systems: origin concepts ,and trends).
- Zadeh ,Lotfi A. ,1998 , “Fuzzy logic Computer ”, vol 22, issue 4.
|