KEYWORDS
|
| Ontology Model, Personalization, World Knowledge, User profile, Local Instance Repository, Web Information Congregation. |
INTRODUCTION
|
| The huge amount of web information available has increased dramatically. How to gather useful information from the web has become a challenging issue for users. Current web information gathering systems attempt to satisfy user requirements by capturing their information needs. For this purpose, user profiles are created for user background knowledge description User profiles represent the concept models possessed by users when gathering web information. A concept model is implicitly possessed by users and is generated from their background knowledge. While this concept model cannot be proven in laboratories, many web ontologists have observed it in user behavior. When users read through a document, they can easily determine whether or not it is of their interest or relevance to them, a judgment that arises from their implicit concept models. If a user’s concept model can be simulated, then a superior representation of user profiles can be built. To simulate user concept models, ontology a knowledge description and formalization model are utilized in personalized web information gathering. |
| This paper shows different problems, techniques and proposed model also future work shows working of five different authors on ontology. The main work of ontology is to gather web information based on keywords that may be local or global repository. |
OBJECTIVE AND MOTIVATION
|
| An ontology model simulates users’ concept models by using personalized ontologies, and attempts to improve web information gathering performance by using ontological user profiles. The world knowledge and a user’s local instance repository (LIR) are used in the proposed model. World knowledge is commonsense knowledge acquired by people from experience and education; an LIR is a user’s personal collection of information items. From a world knowledge base, we construct personalized ontologies by adopting user feedback on interesting knowledge. The users’ LIRs are then used to discover background knowledge and to populate the personalized ontologies. The proposed ontology model is evaluated by comparison against some standard models through experiments using a large standard data set. |
| This paper presents the extensive work of, but significantly beyond, an earlier paper published in 2013. The primary motivation of the work in ontology is to gather web information based on keywords that may be large open information spaces and Navigation and search related problems. It can be find out the many (irrelevant) search results based on the keywords of web-information gathering systems. The ontology model is evaluated by comparing it against standard solutions models in web information gathering |
LITERATURE REVIEW
|
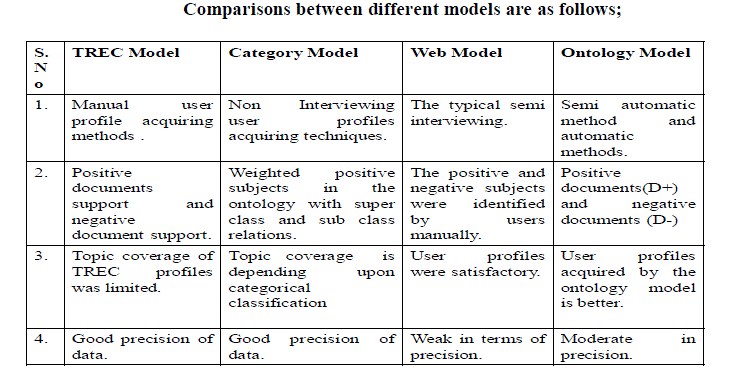
| A study of some the existing methodology is done and the results are tabulated. The methodologies and techniques existing until the current year have been considered and studied. The methodologies and the complete information of the approaches indicating whether they used a manual approach or automatic approach or semi automatic approach is done. A total number of 5 different research paper and different techniques, methodologies have been studied. |
 |
EXISTING SYSTEM
|
| An user profiles represent the concept models possessed by users when gathering web information. A concept model is implicitly possessed by users and is generated from their background knowledge. While this concept model cannot be proven in laboratories, many web ontologists have observed it in user behavior. When users read through a document, they can easily determine whether or not it is of their interest or relevance to them, a judgment that arises from their implicit concept models. If a user’s concept model can be simulated, then a superior representation of user profiles can be built. |
| The TREC model (Text REtrieval Conference) was used to demonstrate the interviewing user profiles, which reflected user concept models perfectly. For each topic, TREC users were given a set of documents to read and judged each as relevant or non-relevant to the topic. Category model is demonstrated by using non-interviewing user profiles that are it do not involve user at all in particular model. The web model was the implementation of typical semi interviewing user profiles. It acquired user profiles from the web by employing a web search engine. |
Highlights of Existing System
|
| • TREC Model (Text REtrieval Conference) is the topic coverage was limited. |
| • Poor performance |
| • Web information has noise and uncertainties |
| • As a result user profiles were weak in terms of preci |
 |
PROPOSED SYSTEM
|
| An ontology model simulates user’s concept models by using personalized ontologies and attempts to improve web information gathering performance by using ontological user profiles. The world knowledge and a user’s local instance repository (LIR) are used in the proposed model. World knowledge is commonsense knowledge acquired by people from experience and education. An LIR is a user’s personal collection of information items. From a world knowledge base, we construct personalized ontologies by adopting user feedback on interesting knowledge. A multidimensional ontology mining method, Specificity and Exhaustivity, is also introduced in the proposed model for analyzing concepts specified in ontologies. The users’ LIRs are then used to discover background knowledge and to populate the personalized ontologies. The proposed ontology model is evaluated by comparison against some benchmark models through experiments using a large standard data set. The evaluation results show that the proposed ontology model is successful. |
Highlights of Proposed System:
|
| • Every user has a distinct background and a specific goal when searching for information on the Web. |
| • The goal of Web search personalization is to tailor search results to a particular user based on that user's interests and preferences. |
| • Effective personalization of information access involves two important challenges: |
| i) An accurately identifying the user context |
| ii) An organizing the information in such a way that matches the particular contexts |
| • Scope to work on local repositories that can match to global repos |
| • For easily data gathering for single computational model and use global and local repositories at a time. |
| • Increase system performance |
| • Use searching techniques-i) keyword based searching techniques ii)content based searching techniques in single model. |
| • We will investigate the methods that generate user local instance repositories to match the representation of a global knowledge base. |
| • The present work assumes that all user local instance repositories have content-based descriptors referring to the subjects. |
| • A large volume of documents existing on the web may not have such content-based descriptors |
| • Ontology mapping and text classification/clustering were suggested. These strategies will be investigated in future work to solve this problem. |
CONCLUSION AND FUTURE WORK
|
| In this paper, we study on a personalized ontology model for web information gathering based on the searching techniques such as keyword based and context based information. Moreover, the Ontology model to constructs user personalized ontology’s by extracting world knowledge base from user background knowledge based on the experience and education background. In this paper, we study on a personalized ontology model for web information gathering based on the searching techniques such as keyword based and context based information. Moreover, the Ontology model to constructs user personalized ontology’s by extracting world knowledge base from user background knowledge based on the experience and education background. The finding in this paper can be applied to the design of web information gathering. |
| An ontology model provides a solution to emphasizing global and local knowledge in a single computational model. The findings in this project can be applied to the design of web information gathering systems. Ontology techniques, clustering, and classification in particular, can help to establish the reference, as in the work conducted. The clustering techniques group the documents into unsupervised clusters based on the document features. These features, usually represented by terms, can be extracted from the clusters. They represent the user background knowledge discovered from the user. The model also has extensive approach to the field of Information Retrieval, Information Extraction and Web information gathering System. |
References
|
- Jaya Jacob and V.Seethalakshmi, “Performance Evaluation of Various Routing Protocols in MANET”, International Journal of EngineeringSciences, Dec. 2011, Vol. 5.
- R.Wattenhofer, L.Li,P.Bahl,andY.M.Wang,“Distributed topology control for power efficient operation in multi hop wireless ad hoc networks”,INFOCOM 2001, Twentieth Annual Joint Conference of the IEEE Computer and Communications Societies, Proceedings,Volume: 3.
- Chen Jie,ChenJiapin,and Li Zhenbo, “Energy-Efficient AODV for Low Mobility Ad Hoc Networks”, International Conference on WirelessCommunications, Networking and Mobile Computing, WiCom 2007.
- B.Karp and H.T. Kung, “GPSR: Greedy Perimeter Stateless Routing for Wireless Networks,” Proc. ACM MobiCom, pp. 243-254, Aug. 2000.
- Q.Chen, S.S.Kanhere, M. Hassan, and K.C.Lan, “Adaptive Position Update in Geographic Routing”, IEEE International Conference onCommunications (ICC ’06), pp. 4046-4051, June 2006.
- J.Li, J.Jannotti, D.S.J.D. Couto, D.R. Karger and R.Morris, “A Scalable Location Service for Geographic Ad Hoc Routing”, in Proc.ACMMobiCom,pp. 120-130, aug.2000.
- Z.J.Haas and B.Liang, “Ad Hoc Mobility Management with Uniform Quorum Systems”, IEEE/ACM Transactions on Networking, vol. 7, no. 2, pp.228-40, Apr. 1999.
- J.Hightower and G.Borriello, “Location Systems for Ubiquitous Computing”, IEEE Computer, vol. 34, no. 8, August 2001, pp. 57-66.
- Akhilesh.A.Waoo, Dr.P.S.Patheja, Dr. Sanjay Sharma, and TriptiNema, “QoS Routing Algorithm with Sleep Mode in MANETs”, Journal ofComputer Networks, 2013, Vol. 1, No. 1, 10-14.
- C.Perkins, E.Belding- Royer, S.Dasandquet, “Ad Hoc On-Demand Distance Vector (AODV) Routing”, IETF Draft, June 2002.
- V.Kanakaris, D.Ndzi and D.Azzi., “Ad-hoc Networks Energy Consumption: A review of the Ad-Hoc Routing Protocols”, Journal of EngineeringScience and Technology Review 3 (1) (July 2010).
- JieWu and Ivan Stojmenovic, “Ad Hoc Networks”, IEEE computer society, feb 2004.
- Xin Ming Zhang, Feng Fu Zou, En Bo Wang and Dan Keun Sung, “Exploring the Dynamic Nature of Mobile Nodes for Predicting Route Lifetimein Mobile Ad Hoc Networks”, IEEE transactions on vehicular technology, vol. 59, no. 3, march 2010.
- D.Johnson and D.Maltz, “Dynamic source routing in ad hoc wireless networks,” in Mobile Computing, the Kluwer International Series inEngineering and Computer Science Volume 353, pp 153-18, 1996.
- M.Mauve, J.Widmer and H.Hartenstein, “A Survey on Position Based Routing in MobileAd-hoc Networks”, IEEE Network Magazine, 15(6):30–39,November 2001.
|